基于Spark平台运行的P-CFSFDP密度聚类方法与流程
本发明涉及大数据分析技术领域,具体涉及一种基于spark平台运行的p-cfsfdp密度聚类方法。
背景技术:
随着云计算研究的兴起,数据挖掘及大数据处理平台的研究成为关注热点。相比经典的分布式框架hadoop,spark通过引入rdd(resilientdistributeddatasets)迅速提升了数据挖掘工作的处理速度。聚类研究是数据挖掘中的重要一环,它根据数据点彼此的相似程度来进行分类。聚类算法应用范围十分广泛,上至天文学,下至生物信息学,文献计量学以及模式识别等诸多领域。
当下聚类算法的研究与运用对社会经济发展至关重要,如何对聚类算法的精度进行优化、对聚类算法进行并行化设计成为当前聚类算法发展的重点。在各种大数据处理技术盛行的时代,相比mapreduce(基于hadoop生态系统的大型数据计算框架)和低延迟实时流处理框架,spark在性能和可扩展性方面具有独特优势,其易用性强,通用性好,使其成为一个快速、集成化和多功能的大数据计算平台。现如今,spark已经是apache软件基金会旗下最活跃的开源项目之一。
《clusteringbyfastsearchandfindofdensitypeaks》快速搜索进行聚类并找出密度峰值(cfsfdp)聚类算法最早由alex和laio于2014年在《science》上提出。作者在算法中重新定义了“密度”和“距离”的概念,通过十分朴素和简洁的方法,对样本数据及进行密度聚类,得到较好的实验结果。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于spark平台运行的p-cfsfdp密度聚类方法,基于快速搜索进行聚类并找出密度峰值(cfsfdp)方法,可应用于spark平台进行大数据聚类分析和处理工作,通过使用新的数据结构和密度算法进行任务并行化设计,在数据结构和自动选取中心点方面进行功能优化,创建更快更精确的聚类。
本发明的目的可以通过采取如下技术方案达到:
一种基于spark平台运行的p-cfsfdp密度聚类方法,所述的密度聚类方法包括下列步骤:
实验预处理,使用spark的上下文读取源文件,产生聚类的初始集合s,使用文件读取函数map(s)对初始集合进行处理产生初始聚类集合rdddf,通过系统并行化函数coordinatematrix(df)将初始聚类集合rdddf转化为坐标矩阵,输入初始聚类集合rdddf,输出坐标矩阵cormatrix;
计算算法关键参数dc,参数dc定义是使得每个数据点的平均邻居个数为总数的一定比例,对于每一个分片,通过函数dcposition(n,l),输入限定系数n以及坐标矩阵长度l,输出截断距离dc;
定义算法中关键参数密度ρ,通过密度函数cutoff(cormatrix,dc)或者密度函数gaussian(dc.value,dc),输入坐标矩阵cormatrix以及截断距离dc,输出密度ρ、离散密度数组cutoffdensity或者高斯核函数密度数组gaussiandensity;
计算算法中关键参数距离δ,通过距离函数distance(cormatrix,density),输入坐标矩阵cormatrix以及密度数组density,输出距离δ和离散距离数组distance;
通过计算出的密度ρ和距离δ选取中心点,通过中心点选取函数parallelize(density,distance),输入密度数组density和距离数组distance,通过并行化计算,输出包含每个点λ值的数组lamuda;
中心点选取完毕后,将剩余点分配至对应中心点,通过剩余点分配函数cluster(cormatrix,density,lamuda,m),输入坐标矩阵cormatrix、密度数组density、lamuda数组和中心点个数m,输出中心点数组c和分配点数组r。
进一步地,所述的文件读取函数map(s)具体如下:
设系统样本为k,系统样本个数为k,每个样本的属性空间为s={λ1,λ2,…,λn};
定义第i个样本的第i个属性空间为λii,通过eucldean距离算法计算样本i、j之间的距离dij:
即可得i,j,dij作为三个参数,创建rdd对象df。
进一步地,所述的系统并行化函数coordinatematrix(df)具体如下:
系统并行化函数coordinatematrix(df)的作用是将输入数据rdddf转化为稀疏矩阵,即对数组中行序列进行数据格式的转换,输出为(i:long,j:long,value:double),其中i为行索引,j为列索引,value为实体的值。
进一步地,所述的函数dcposition(n,l)具体如下:
将集合s升序排列,有s’={d1≤d2≤d3≤…≤dm},设集合中有m个元素,截断距离dc须满足条件的距离位置设为dk,对于
进一步地,所述的密度函数cutoffdensity(cormatrix,dc)具体如下:
cutoff密度的定义为:
ρi定义为点i的密度,其中dij为第i个点和第j个点的距离,若x(d)=1,则将j、i彼此定义为邻居。
进一步地,所述的密度函数gaussiandensity(dc.value,dc)具体如下:
gaussian密度的定义为:
ρi定义为点i的密度,其中dij为第i个点和第j个点的距离,其中
进一步地,所述的距离函数distance(cormatrix,density)具体如下:
将点i的距离值定义为δi:
δi需满足:比自身点i密度值ρi大,且有距离点i最近的点j之间的距离dij,此时我们定义dij为点i的距离δi,若i为局部最大点,δi为样本s中与xi距离最大的数据点与xi的距离;若i不为局部最大点,在样本s中一定存在一个或多个点属于集合c,使得集合c中的点j满足条件ρj>ρi,分别计算集合c中的点与点i的距离dij,令这样的点集为集合k,此时δi为在集合k中距离值最小的点。
进一步地,所述的中心点选取函数parallelize(density,distance)具体如下:
调用中心点选取函数parallelize对密度矩阵和距离矩阵作笛卡尔积,得到结果集t为中心点特征集合,定义γi为点i的密度值ρi和距离值δi的笛卡尔积结果,有t={γ1,γ2,γ3,…,γn},由于中心点将同时具有中心点自身高密度及与其他中心点距离远两个特征,将结果集t进行升序排序定义,排序后的集合为t',t'={γ1≤γ2≤γ3≤…≤γm},γ值越大越有可能是样本中心点,通过调用中心点选取函数parallelize将密度矩阵和距离矩阵在内存中进行分片操作,实现并行化计算。如上文所述,ρ定义为密度值,δ定义为距离值:
γ=ρ×δ
接下来,对进行降序排序,即可得到值排序的候选中心点候选集合lamuda,达到自动选取中心点的目的。
进一步地,所述的剩余点分配函数cluster(cormatrix,density,lamuda,m)具体如下:
给出中心点个数m,从中心点候选集合lamuda中选取前m个点集作为中心点数组c,通过遍历坐标矩阵cormatrix中的点i和中心点数组c中的点,选取距离i最近的中心点数组c中的点cj为点i的中心点,并将i分配到cj对应的簇j中。
本发明相对于现有技术具有如下的优点及效果:
1)、本发明通过探究dc值、不同密度聚类方法和聚类结果的准确性的关系,得到了在[1%,2%]、[10%,20%]这两个区间中选取dc值,聚类效果的纯度都比较稳定的特点。其次,选择合适的dc值后,使用高斯核函数计算出来的密度能使聚类结果更加稳定。
2)、本发明改进了先前使用图像来选择聚类中心的方式,通过自动选择最优中心点来进行聚类搜索主流数据集进行算法测试。结果显示,通过使用新的数据结构和密度聚类方法能够去创建更快更精确的聚类。
附图说明
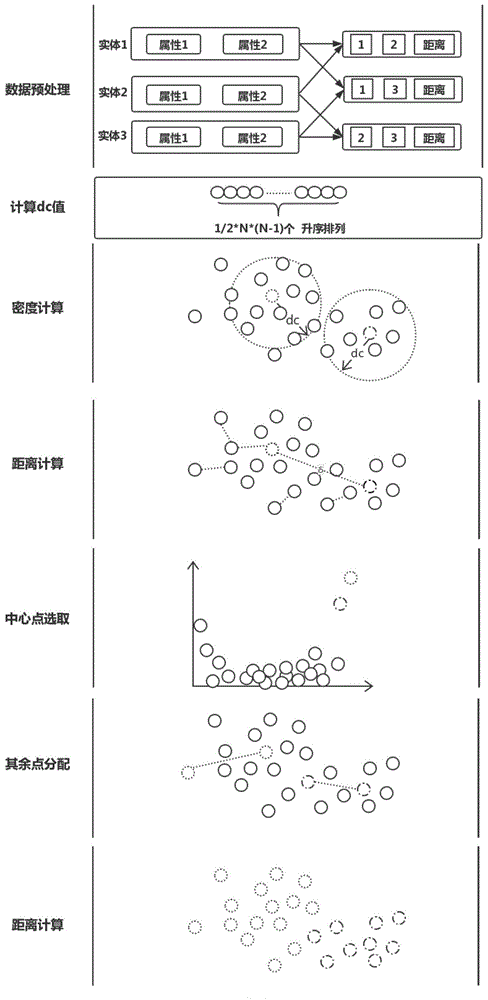
图1是本发明中公开的基于spark平台运行的p-cfsfdp密度聚类方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
如图1所述,本实施例公开了一种基于spark平台运行的p-cfsfdp密度聚类方法的流程图,该密度聚类方法由数据预处理、密度计算、距离计算、中心点选取、其余点分配组成。其中,该密度聚类方法借助spark平台和spark机器学习库mllib。主要作用为进行并行化实现和密度聚类方法分析设计;密度计算主要通过高斯核函数(gaussiankernel)来进行计算,主要作用为给数据集中每一个数据点分配密度值。
密度聚类方法包括以下步骤:
s1、实验预处理。通过调用函数sc.textfile(k)读取系统样本k,调用函数df=data.map()对源数据进行预处理,将data映射为包含rdd的对象df,并且调用函数vector.split()、vector.filter()方法进行预处理。
输入:具有k个属性空间sk={λ1,λ2,…,λn}的系统样本data。
输出:去掉多余符号、转换文本格式为double格式的rdddf。
对于本实施例中的vector.filter()函数,用于设置源文件格式,将文本转换为数值型数据进行归一化操作。对于说明书中的vector.split()函数用于定义源数据中的分隔符,以便处理含分隔符的源数据,进行数据预处理。
数据预处理结束,通过函数euclidean(df(i),df(j))对样本数据中每个样本计算两两之间的欧式距离。
输入:rdd对象df中的第i个对象df(i),rdd对象df中的第j个对象df(j);
输出:包含三个参数的坐标矩阵coordinatematrix(i:long,j:long,value:double),三个参数分别为第i个点i,第j个点j,以及它们的欧式距离dij;
假设系统样本中含k个样本,每个样本的属性空间为sk={λ1,λ2,…,λn},λn为样本sk第n个特征,采用欧式距离定义每一个点之间的距离,输出
输入:系统样本k,样本个数为k,每个样本的属性空间为s={λ1,λ2,…,λn};
输出:样本k中第i个点i,第j个点j,以及它们的欧式距离dij,作为三个参数,以此创建rdd对象coordinatematrix(i:long,j:long,value:double),其中i为行索引,j为列索引,value为实体的值。
s2、计算算法关键参数dc,参数dc定义是使得每个数据点的平均邻居个数为总数的一定比例,如1%~2%。为了更好的解释参数dc,我们设数据集总个数为n,样本个数为k,根据“握手定律”数据集中的点两两组合后共有k×(k-1)个距离对,去重后我们得到
每一对小于dk的dij,会使得i和j的邻居总数加1,所以我们有平均邻居个数为
s3、密度计算。
首先,cutoff密度的定义为:
ρi定义为点i的密度,其中dij为第i个点和第j个点的距离,若x(d)=1,则将j、i彼此定义为邻居。
其次,gaussian密度的定义为:
ρi定义为点i的密度,其中dij为第i个点和第j个点的距离,其中
密度计算原理可理解为:以候选点为圆心,画一个半径为dc的圆,(根据公式)每一个在圈内的点都会为它提供密度值。通过引入高斯核函数来计算密度,高斯核函数是根据距离衰减的。高斯核函数是从中心到外围有权重的距离公式,该函数可表示一个密度连续区域,当dij<dc时,函数的值域落在
s4、距离计算。通过以下定义计算每一个点的距离值。距离δ定义为:若i为局部最大点,有δi为k中与xi距离最大的数据点与xi的距离;若i不为局部最大点,在集合c中(由的点组成)与i距离最小的那一个。即:
算法遍历coordinatematrix(i:long,j:long,value:double)坐标矩阵,从第一个点i开始,在整个坐标矩阵中对j={1→n}进行遍历,比较其于密度矩阵中的密度值。之后构建距离数组distance,当ρi>ρi,均有distance(i)=min{ρi,ρj}。随着i值增大,重复进行如上计算。
s5、中心点选取。求出每个点的密度和距离值后,对产生的数据点进行需要进行λ值的计算,以便选出中心点。调用sparkparallelize方法对密度矩阵和距离矩阵作笛卡尔积,中心点将同时具有高密度和高距离两个特性。通过调用函数parallelize(density,distance)将density和distance在内存中进行分片操作,再通过join操作进行实现并行化计算。join方法是对两个需要连接的rdd进行聚合操作,通过把每个key相同的数据点进行笛卡尔积操作,ρ定义为密度值,δ定义为距离值:
γ=ρ×δ
最后返回key-value型的数据集。
接下来,对进行降序排序,即可得到值排序的候选中心点候选集合lamuda,达到自动选取中心点的目的。
由此计算出的λ值,可以使算法能够自动地选取中心点。
s6、剩余点分配。
分配剩余点过程通过调用剩余点分配函数cluster(cormatrix,ensity,lamuda,m),给出中心点个数m,从中心点候选集合lamuda中选取前m个点集作为中心点数组c,通过遍历坐标矩阵cormatrix中的点i和中心点数组c中的点,选取距离i最近的中心点数组c中的点cj为点i的中心点,并将i分配到cj对应的簇j中。
综上所述,本实施例公开的基于spark平台运行的p-cfsfdp密度聚类方法。同时,本发明改进了先前使用图像来选择聚类中心的方式,过自动选择最优中心点来进行聚类搜索主流数据集进行密度聚类方法测试,实现了一个可以在spark平台上运行的p-cfsfdp密度聚类方法。同时改进了原有方法的缺陷,过对密度聚类方法进行实验探究,得到了在[1%,2%]、[10%,20%]这两个区间中选取dc值,聚类效果的纯度都比较稳定的特点。其次,选择合适的dc值后,使用高斯核函数计算出来的密度能使聚类结果更加稳定。进行了数据结构和自动选取中心点的功能优化。改进后的密度聚类方法通过优秀的效率和准确性有助于大数据时代下数据分析和研究工作。
上述实施例通过spark平台对密度聚类方法进行任务并行化设计,并基于sparkmllib库进行密度聚类方法设计和实证分析。结果显示,通过使用本发明公开的数据结构和密度聚类方法能够去创建更快更精确的聚类。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!