一种跨模态情感迁移方法及装置与流程
本发明涉及视频图像处理技术领域,具体而言涉及一种跨模态情感迁移方法及装置。
背景技术:
人的情感表达有多种方式,比如面部的喜怒哀乐表情,说话声音的音量音调,以及语言文字的运用等。因此,为了更加全面的描述和刻画一个月的情绪状态,当前业界通常会采取多通道情绪识别的方式,实现对一个人情绪状态的综合判定。通常而言,人们更倾向于在说话语音里表达更多的情绪状态细节,而在面部表情、肢体动作等方面相对收敛和保守,难以捕获足够多的情绪细节。加之在实际应用场景中,由于面部表情伪装、口罩遮掩、光线角度等因素,通过面部表情、肢体动作等方式去描述和反映一个人的情绪状态更是存在一定的局限性。
基于上述局限性,有必要设计一种跨模态情感迁移技术,能够根据用户的语音情绪状况,对该用户的面部表情进行相应的修正或者增强,从而让用户的表情看上去更加生动而富有感染力,可有效提升在线视频聊天或者在线教学的趣味性和互动性。
技术实现要素:
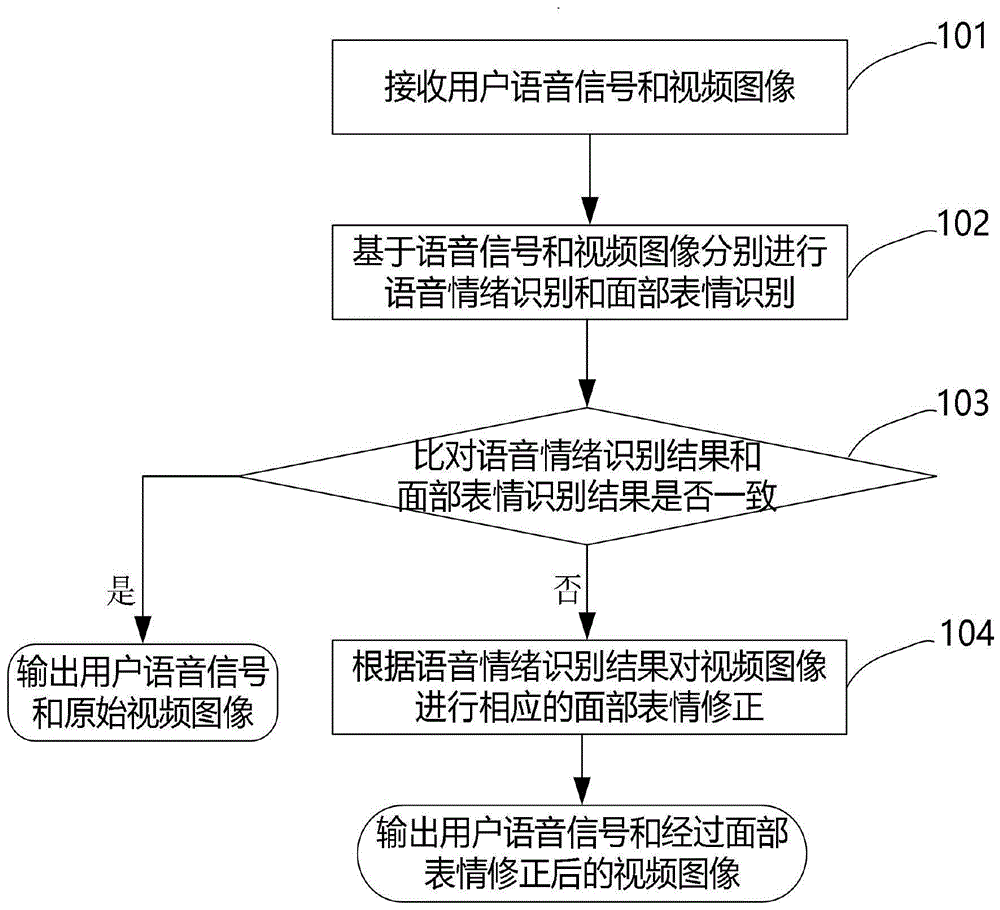
本发明提出一种跨模态情感迁移方法,所述方法包括:步骤s101:接收用户当前的语音信号和视频图像;步骤s102:基于所述语音信号和视频图像分别进行用户语音情绪识别和面部表情识别;步骤s103:比对所述语音情绪识别结果和面部表情识别结果是否一致,如果一致则将用户语音信号和视频图像进行直接输出,否则转至步骤s104;以及步骤s104:根据所述语音情绪识别结果对所述用户视频图像进行相应的面部表情修正,并将用户语音信号和经过面部表情修正后的视频图像作为最终输出。
示例性地,所述步骤s104中的面部表情修正包括:从预先构建的所述用户基本表情特征向量库vs中选取所述语音情绪识别结果所对应的相应表情人脸关键点特征向量vsi,其中i为所述表情类别;计算用于表情修正的人脸关键点特征向量v,即v=w*vsi+(1-w)*vr,其中w为预先设定的权值,vr为基于所述用户视频图像所提取的人脸关键点特征向量;基于所述v,对最所述视频图像中的人脸区域进行相应的拉伸或收缩,从而生成所述经过面部表情修正后的视频图像。
示例性地,在所述步骤s101之前,还包括:获取所述用户的愉快、惊讶、厌恶、愤怒、恐惧、悲伤六种基本表情所对应的视频图像;针对所述六种基本表情所对应的视频图像,分别提取人脸关键点特征向量vsi(1≤i≤6),以此构建所述用户的基本表情特征向量库vs。
另一方面,本发明还提供一种跨模态情感迁移装置,所述装置包括:音视频接收模块,用于接收用户当前的语音信号和视频图像;情绪识别模块,基于所述语音信号和视频图像分别进行用户语音情绪识别和面部表情识别;表情修正模块,用于根据所述语音情绪识别结果对所述视频图像进行相应的面部表情修正;音视频输出模块,用于用户最终的语音信号和视频图像的输出;以及基本表情特征向量库模块,用于存储所述用户六种基本表情所对应的人脸关键点特征向量。
示例性地,所述表情修正模块通过如下方法实现:从基本表情特征向量库vs中选取所述语音情绪识别结果所对应的相应表情人脸关键点特征向量vsi,其中i为所述表情类别;计算用于表情修正的人脸关键点特征向量v,即v=w*vsi+(1-w)*vr,其中w为预先设定的权值,vr为基于所述用户视频图像所提取的人脸关键点特征向量;基于所述v,对最所述视频图像中的人脸区域进行相应的拉伸或收缩,从而生成经过所述面部表情修正后的视频图像。
示例性地,所述基本表情特征向量库vs通过如下方法构建:获取所述用户的愉快、惊讶、厌恶、愤怒、恐惧、悲伤六种基本表情所对应的视频图像;针对所述六种基本表情所对应的视频图像,分别提取人脸关键点特征向量vsi(1≤i≤6),以此构建所述用户的基本表情特征向量库vs。
本发明提供的跨模态情感迁移方法及装置能够根据用户的语音情绪状况,对该用户的视频图像进行相应的表情修正,从而让用户的表情看上去更加生动而富有感染力,可有效提升在线视频聊天或者在线教学的趣味性和互动性。
附图说明
本发明的下列附图在此作为本发明的一部分用于理解本发明。附图中示出了本发明的实施例及其描述,用来解释本发明的原理。
附图中:
图1示出了根据本发明的实施例的一种跨模态情感迁移方法100的流程图;
图2示出了根据本发明的实施例的一种跨模态情感迁移装置的功能模块组成图。
具体实施方式
在下文的描述中,给出了大量具体的细节以便提供对本发明更为彻底的理解。然而,对于本领域技术人员而言显而易见的是,本发明可以无需一个或多个这些细节而得以实施。在其他的例子中,为了避免与本发明发生混淆,对于本领域公知的一些技术特征未进行描述。
应当理解的是,本发明能够以不同形式实施,而不应当解释为局限于这里提出的实施例。相反地,提供这些实施例将使公开彻底和完全,并且将本发明的范围完全地传递给本领域技术人员。
在此使用的术语的目的仅在于描述具体实施例并且不作为本发明的限制。在此使用时,单数形式的“一”、“一个”和“所述/该”也意图包括复数形式,除非上下文清楚指出另外的方式。还应明白术语“组成”和/或“包括”,当在该说明书中使用时,确定所述特征、整数、步骤、操作、元件和/或部件的存在,但不排除一个或更多其它的特征、整数、步骤、操作、元件、部件和/或组的存在或添加。在此使用时,术语“和/或”包括相关所列项目的任何及所有组合。
为了彻底理解本发明,将在下列的描述中提出详细的步骤以及详细的结构,以便阐释本发明的技术方案。本发明的较佳实施例详细描述如下,然而除了这些详细描述外,本发明还可以具有其他实施方式。
本发明提出一种跨模态情感迁移方法及装置,能够根据用户的语音情绪状况,对该用户的视频图像进行相应的表情修正。本发明提供的跨模态情感迁移方法及装置仅需要普通的音视频捕捉设备加上软件系统即可实现。
图1示出了根据本发明实施例的一种跨模态情感迁移方法100的流程图。下面参照图1来具体描述根据本发明实施例的一种跨模态情感迁移方法100。
根据本发明的实施例,跨模态情感迁移方法100包括如下步骤:
步骤s101:接收用户当前的语音信号和视频图像。示例性地,本步骤中用户的语音信号可通过录音笔或者手机麦克风进行采集,用户的视频图像可以通过普通的基于可见光的彩色或灰度摄像装置进行采集,所述摄像装置例如普通摄像头、网络摄像头、手机的前置摄像头等。
步骤s102:基于所述语音信号和视频图像分别进行用户语音情绪识别和面部表情识别。示例性的,针对所述语音信号,提取音频特征向量sr,并将其输入训练好的语音情绪分类器进行所述语音信号的情绪识别;针对所述视频图像,进行人脸检测和定位,并提取人脸关键点特征向量vr,并将其输入训练好的人脸表情分类器进行所述视频图像的表情识别。
步骤s103:比对所述语音情绪识别结果和面部表情识别结果是否一致,如果一致则将用户语音信号和视频图像进行直接输出,否则转至步骤s104。
步骤s104:根据所述语音情绪识别结果对所述用户视频图像进行相应的面部表情修正,并将用户语音信号和经过面部表情修正后的视频图像作为最终输出。示例性的,该步骤中的面部表情修正包括:从预先构建的所述用户基本表情特征向量库vs中选取所述语音情绪识别结果所对应的相应表情人脸关键点特征向量vsi,其中i为所述表情类别;计算用于表情修正的人脸关键点特征向量v,即v=w*vsi+(1-w)*vr,其中w为预先设定的权值,vr为基于所述用户视频图像所提取的人脸关键点特征向量;基于所述v,对最所述视频图像中的人脸区域进行相应的拉伸或收缩,从而生成所述经过面部表情修正后的视频图像。
示例性的,在所述步骤s101之前,还包括基本表情特征向量库vs的构建过程:首先,获取所述用户的愉快、惊讶、厌恶、愤怒、恐惧、悲伤六种基本表情所对应的视频图像;然后,针对所述六种基本表情所对应的视频图像,分别提取人脸关键点特征向量vsi(1≤i≤6),以此构建所述用户的基本表情特征向量库vs。
根据本发明的另一方面,还提供了一种跨模态情感迁移装置。图2示出了根据本发明实施例的跨模态情感迁移装置200的结构框图。
如图2所示,跨模态情感迁移装置200包括:音视频接收模块201、情绪识别模块202、表情修正模块203、音视频输出模块204和基本表情特征向量库模块205。其中,音视频接收模块,用于接收用户当前的语音信号和视频图像;情绪识别模块,基于所述语音信号和视频图像分别进行用户语音情绪识别和面部表情识别;表情修正模块,用于根据所述语音情绪识别结果对所述视频图像进行相应的面部表情修正;音视频输出模块,用于用户最终的语音信号和视频图像的输出;基本表情特征向量库模块,用于存储所述用户六种基本表情所对应的人脸关键点特征向量。
根据本发明一个实施例,情绪识别模块202可以包括:针对所述语音信号,提取音频特征向量sr,并将其输入训练好的语音情绪分类器进行所述语音信号的情绪识别;针对所述视频图像,进行人脸检测和定位,并提取人脸关键点特征向量vr,并将其输入训练好的人脸表情分类器进行所述视频图像的表情识别。
根据本发明一个实施例,表情修正模块203可以包括:首先,从基本表情特征向量库vs中选取所述语音情绪识别结果所对应的相应表情人脸关键点特征向量vsi,其中i为所述表情类别;其次,计算用于表情修正的人脸关键点特征向量v,即v=w*vsi+(1-w)*vr,其中w为预先设定的权值,vr为基于所述用户视频图像所提取的人脸关键点特征向量;最后,基于所述v,对最所述视频图像中的人脸区域进行相应的拉伸或收缩,从而生成经过所述面部表情修正后的视频图像。
根据本发明一个实施例,基本表情特征向量库模块205可以通过如下过程进行构建:首先,获取所述用户的愉快、惊讶、厌恶、愤怒、恐惧、悲伤六种基本表情所对应的视频图像;然后,针对所述六种基本表情所对应的视频图像,分别提取人脸关键点特征向量vsi(1≤i≤6),以此构建所述用户的基本表情特征向量库。
本发明提供的一种跨模态情感迁移装置,能够根据用户的语音情绪状况,对该用户的视频图像进行相应的表情修正,仅需要普通的音视频捕捉设备加上软件系统即可实现。因此,该装置易于实现并且在使用上非常灵活和方便。
进一步地,根据本发明实施例的上述跨模态情感迁移装置所需要的外界输入仅有普通的音视频数据,并且只需要在屏幕上与用户进行交互,其可以部署在普通个人计算机、智能手机、平板电脑等常见终端上运行,无需特殊硬件,因此对硬件要求较低。
本领域的技术人员可以理解,本发明实施例的跨模态情感迁移装置200还可以包括上述各种类型的音视频采集装置,用于用户语音数据和视频图像的采集,在此并不进行限定。
本发明实施例的各个模块可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(dsp)来实现根据本发明实施例的跨模态情感迁移装置中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在存储载体上提供,或者以任何其他形式提供。
本发明已经通过上述实施例进行了说明,但应当理解的是,上述实施例只是用于举例和说明的目的,而非意在将本发明限制于所描述的实施例范围内。此外本领域技术人员可以理解的是,本发明并不局限于上述实施例,根据本发明的教导还可以做出更多种的变型和修改,这些变型和修改均落在本发明所要求保护的范围以内。本发明的保护范围由附属的权利要求书及其等效范围所界定。
- 还没有人留言评论。精彩留言会获得点赞!