一种文本信息情感判定方法和判定装置与流程
本发明涉及语义识别技术领域,具体涉及一种文本信息情感判定方法和判定装置。
背景技术:
用户在互联网各平台发表的评论、原创博文等文本信息,反映了用户对于某个事件的持有态度或者对某个品牌产品的主观评价,这些信息可用于发掘用户的兴趣特征和行为模式,进行更加精确的舆情分析,从而实现个性化的精准营销。
目前,对于实现文本信息情感分析的方法主要有两大类。一类是基于规则与统计的方法,主要是结合情感词典与句式结构,但情感词典和文本信息不规整句式结构的准确构建是技术难点。另一类则是将文本向量化表示,然后结合机器学习的分类算法,将情感差异作为一个文本分类的任务来完成。现有文本分类技术中针对情感分析大多只给出了两类极性的情感判定,即仅有正面和负面的情感,这对于舆情分析分类是不充分的。而利用过多的的情感分类类别不仅会加重情感分析的文本标注成本,而且产生不出更高的分析价值,反而误差率会更高。
技术实现要素:
鉴于上述问题,本发明实施例提供一种文本信息情感判定方法和判定装置,解决现有情感分析方法对丰富情感缺乏可衡量评价的技术问题。
本发明实施例的文本信息情感判定方法,包括:
利用基于情感倾向分类的朴素贝叶斯分类过程获取待判定文本的情感倾向概率。
本发明一实施例中,所述基于情感倾向分类的朴素贝叶斯分类过程的形成包括:
对源数据进行文本预处理形成源数据文本;
在所述源数据文本中抽取形成采样数据文本;
对所述采样数据文本进行倾向标注形成情感倾向类别和对应采样数据文本集合;
对所述采样数据文本进行文本特征提取,根据所述文本特征形成训练样本集;
通过所述训练样本集形成朴素贝叶斯分类过程中所述情感倾向类别在训练样本中的出现频率以及每个文本特征对每个情感倾向的条件概率估计。
本发明一实施例中,所述情感倾向类别包括正面、负面和中性。
本发明一实施例中,所述源数据至少来源于电商平台、微博平台和微信平台中的一个平台。
本发明一实施例中,所述对源数据进行文本预处理至少包括以下一种处理方式:
针对时间信息,进行删除处理;
针对链接信息,进行删除处理;
针对话题和/或主题信息,进行删除处理;
针对转发微博信息,仅保留当前用户发布微博内容;
针对用户名和/或用户昵称,进行删除处理;
针对特殊符号,进行删除处理;
针对表情符号,进行正则表达式匹配,替换为所述正则表达式对应的标准文本。
本发明一实施例中,所述在所述源数据文本中抽取采用随机抽取方式。
本发明一实施例中,所述在所述对所述采样数据文本进行文本特征提取包括:
采用词袋模型筛选出所述采样数据文本的高热度词汇;
采用tf-idf算法计算每个所述高热度词汇权值;
根据所述高热度词汇权值确定文本特征向量。
本发明一实施例中,所述获取待判定文本的情感倾向概率包括:
获取所述待判定文本的文本特征;
通过所述基于情感倾向分类的朴素贝叶斯分类过程对所述待判定文本的文本特征进行分类概率比较获得所述待判定文本的情感倾向概率。
本发明一实施例中,还包括:
根据所述情感倾向概率设置情感倾向分段阈值,根据待判定文本的情感倾向概率确定情绪类型。
本发明一实施例中,所述设置情感倾向分段阈值包括:
所述情感倾向分段阈值根据在行业领域内对情感倾向校验获得的正确率和召回率确定。
本发明一实施例中,还包括:
根据行业属性对所述待判定文本进行拆分形成文本段落,利用所述基于情感倾向分类的朴素贝叶斯分类过程为所述文本段落判定情感倾向概率。
本发明一实施例中,所述行业属性根据所述待判定文本中的行业属性特征关键字识别。
本发明一实施例中,所述行业特征关键字的形成过程包括:
对数据来源中的行业内容进行分词形成语料;
对所述语料清洗后停用行业领域内基础名词;
选取名词语料进行词频统计,对高频词进行有效性过滤形成所述行业特征关键字。
本发明一实施例中,所述根据行业属性对所述待判定文本进行拆分形成文本段落包括:
根据行业特征关键字和分隔符将待判定文本断句形成与行业属性对应的文本段落。
本发明一实施例中,所述为所述文本段落判定情感倾向概率包括:
将所述待判定文本的情感倾向概率与所述待判定文本中所述文本段落的情感倾向概率形成映射关联。
本发明实施例的文本信息情感判定装置,包括:
存储器,用于存储上述的文本信息情感判定方法处理过程的程序代码;
处理器,用于执行所述程序代码。
本发明实施例的文本信息情感判定装置,包括:
朴素贝叶斯分类判定模块,用于利用基于情感倾向分类的朴素贝叶斯分类过程获取待判定文本的情感倾向概率。
本发明一实施例中,还包括:
情感倾向划分模块,用于根据所述情感倾向概率设置情感倾向分段阈值,根据待判定文本的情感倾向概率确定情绪类型。
本发明一实施例中,还包括:
文本属性区分模块,用于根据行业属性对所述待判定文本进行拆分形成文本段落,利用所述基于情感倾向分类的朴素贝叶斯分类过程为所述文本段落判定情感倾向概率。
本发明实施例的文本信息情感判定方法和判定装置利用情感倾向分类体现非特定情感类型的定性趋势,不直接反应情感类型,避免了分类模型的精细分析缺陷和对行业数据分析的局限性。可以针对行业数据提供情感分析结果,不仅可以给出情感判定结果,而且允许使用者根据自我需求进行数据修正,同时,对于存在多属性的文本,给出了针对每一个属性的情感判断结果,相较于纯原文本直接判断情感,可更加精确的给出用户的真正意见,同时基于不同的属性,使用者可完成一些定制化精准分析。
本发明实施例的文本信息情感判定方法和判定装置适于较宽泛的数据源数据尺度,在形成情感倾向概率时同时可以确定相应的文本特征和相对情感倾向分类的概率估计。对于综合不同数据源、利用待判定文本形成增量训练样本改善用户评论的情感判定精度更具有技术优势。
附图说明
图1所示为本发明一实施例文本信息情感判定方法的流程示意图。
图2所示为本发明一实施例文本信息情感判定方法的流程示意图。
图3所示为本发明一实施例文本信息情感判定方法的流程示意图。
图4所示为本发明一实施例文本信息情感判定装置的架构示意图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明白,以下结合附图及具体实施方式对本发明作进一步说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明一实施例的文本信息情感判定方法如图1所示。在图1中,本实施例包括:
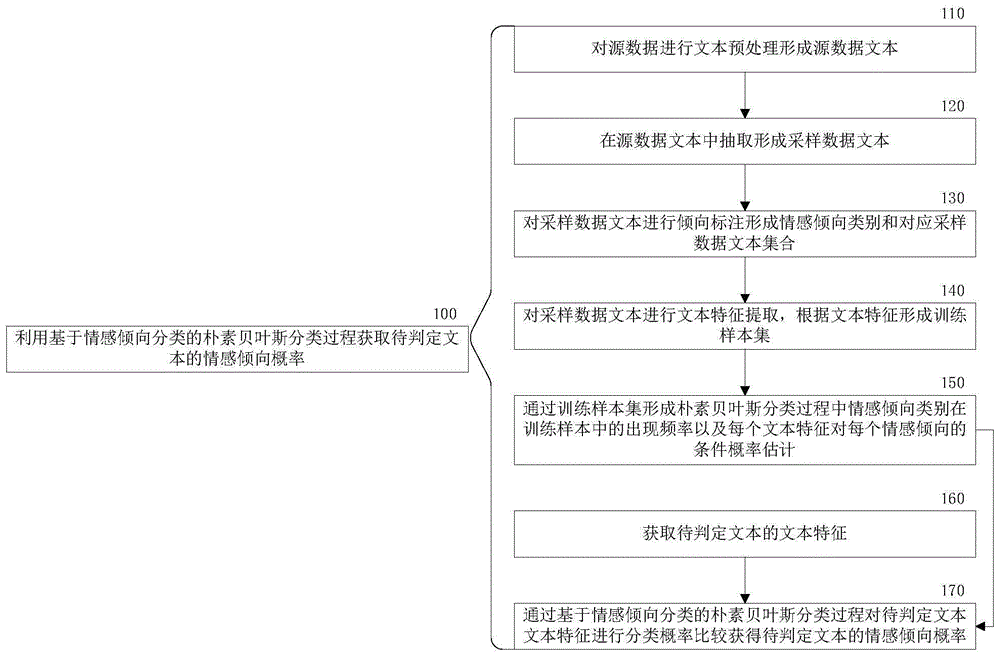
步骤100:利用基于情感倾向分类的朴素贝叶斯分类过程获取待判定文本的情感倾向概率。
利用情感倾向分类体现非特定情感类型的定性趋势,不直接反应情感类型。基于情感倾向分类的朴素贝叶斯分类过程通过确定情感倾向的文本信息组成的训练样本集确定每个情感倾向类别在训练样本中的出现频率以及每个样本特征对每个类别的条件概率估计。基于情感倾向分类的朴素贝叶斯分类过程对待判定文本的文本特征进行概率处理形成待判定文本情感倾向的量化概率。
本发明实施例的文本信息情感判定方法将用户在文本信息中潜在表达的情绪倾向利用分类过程概率化,形成剥离于具体情绪类型的程度量化数据,使得后续具体情绪类型判定具有定量数据基础,可以根据行业领域对用户的情绪表达做出针对性的细致判定。
如图1所示,在本发明一实施例中,文本信息情感判定方法中基于情感倾向分类的朴素贝叶斯分类过程的形成包括:
步骤110:对源数据进行文本预处理形成源数据文本。
源数据可以包括不同类型的互联网平台的数据,例如包括但不限于电商平台、微博平台和微信平台。数据源可以涵盖多个行业数据源,例如包括但不限于食品、化妆品和邮递业。数据源可以涵盖多个行业领域,例如包括但不限于收钱、制造和售后。源数据的信息类型包括但不限于用户发布文本数据来源平台和文本行业领域等。
文本预处理的目的是排除文本有效特征信息外的冗余数据和干扰数据。对数据源文本进行文本预处理的方式包括但不限于以下处理过程:
针对时间信息,进行删除处理;
针对链接信息,进行删除处理;
针对话题、主题信息,进行删除处理;
针对转发微博信息,仅保留当前用户发布微博内容;
针对用户名、用户昵称,进行删除处理;
针对特殊符号,进行删除处理;
针对表情符号,进行正则表达式匹配,替换为表达式对应的标准文本。
步骤120:在源数据文本中抽取形成采样数据文本。
在源数据文本中抽样是为了获得源数据文本的一个子集。抽取方式包括但不限于随机抽取、分层抽取、整体抽取和系统抽取。
本发明实施例优选随机抽取方式。以保证采样数据文本在源数据文本中分布性较好,缺少文本间内容关联,保证采样数据文本的独立性,避免出现隐含信息的正态分布。
步骤130:对采样数据文本进行倾向标注形成情感倾向类别和对应采样数据文本集合。
倾向标注采用人工方式进行。倾向标注的规则包括正面,负面,中立三类情感,形成三类分类类别。采样数据文本根据倾向标注确定倾向类别中采样数据文本的集合。
利用情感倾向替代具体情绪类型标注可以降低人工认知标准造成的误差。与采样数据文本的形成过程相结合,使得采样数据文本在基于源数据原始分布状态的基础上,利用情感倾向类别排除引入情绪类别,简化后续量化处理。
步骤140:对采样数据文本进行文本特征提取,根据文本特征形成训练样本集。
文本特征提取形成每个采样数据文本的一系列特征属性。本领域技术人员可以理解文本特征提取过程至少可以采取词袋(bagofwords,bow)、词向量(wordembedding)或tf-idf(termfrequencyinversedocumentfrequency)算法等模型提取文本特征。
本发明实施例中的文本特征提取采用词袋模型和tf-idf算法相结合,文本特征提取过程包括:
采用词袋模型筛选出采样数据文本的高热度词汇;
采用tf-idf算法计算每个高热度词汇权值;
根据高热度词汇权值确定文本特征向量。
利用采样数据文本与文本特征向量对应,文本特征向量形成采样数据文本的训练样本集。
步骤150:通过训练样本集形成朴素贝叶斯分类过程中情感倾向类别在训练样本中的出现频率以及每个文本特征对每个情感倾向的条件概率估计。
通过训练样本集对通用朴素贝叶斯分类过程的训练形成基于情感倾向分类的朴素贝叶斯分类过程。
本发明实施例的文本信息情感判定方法利用情感倾向替代具体情绪类型形成分类类别和训练样本集,使得通用朴素贝叶斯分类过程可以对文本信息情感倾向进行情感强度的合理量化。训练样本集的形成有效反映源数据的潜在信息分布,文本特征向量化有效反映训练样本的内在语义特征,保证了改进的朴素贝叶斯分类过程对待测文本进行情感倾向分类时的分类概率估值准确。
如图1所示,在本发明一实施例中,文本信息情感判定方法中获取待判定文本的情感倾向概率包括:
步骤160:获取待判定文本的文本特征。
待判定文本可以是采样数据文本之外的源数据文本、可以是来自源数据的文本。待判定文本的文本特征提取可以上述实施例中词袋模型和tf-idf算法相结合的提取过程,使得待判定文本的文本特征所处向量空间与训练样本集中采样数据文本的文本特征所处向量空间兼容。
步骤170:通过基于情感倾向分类的朴素贝叶斯分类过程对待判定文本的文本特征进行分类概率比较获得待判定文本的情感倾向概率。
一种进行分类概率比较的过程描述包括:
p(pos|neg)=exp(tm[neg|pos]-tm[pos|neg]);
prob(pos)=1/p(pos);
prob(neg)=1-1/p(neg)。
其中,neg是训练样本集中负面样本形成的文本特征数组,pos是训练样本集中正面样本形成的文本特征数组,p(pos|neg)是在负面类别中出现正面评价的比较概率,prob(pos)是属于正面分类的概率,prob(neg)是属于负面分类的概率,p(pos|neg)是条件概率估值。
本发明一实施例的文本信息情感判定方法如图2所示。在图2中,在上述文本信息情感判定方法基础上,还包括:
步骤200:根据情感倾向概率设置情感倾向分段阈值,根据待判定文本的情感倾向概率确定情绪类型。
每个待判定文本的情感倾向概率位于[0,1]之间,越接近1,情感越积极,可以根据量值判定为认同、喜欢或渴望,越接近0,情感越消极,可以根据量值判定为轻视、反感或厌恶。设置分段阈值不仅可以提供三种情感倾向的结果,还可以允许使用者根据自己的实际需求,对情感的分类标准进行调整。
如图2所示,在本发明一实施例中,文本信息情感判定方法中设置情感倾向分段阈值包括:
步骤210:根据在行业领域内对情感倾向校验获得的正确率和召回率确定分段阈值。
对待判定文本的情感倾向概率同时进行人工判定,通过数据统计确定情感倾向概率相对人工判定的正确率和召回率,并根据正确率和召回率确定分段阈值,改善情绪类型的判定准确性。
在本发明一实施例中,根据分类过程处理后获得的待判定文本的情感倾向概率,按照用户需求需求进行阈值调整调整,可以情绪强度分类至强正,弱正,中立,弱负,强负五类,进一步形成较准确的情绪类型判定。
本发明一实施例的文本信息情感判定方法如图3所示。在图3中,在上述文本信息情感判定方法基础上,还包括:
步骤300:根据行业属性对待判定文本进行拆分形成文本段落,利用基于情感倾向分类的朴素贝叶斯分类过程为每个文本段落判定情感倾向概率。
待判定文本可以对应至少一个行业属性,每个行业属性包括一系列(用于描述行业特征的)行业特征关键字,行业特征关键字根据待判定文本的数据来源中相关行业领域的行业特征形成。
如图3所示,在本发明一实施例中,文本信息情感判定方法中行业属性的行业特征关键字的形成过程包括:
步骤310:对数据来源中的行业内容进行分词形成语料。使得行业内容可以进行高效处理。
步骤320:对语料清洗后停用行业领域内基础名词。使得不合理语料和冗余名词、通用含义名词等语料合理排除。
步骤330:选取名词语料进行词频统计,对高频词进行有效性过滤形成行业特征关键字。利用行业内关键名词进行词频统计选取高频词汇作为行业特征关键字。
如图3所示,在本发明一实施例中,文本信息情感判定方法中对待判定文本进行拆分形成文本段落包括:
步骤340:确定待判定文本中行业属性的行业特征关键字。
根据不同行业属性确定待判定文本中行业属性;确定待判定文本中行业属性的行业特征关键字。
步骤350:根据行业特征关键字和分隔符将待判定文本断句形成与行业属性对应的文本段落。
本发明一实施例中,一种优选的断句过程包括:
当仅包括最多一个行业特征关键字的待判定文本不进行断句。
当包括至少两个行业特征关键字的待判定文本从第二个行业特征关键字起根据每个行业特征关键字前的分割符(逗号或者空格)进行断句;
最后行业特征关键字之后的文本为最终文本段落;
当两个相邻行业特征关键字属于同一行业时合并行业特征关键字。
如图3所示,在本发明一实施例中,文本信息情感判定方法中为每个文本段落判定待判定文本的情感倾向概率包括:
步骤360:将待判定文本的情感倾向概率与待判定文本中文本段落的情感倾向概率形成映射关联。
在对待判定文本进行基于情感倾向分类的朴素贝叶斯分类时,同时对每一个待判定文本中的文本段落单独进行基于情感倾向分类的朴素贝叶斯分类将对待判定文本的情感倾向概率与各文本段落的情感倾向概率进行关联形成待判定文本整体的情感倾向判定依据和待判定文本中针对包括的各确定行业属性形成的情感倾向判定依据。
本发明实施例的文本信息情感判定装置,包括:
存储器,用于存储本发明实施例的文本信息情感判定方法的处理过程的程序代码;
处理器,用于执行本发明实施例的文本信息情感判定方法的处理过程的程序代码。
可以采用dsp(digitalsignalprocessing)数字信号处理器、fpga(field-programmablegatearray)现场可编程门阵列、mcu(microcontrollerunit)系统板、soc(systemonachip)系统板或包括i/o的plc(programmablelogiccontroller)最小系统。
本发明一实施例的文本信息情感判定装置如图4所示。在图4中,本实施例包括:
朴素贝叶斯分类判定模块10,用于利用基于情感倾向分类的朴素贝叶斯分类过程获取待判定文本的情感倾向概率。
如图4所示,本发明一实施例中,文本信息情感判定装置还包括:
情感倾向划分模块20,用于根据情感倾向概率设置情感倾向分段阈值,根据待判定文本的情感倾向概率确定情绪类型。
如图4所示,本发明一实施例中,文本信息情感判定装置还包括:
文本属性区分模块30,用于根据行业属性对待判定文本进行拆分形成文本段落,利用基于情感倾向分类的朴素贝叶斯分类过程为每个文本段落判定情感倾向概率。
如图4所示,本发明一实施例中,朴素贝叶斯分类判定模块10包括:
预处理单元11,用于对源数据进行文本预处理形成源数据文本。
样本抽取单元12,用于在源数据文本中抽取形成采样数据文本。
分类标注单元13,用于对采样数据文本进行倾向标注形成情感倾向类别和对应采样数据文本集合。
文本特征提取单元14,用于对采样数据文本进行文本特征提取,根据文本特征形成训练样本集。
分类过程形成单元15,用于通过训练样本集形成朴素贝叶斯分类过程中情感倾向类别在训练样本中的出现频率以及每个文本特征对每个情感倾向的条件概率估计。
如图4所示,本发明一实施例中,朴素贝叶斯分类判定模块10还包括:
输入获取单元16,用于获取待判定文本的文本特征。
分类概率判定单元17,用于通过基于情感倾向分类的朴素贝叶斯分类过程对待判定文本的文本特征进行分类概率比较获得待判定文本的情感倾向概率。
如图4所示,本发明一实施例中,情感倾向划分模块20包括:
阈值设定单元21,用于根据在行业领域内对情感倾向校验获得的正确率和召回率确定分段阈值。
如图4所示,本发明一实施例中,文本属性区分模块30包括:
分词单元31,用于对数据来源中的行业内容进行分词形成语料。
消除单元32,用于对语料清洗后停用行业领域内基础名词。
统计单元33,用于选取名词语料进行词频统计,对高频词进行有效性过滤形成行业特征关键字。
如图4所示,本发明一实施例中,文本属性区分模块30还包括:
关键字确定单元34,用于确定待判定文本中行业属性的行业特征关键字。
断句单元35,用于根据行业特征关键字和分隔符将待判定文本断句形成与行业属性对应的文本段落。
如图4所示,本发明一实施例中,文本属性区分模块30还包括:
属性概率关联单元36,用于将待判定文本的情感倾向概率与待判定文本中文本段落的情感倾向概率形成映射关联。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!