一种面向老人异常的视频分析装置及视频分析方法与流程
本发明属于图像处理技术领域,具体涉及一种面向老人异常的视频分析装置及视频分析方法。
背景技术:
20世纪以来,我国已经进入老龄化社会,随着年龄的增大,老年人的心理健康也成为非常值得关注的一部分,而目前最常用的监护方法是通过摄像头或者其他传感装置来获取老人的实时情况。而对于视频监控来说,我们可以通过摄像头直接观察老人的情况,但是并不能经常实时的关注摄像头的情况,所以可以对得到的视频信息做进一步的处理,并向监护人报告老人的异常状况。而人的面部表情是表达情感和信息的主要沟通方式之一,研究表明,人的表情可以传递交流过程中55%的信息,所以可以通过监控视频中的人脸表情识别来监控老人的状况并在老人表情长时间异常时,对老人进行情感干预,比如播放搞笑视频或者舒缓的音乐以及亲属的相关视频等,以缓解老人的异常情绪。
传统的人脸表情识别主要包括人脸检测与定位,人脸特征提取,表情识别这三个部分,因此大部分表情识别的工作都集中在上述三个方面,而且大部分人脸表情识别都是针对静态图像的识别,针对视频中人脸表情的识别研究还比较少,大多数视频表请识别使用提取视频中人脸的各种特征的方式,通过定位,统计等方式进行人脸识别,识别的准确度较低。
综上所述,现有技术存在的问题是:大部分人脸识别都是针对静态图像的,少数针对视频的表情识别准确率比较低,并且大部分表情识别的网络结构参数以及计算量都很大,训练比较耗时,因此需要一种更加准确并且训练速度快的表情识别方法。
技术实现要素:
为了克服上述现有技术的不足,本发明的目的是提供一种面向老人异常的视频分析装置及视频分析方法,定位人脸区域并根据定位区域检测人脸的关键点,之后将这些属性注入到卷积神经网络中,通过卷积神经网络的训练,对视频中老人表情识别准确率明显提高,并且在老人表情异常(如伤心或愤怒)时,对老人进行情感干预,比如播放搞笑视频或者舒缓的音乐以及亲属的相关视频等,以缓解老人的异常情绪。
为了实现上述目的,本发明采用的技术方案是:
一种面向老人异常的视频分析方法,包括以下步骤:
1)收集包含老人面部的图片素材并标注图片中老人的面部表情,形成一个训练数据集合;
2)检测步骤1)中的图片并对图片中人脸区域进行定位;
3)根据步骤2)定位的人脸区域标定人脸的关键点;
4)构造一个可分离的卷积神经网络模型;
5)利用步骤2)中的人脸区域以及步骤3)中的人脸关键点,训练步骤4)中的卷积神经网络,并通过adam优化算法训练得到卷积神经网络的模型;
6)将待测视频进行分帧处理并利用步骤5)中神经网络的模型预测每帧图片中老人的表情;
7)若预测到老人表情异常,对老人进行情感干预,比如播放搞笑视频或者舒缓的音乐以及亲属的相关视频等,以缓解老人的异常情绪。
所述的步骤4中构建的卷积神经网络依次包括:输入层,卷积层,池化层、全连接层和输出层;卷积层和池化层可以重复一次或者多次,并且卷积层可以采用深度可分离卷积,该卷积方法可以使得训练参数减少,从而是加快训练速度;输入层读入根据图片定位的人脸区域以及人脸区域中的关键点,之后将定位区域和人脸关键点同时输入到卷积层;卷积层对定位区域和人脸关键点进行特征提取;所述卷积层和池化层的组合对图片中人脸区域以及人脸关键点进行特征提取并通过adam优化算法训练得到卷积神经网络模型;利用训练所得模型可以不断对输入的视频中的某一帧进行表情识别并在连续帧中表情一直异常时进行一定的表情干预,比如播放搞笑视频或者舒缓的音乐以及亲属的相关视频等,以缓解老人的异常情绪。
一种面向老人异常的视频分析装置,包括数据收集标注单元、人脸定位单元、卷积网络构造单元、卷积网络训练单元、人脸表情识别单元、异常处理单元,各单元依次连接:其中,
所述的数据收集标注单元:用于收集老人面部的图片素材并标注对应的表情属性,形成一个训练数据集合;
所述的人脸定位单元:用于定位步骤1)中图片中的人脸区域;
所述的关键点提取单元:用于提取定位人脸区域中人脸的关键点;
所述的卷积网络构造单元:用于构造一个表情识别的可分离的卷积神经网络;
所述的卷积网络训练单元:用于利用收集到的训练数据集合,定位人脸区域和提取人脸关键点,训练卷积神经网络,并得到卷积神经网络模型;
所述的人脸表情识别单元:用于利用卷积网络中训练的模型,预测视频帧序列中的人脸表情属性;
所述的异常处理单元:用于在检测到视频中老人表情异常时,对老人进行情感干预,比如播放搞笑视频或者舒缓的音乐以及亲属的相关视频等,以缓解老人的异常情绪。
本发明的有益效果是:1)将人脸区域与人脸关键点同时作为卷积神经网络的输入,减少了干扰因素对识别结果的影响,使得识别准确率变高;2)传统卷积神经网络训练参数多且计算量大,本方法中采用深度可分离卷积神经网络来构建,使得网络参数和计算量都大大减少,网络的训练速度快。
附图说明
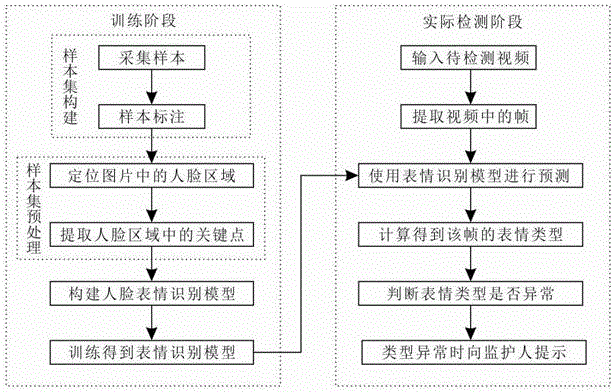
图1是面向老人的视频分析方法流程图。
图2是卷积神经网络结构示意图。
图3是面向老人的视频分析方法装置图。
具体实施方式
以下结合附图对本发明进一步叙述。
结合附图1对本发明提出的面向老人的视频分析方法作详细介绍
如图1所示,该面向老人的视频分析方法包括以下步骤:
收集包含老人表情的图片并对图片中的人脸表情进行标注,形成一个训练数据集合
检测训练数据集中图片中的人脸,并对其进行关键点标注:可以借助dlib库进行人脸检测及关键点标注,该库dlib由c++编写,提供了和机器学习、数值计算、图模型算法、图像处理等领域相关的一系列功能,其关键点标定准确率高达98%,由于不同的人脸可能有不同的姿态,其对表情识别的准确率有很大的影响,所以需要通过关键点标注来提升表情预测的准确率。所述人脸关键点包括眉毛,眼睛,鼻子,嘴巴和脸型等信息。
构造一个基于深度可分离的卷积神经网络,该网络的前端可以是多个卷积层,池化层和全连接层的组合,其后端是softmax等损耗层,该卷积神经网络的结构如图2所示。其中
输入层:该层用于读入图片中定位的人脸区域以及由人脸区域提取的关键点
卷积层:其输入是图片中定位的人脸区域以及由人脸区域提取的关键点,通过变换输出得到新特征
池化层:池化层可以将多个数值映射到一个数值,该层不但可以进一步加强学习到的新特性,而且可以使输出的特征空间变小,该层的输出可以重新作为卷积层的输入或者全连接层的输入
卷积层:其输入是上一池化层所产生的新特性,通过变换输出得到新特征
dropout层:该层可以防止卷积神经网络出现过拟合现象,他的输出可作为全连接层或池化层的输入
全连接层:对防过拟合层的输入做了一个线性变化,把学习到的特性投影到一个更好的子空间以利于属性预测
dropout层:防止卷积神经网络出现过拟合现象
softmax层:负责计算预测的属性类别和输入的属性类别之间的误差
输出层:主要负责输出图片中表情的类别
总体而言,将定位的人脸区域以及由人脸区域提取的关键点作为输入输入到卷积层,池化层和全连接层,之后做一些防过拟合操作。通过上述卷积神经网络的多层设计保证视频中表情识别的准确率。
卷积网络训练单元,用于通过收集并标注的数据,训练卷积神经网络中的网络参数,并得到输入定位的人脸区域以及由人脸区域提取的关键点并输出表情识别结果的卷积神经网络模型
表情识别单元:用于通过卷积神经网络模型,预测视频中的表情
异常处理单元:用于对检测结果进行判断,并在检测到老人长时间表情异常时,对老人进行情感干预,比如播放搞笑视频或者舒缓的音乐以及亲属的相关视频等,以缓解老人的异常情绪。
- 还没有人留言评论。精彩留言会获得点赞!