基于排序损失函数的一阶目标检测器的优化方法与流程
本发明涉及的是一种人工智能领域的技术,具体是一种基于排序损失函数的一阶目标检测器的优化方法。
背景技术:
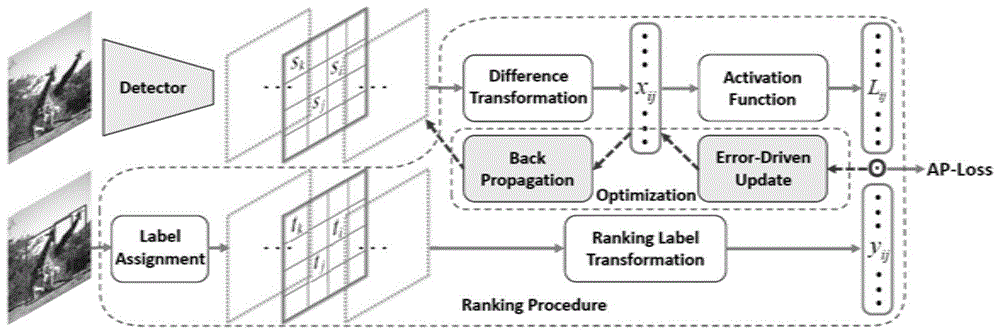
:图像中的目标检测算法需要对图像中某些特定类别的目标进行识别并且精准定位。目前基于深度学习分为两类,一类是一阶目标检测器,另一类是多阶目标检测器。其中,一阶目标检测器直接从预定义的检测框中通过分类和回归来检测目标,而多阶的目标检测器可以看做是在一阶的目标检测器的检测结果上再进行一次更精确的提炼。通常多阶目标检测器相比于一阶目标检测器有着更好的检测效果,但速度更慢。在一阶目标检测器的训练中,由于存在大量的预定义检测框,且只有其中一小部分能匹配到待测目标,所以使得正负样本比率极度不均衡。在这种情况下,如果使用常规分类任务的损失函数训练,则会使模型难以收敛到有效解。所以一阶目标检测器通常会使用针对这种正负样本不均衡情况改进后的分类损失函数来进行训练,但现有检测器采用的目标函数不够理想,容易陷入局部最优解,使得检测效果受到影响。技术实现要素:本发明针对现有技术存在的上述不足,提出一种基于排序损失函数的一阶目标检测器的优化方法,用ap损失函数代替传统的交叉熵损失函数,能够解决一阶目标检测器训练中正负样本不均衡的问题,且具有出色的泛化性能。同时通过基于误差驱动的更新算法,能够应对目标函数不连续的特性,且在非凸条件下也有出色的优化效果。通过本方法训练出的目标检测器能够不依赖于特定参数的选取,在coco目标检测数据集上达到42.1map的检测效果。本发明是通过以下技术方案实现的:本发明涉及一种基于排序损失函数的一阶目标检测器的优化方法,首先在二维图像上预定义密集的检测框,根据检测框与目标框的交并比(intersection-over-union,iou)为每个检测框分配标签,并将待检测图片输入一阶目标检测器,得到每个检测框中的目标置信度分数和精确框的预测,通过基于误差驱动的更新方法对一阶目标检测器进行训练,从而实现检测器的优化检测。所述的一阶目标检测器采用但不限于:检测器为每个检测框i输出一个目标的置信度分数si和精确框的预测(wi,hi,ai,bi),再经过极大值抑制处理输出最终检测结果,其中:wi代表检测框宽度相对第i个检测框的宽度的偏移,hi代表高度,ai代表横坐标偏移,bi代表纵坐标偏移。所述的检测框,在同一个位置会存在k个大小形状完全相同的检测框,其中k为目标类别的个数,每个检测框对应响应一个类别。所述的标签ti={0,1},其中0代表负样本,1代表正样本,从而将多类别的目标检测转化成单类别的前景检测,适合于构造一个二值排序任务。本发明采用平均精度(averageprecision,ap)作为二值排序任务的度量标准,即以1-ap作为损失函数用于优化一阶目标检测器。所述的优化检测是指采用训练后的一阶目标检测器分析输入图片并输出每个检测框的分数和精确框的预测,再经过非极大值抑制处理后得到最终结果。技术效果与现有技术相比,本发明使用的排序损失函数不受正负样本比例不均衡的影响,能够反映真实的检测器性能且不依赖于超参数的具体选择,因此有更强的泛化与检测性能。本发明提出的优化算法能够应对排序损失函数不连续的问题,且在非凸条件下也有很好的优化效果。附图说明图1是本发明流程示意图;图2是实施例ap损失函数的优化示意图。具体实施方式如图1所示,为本实施例涉及的一种基于排序损失函数的一阶目标检测器训练方法,包括以下步骤:a:首先在二维图像上预定义密集的检测框,本实施例中设定在同一个位置会存在k个大小形状完全相同的检测框(其中k为目标类别的个数),每一个检测框负责响应某一个类别;然后根据检测框与目标框的iou为每个检测框分配标签ti={0,1},其中0代表负样本,1代表正样本,从而将多类别的目标检测转化成单类别的前景检测,适合于构造一个二值排序任务。b:将待检测图片输入一阶目标检测器,得到每个检测框中的目标置信度分数si和精确框的预测。所述的目标置信度分数si的范围是整个实数域,该目标置信度分数为一阶目标检测器分类分支最后一层的输出,具体来说是神经网络分类分支最后一层卷积层的输出,是一个向量,si代表第i个检测框的分数;一般来说是检测器的分类分支的最后一层卷积层的输出,而不经过softmax、sigmoid或relu等激活层。所述的精确框的预测为(wi,hi,ai,bi),其中:wi代表检测框宽度相对第i个检测框的宽度的偏移,hi代表高度,ai代表横坐标偏移,bi代表纵坐标偏移,本发明用平滑l1损失函数进行精确框的预测的训练。所述的平滑l1损失函数c:计算目标置信度分数的两两之差,得到差值矩阵{xij},将差值矩阵中的元素输入激活函数:其中:xij代表差值矩阵的第i行j列的元素且xij=sj-si,lij代表此激活函数的输出矩阵的第i行第j列的元素,h(x)代表阶跃函数。对应目标置信度分数的两两之差,定义两两成对的标签即当下标满足ti=1,tj=0时指示函数取1,否则取0;相应得到平均精度其中:|p|代表正样本的个数。d:以1-ap作为损失函数,通过基于误差驱动的更新算法得到针对输入的差值矩阵{xij}变量x的期望的更新方向以克服目标函数不连续的问题,该损失函数的更新为:δxij=-yij·lij;e:计算针对模型参数θ的更新方向δθ,使得θ的变化造成的x的变化能够与δx尽可能相似,并且θ的变化要尽可能小,相当于优化问题:其中:θ(n)代表在训练过程中第n步时的模型参数。对x(θ)在θ(n)处使用一阶泰勒展开并忽略高阶项,则优化问题转化为:其中:即将xij的梯度设为-δxij,然后使用反向传播算法更新模型参数θ,<>表示矩阵的内积,即两个矩阵相应位置的元素相乘再全部求和。f:经过步骤e优化后的一阶目标检测器对输入图像进行检测,为每个检测框i预测一个置信度分数si和精确框定位,再通过非极大值抑制处理后输出结果。如下表所示,本发明所采用的的ap损失函数对比现有的用在一阶目标检测器上的损失函数的优越性,map,ap50,ap75分别是不同的评价指标。如下表所示,经本发明方法训练后的一阶目标检测器retinanet相比其他一阶目标检测器的优越性,评价指标在pascalvoc上为ap50,在coco上为map。检测器pascalvoc07pascalvoc12cocopfpnet51284.183.739.4refinedet51283.883.537.6retinanet500+ap-loss84.984.542.1如图2所示,本发明对ap损失函数的优化方法对比现有的优化方法的优越性。上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1