维吾尔语文本突发事件要素识别方法与流程
本发明涉及一种事件要素识别
技术领域:
,是一种维吾尔语文本突发事件要素识别方法。
背景技术:
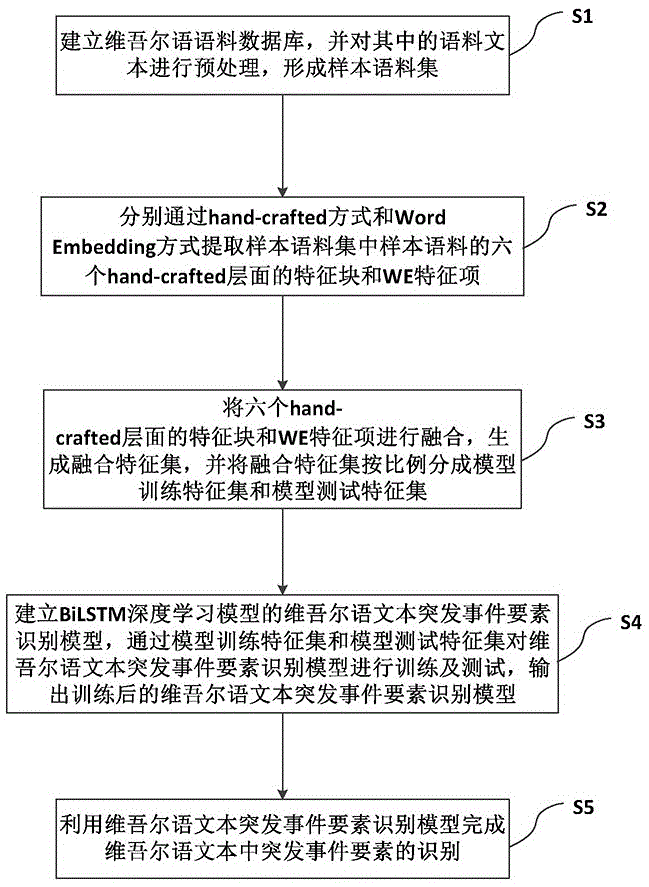
:突发事件即在某一区域内,发生的毫无征兆的社会事件,例如火灾、地震等等。随着新疆地区经济实力得到蓬勃发展,携带着通信行业的蒸蒸日上,大量的民族语言web网页与通信交流平台喷涌而出,网站内容信息丰富。维吾尔语语料资源的充足使得基于维吾尔语事件信息特征工程从无从下手进步为触手可及。基于维吾尔语语料的事件数据特征工程的分析研究对于新疆这个少数民族聚居的特殊区域,不仅在少数民族语言的发展方面具有重要意义,而且对分析新疆当前形势,做到事前积极防范,事中有效处理,事后科学改进提供及时可靠的数据。目前,基于机器学习的算法模型在事件要素识别的研究中已占据主导地位,大多采用对事件语料集依赖性强、人工语料库规模大的监督型机器学习算法。这种算法通过丰富的事件语料训练集学习抽取各类别事件要素的隐含特征,但如果训练语料不充分或者事件语料集类别单一,将会严重影响各类别事件要素的识别结果正确性和有效性。技术实现要素:本发明提供了一种维吾尔语文本突发事件要素识别方法,克服了上述现有技术之不足,其能有效解决现有维吾尔语事件要素识别方法对于人工语料依赖度高,模型识别稳定性弱的问题。本发明的技术方案是通过以下措施来实现的:一种维吾尔语文本突发事件要素识别方法,包括以下步骤:s1,建立维吾尔语语料数据库,并对其中的语料文本进行预处理,形成样本语料集;s2,分别通过hand-crafted方式和wordembedding方式提取样本语料集中样本语料的六个hand-crafted层面的特征块和we特征项;s3,将六个hand-crafted层面的特征块和we特征项进行融合,生成融合特征集,并将融合特征集按比例分成训练特征集和测试特征集;s4,建立bilstm深度学习模型的维吾尔语文本突发事件要素识别模型,通过训练特征集和测试特征集对维吾尔语文本突发事件要素识别模型进行训练及测试,输出训练后的维吾尔语文本突发事件要素识别模型;s5,利用维吾尔语文本突发事件要素识别模型完成维吾尔语文本中突发事件要素的识别。下面是对上述发明技术方案的进一步优化或/和改进:上述s2中通过hand-crafted方式提取样本语料集中样本语料的六个hand-crafted层面的特征块的过程为:s21,提取样本语料集中的样本语料,对样本语料中的事件句进行分词,获取每个词的词干和词干构型;s22,提取各个词词干的词特征块、词法特征块和触发词,并以触发词为中心提取各个词在事件句上下文中所承担的上下文特征块;s23,对词干构型中的附加成分进行切分,获取事件特征、语义特征以及句法特征。上述s2中通过wordembedding方式提取样本语料集中样本语料的we特征项的过程为选取样本语料中事件句,计算事件句中触发词之间的语义相似度,将语义相似度作为一个we特征项。上述s1中对维吾尔语语料数据库中的语料文本进行预处理即为去噪处理,去噪处理包括去除维吾尔语语料数据库中内容重复、事件句不完整、无明显事件句特征、空白语料文本。上述s4和s5中通过bn算法加速维吾尔语文本突发事件要素识别模型的收敛速度。上述s3中融合特征集包括融合特征和对所有突发事件要素进行标注的标签,其中标签1为突发事件要素,标签0为非突发事件要素。本发明借助bilstm模型构建维吾尔语文本突发事件要素识别模型,并通过结合维吾尔语自身语言特点分析,提取维吾尔语语料文本事件句的六大hand-crafted层面的特征块和wordembedding特征项,将六大hand-crafted层面的特征块与wordembedding特征项融合,通过融合特征训练维吾尔语文本突发事件要素识别模型。有益效果如下:1、本发明通过抽取维吾尔语文本事件的结构特征,并进行抽象化的学习,建立基于bilstm的维吾尔语文本突发事件要素识别模型,利用bilstm捕获每个词汇前向及后向的上下文信息,挖掘触发词与候选突发事件要素之间隐含的语义关系,快速查找出候选突发事件要素,获取识别结果,从而降低了对于人工语料依赖度,使识别结果更具客观性。2、本发明通过引入wordembedding特征项,利用其在词语语义表示方面具有对文本事件句中各词的抽象化重构具有相对良好的性能,通过事件句中各词空间定位关系来表述语义层次上的联系,提取文本事件句结构的主要信息,提高模型识别稳定性;同时将根据维吾尔语特点提取的六个hand-crafted层面的特征块与wordembedding特征项相结合,作为维吾尔语文本突发事件要素识别模型的输入,有效提高了模型识别精确度。3、本发明加入模型收敛算法,提高维吾尔语文本突发事件要素识别模型的训练速度并加快算法收敛,以此提高维吾尔语文本突发事件要素识别模型对维吾尔语文本事件要素识别的高效性。附图说明附图1为本发明实施例1的流程图。附图2为本发明实施例1提取样本语料六个hand-crafted层面的特征块的流程图。具体实施方式本发明不受下述实施例的限制,可根据本发明的技术方案与实际情况来确定具体的实施方式。下面结合实施例及附图对本发明作进一步描述:实施例1:如附图1所示,该维吾尔语文本突发事件要素识别方法,包括以下步骤:s1,建立维吾尔语语料数据库,并对其中的语料文本进行预处理,形成样本语料集;其具体过程为:s11,建立维吾尔语语料数据库;维吾尔语语料数据库中的所有维吾尔语语料文本可选取于多个网站,例如天山网、人民网的维吾尔语网页;这里可利用nutch等工具获取网页,并提取网页文件中的维吾尔语语料,形成维吾尔语语料数据库;s12,对维吾尔语语料数据库中的语料文本进行去噪处理,从而获取各类题材及未被标注的原生语料;去噪处理包括去除维吾尔语语料数据库中内容重复语料文本、事件句不完整语料文本、无明显事件句特征语料文本、空白语料文本。s2,分别通过hand-crafted方式和wordembedding方式提取样本语料集中样本语料的六个hand-crafted层面的特征块和we特征项。上述样本语料的六个hand-crafted层面的特征块和we特征项均以表格的形式展现,其行均为样本语料中事件句中的词,列均为维度。s3,将六个hand-crafted层面的特征块和we特征项进行融合,生成融合特征集,并将融合特征集按比例分成训练特征集和测试特征集。由于样本语料的六个hand-crafted层面的特征块和we特征项均以表格的形式展现,则六个hand-crafted层面的特征块和we特征项进行融合即将两张表合为一张表。上述融合特征集包括融合特征和对本语料集中所有突发事件要素进行标注的标签,其中标签1为突发事件要素,标签0为非突发事件要素。将融合特征集按比例(具体比例按实际情况设定)分成训练特征集和测试特征集时,具体比例根据实际情况设定,例如将融合特征集的80%划分为训练特征集,20%划分为测试特征集。s4,建立基于bilstm模型的维吾尔语文本突发事件要素识别模型,通过训练特征集和测试特征集对维吾尔语文本突发事件要素识别模型进行训练及测试,输出训练后的维吾尔语文本突发事件要素识别模型。上述利用测试特征集对训练后的维吾尔语文本突发事件要素识别模型进行测试;根据测试结果判断维吾尔语文本突发事件要素识别模型的识别率是否合格,若合格,则输出维吾尔语文本突发事件要素识别模型,若不合格,则对维吾尔语文本突发事件要素识别模型进行修改,即对模型中的参数进行调节。上述维吾尔语文本突发事件要素识别模型包括bilstm模型和分类器(例如softmax分类器)。bilstm模型为双向lstm模型,识别时用于对输入的事件句中维语词汇序列的所有特征进行分析,查找该事件句中所有的候选触发词,并根据候选触发词查找与之对应的候选突发事件要素(事件要素为描述事件发生的时间、地点、人物等信息),确定所有候选突发事件要素的融合特征,即以融合特征中的we特征项作为事件句维语词汇序列特征,然后利用bilstm能有效利用序列数据中长距离依赖信息特效的功能,挖掘事件句上下文隐含的语义特征,提取出所有候选突发事件要素的6个hand-crafted层面特征,之后将两类特征融合。softmax分类器用于对所有疑似的突发事件要素的融合特征进行分类,从而最终完成维吾尔语突发事件要素识别任务。在bilstm模型查找所有候选突发事件要素时,可引入bn算法加速模型的收敛速度,bn(batchnormalization)算法使每一层的数据都归一化均值为0、标准差为1,来保证数据分布稳定,使联合模型加快收敛,提高训练速度。bn算法主要使用下面公式进行归一化:其中h∈rd为当前神经网络层激活函数的输入值,γ∈rd,β∈rd用来保持模型的表达力,ε∈r为模型的正则化超参数。e(h)和var(h)的值在训练阶段时基于当前批量的样本值计算得到,而在测试阶段则基于整个数据集计算得到。s5,利用维吾尔语文本突发事件要素识别模型完成维吾尔语文本中突发事件要素的识别。本发明借助bilstm模型构建维吾尔语文本突发事件要素识别模型,并通过结合维吾尔语自身语言特点分析,提取维吾尔语语料文本事件句的六大hand-crafted层面的特征块和wordembedding特征项,将六大hand-crafted层面的特征块与wordembedding特征项融合,通过融合特征训练维吾尔语文本突发事件要素识别模型。有益效果如下:1、本发明通过抽取维吾尔语文本事件的结构特征,并进行抽象化的学习,建立基于bilstm的维吾尔语文本突发事件要素识别模型,利用bilstm捕获每个词汇前向及后向的上下文信息,挖掘触发词与候选突发事件要素之间隐含的语义关系,快速查找出候选突发事件要素,获取识别结果,从而降低了对于人工语料依赖度,使识别结果更具客观性。2、本发明通过引入wordembedding特征项,利用其在词语语义表示方面具有对文本事件句中各词的抽象化重构具有相对良好的性能,通过事件句中各词空间定位关系来表述语义层次上的联系,提取文本事件句结构的主要信息,提高模型识别稳定性;同时将根据维吾尔语特点提取的六个hand-crafted层面的特征块与wordembedding特征项相结合,作为维吾尔语文本突发事件要素识别模型的输入,有效提高了模型识别精确度。3、本发明加入模型收敛算法,提高维吾尔语文本突发事件要素识别模型的训练速度并加快算法收敛,以此提高维吾尔语文本突发事件要素识别模型对维吾尔语文本事件要素识别的高效性。下面是对上述发明技术方案的进一步优化或/和改进:如附图1、2所示,s2中通过hand-crafted方式提取样本语料集中样本语料的六个hand-crafted层面的特征块的过程为:s21,提取样本语料集中的样本语料,对样本语料中的事件句进行分词,获取每个词的词干和词干构型;由于维吾尔语属于阿尔泰语系突厥语族,是典型的黏着性语言,因此维吾尔语主要表现在以下两个方面的特点:1、词由词干前后附加构词或构形成分组成,即词通过词缀表现不同感情色彩、时态等,从而表达不同的含义,其中词干包含词的词汇意义。2、词干可多层缀加词缀,仅通过一个词干缀加多个词缀对说话人后来才知道的行为加以陈述。因此本发明结合维吾尔语的特点,分别提取词干和词干构型。s22,提取各个词词干的词特征块、词法特征块和触发词,并以触发词为中心提取各个词在事件句上下文中所承担的上下文特征块;上述触发词为文本中清晰表示事件发生的词语,是决定事件类别的重要特征,亦称为指示词。上述词特征块和词法特征块是以词汇本身及所对应的词性作为特征。上述触发词的上下文特征块是以词汇左边n个词,右边m个词的词特性、词法特征、句法以及语义特征;因此触发词的上下文特征块包括上下文语义特征、上下文语法特征、上下文句法特征。s23,对词干构型中的附加成分进行切分,获取事件特征、语义特征以及句法特征。上述对词干构型中的附加成分可为表述语气的词缀等等。上述语义特征是以词汇在词典中的释义作为特征。句法特征是以词汇所对应的依存关系作为特征。事件特征是基于事件的特征。如附图1所示,s2中通过wordembedding方式提取样本语料集中样本语料的we特征项的过程为选取样本语料中事件句,计算事件句中触发词之间的语义相似度,将语义相似度作为一个we特征项。这里使用word2vecter工具将文本数据转化为向量数据,即进行wordembedding训练,选择skip-gram+hs模型作为训练框架,可设定其词向量的维度,通过计算事件句中触发词之间的余弦相似度表示文本语义上的相关程度,由此准确的获取每个词在低维空间中语义的分布情况。例如一个事件句中的触发词分别为a1、a2,分别获取触发词a1、a2的词向量,利用二者之间的余弦值来表示两个触发词之间的语义相似度,将语义相似度作为一个we特征项。实施例2:选取250篇语料,统计其中包含时间、地点等不同类别的事件要素约7000多个,共生成了1780条样本数据;针对样本数据进行如下测试:1、分别采用本发明和通用的基于lstm的识别模型对样本数据进行突发事件要素识别,并通过准确率acc、召回率rec、f-value%评价突发事件要素的识别情况,其中f-value%计算方式如下:如表1所示,两种模型的性能比较,本发明的模型相较于通用的基于lstm的识别模型,有效提高了维吾尔语突发事件要素的识别精度。2、在事件识别任务中,有效特征的选择亦会对模型的性能以及最终的识别率产生直接影响。这里对六个hand-crafted层面的特征块所起的作用分别进行了实验,即去掉某特征块,验证去掉该特征块后的识别结果,并通过准确率acc、召回率rec、f-value%评价突发事件要素的识别情况。如表2所示,在去掉词特征、句法特征、语义特征、上下文特征时,突发事件要素的识别精度变化不大,在去掉事件特征时,突发事件要素的识别精度有所降低,由此证实了六个hand-crafted层面的特征块的引入,最终能够提高维吾尔语突发事件要素的识别精度。3、检测wordembedding训练中不同维度对维吾尔语突发事件要素识别的影响,将分别以维度为50维、100维、150维、200维的we特征项作为本发明识别模型的输入探索对维吾尔语突发事件要素识别的影响。如表3所示,维度为100时,维吾尔语突发事件要素识别精度最佳,随着维度不断增加,模型各评估指标出现回落并略微波动,说明当维度过高时,高维度特征中会包含更多的信息,从而会包含一些无用的干扰信息等,因此造成模型性能下降。以上技术特征构成了本发明的最佳实施例,其具有较强的适应性和最佳实施效果,可根据实际需要增减非必要的技术特征,来满足不同情况的需求。表1模型性能比较模型acc/%rec/%f-value/%lstm70.0763.2266.47bi-lstm74.6665.9770.05表2去除特征块对模型性能的影响去除hand-crafted层面的特征块acc/%rec/%f-value/%词特征75.3268.7371.87句法特征74.8865.669.93语义特征75.8966.1670.69上下文特征75.1164.3869.33事件特征74.2866.0969.95表3wordembedding维度对模型性能的影响维度acc/%rec/%f-value/%5082.3866.8773.8210079.3471.4975.2115079.0168.2473.2320076.266.1570.82当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1