一种基于代码修改模式差异的缺陷纠错方法与流程
本发明属于软件维护技术领域,特别涉及一种基于代码修改模式差异的缺陷纠错方法。
背景技术:
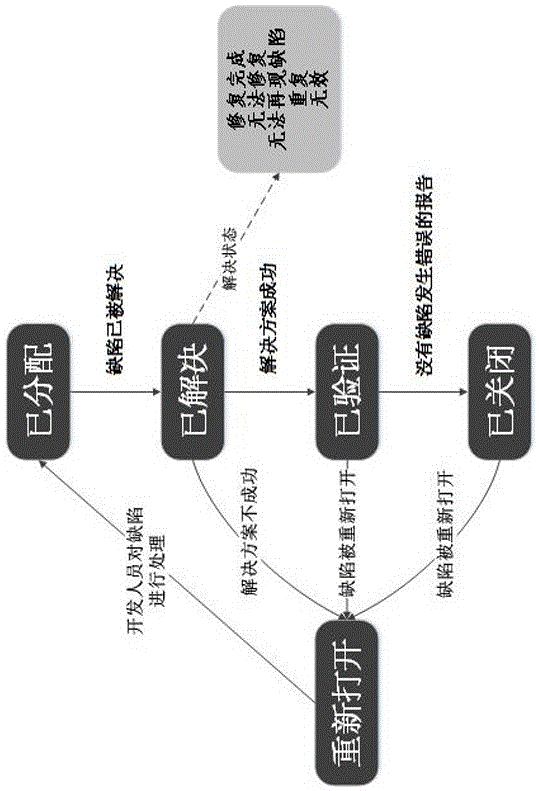
现今,随着科技的不断发展,智能时代的兴起,人们对软件的需求越来越多。当开发人员在软件开发和维护过程中遇到一些不能解决的缺陷问题时,他们往往需要通过检索一些开源的软件缺陷平台来获取更多的缺陷相关信息,如github(一个面向开源及私有软件项目的托管平台)、stackoverflow(一个与程序相关的it技术问答网站)、bugzilla(一个开源的缺陷跟踪系统)等平台。但有时开发人员发现状态为resolved、verified或closed的缺陷报告重新出现了问题,所以状态更改为reopened,如图1。目前,针对软件缺陷平台,已有一些研究内容使开发人员的缺陷修复更加便利,例如版本控制系统和缺陷追踪系统将软件历史库中已有的缺陷报告进行整合,并提供给软件开发人员进行搜查和参考,以此来帮助他们根据得到的缺陷相关信息来进行缺陷修复,但并没有研究是针对检测已修复缺陷是否存在问题的研究。
在缺陷平台中,只有当缺陷报告提出者发现缺陷修复存在问题时才会将缺陷的状态更改为reopened,并进行后续的研究和修复,现有的针对缺陷平台的研究只是为开发人员新提出的缺陷提供一些信息以供参考修复,却忽略了已修复缺陷中是否存在问题这一点。
技术实现要素:
针对现有技术中的缺陷,本发明的目的在于克服现有技术中的不足之处,提供一种基于代码修改模式差异的缺陷纠错方法,解决现有技术中无法检测出已修复缺陷是否存在问题的技术难题,此方法可检测已解决的缺陷可能存在的问题,节省发现缺陷修复问题的时间,增强开发人员的缺陷修复经验。
本发明的目的是这样实现的:基于代码修改模式差异的缺陷纠错方法,包括以下步骤:
(1)通过爬虫获取缺陷检索平台bugzilla中状态为resolved的缺陷报告,包括其title(标题)、description(描述)、缺陷间关系以及代码部分,并进行数据清洗,再按照缺陷报告id(序号)的顺序将以duplicate关系连接起来的缺陷报告形成一个簇;
(2)利用tf-idf(termfrequency–inversedocumentfrequency)算法对各簇内缺陷的title和description进行关键词提取,作为该簇的主题词;
(3)在确认好簇的主题词后,再利用tf-idf算法对其余缺陷报告进行关键词提取,并加入相应关键词的簇中;
(4)对于每个簇中的报告,运用一种称为cdlh的代码克隆检测算法对比每两个报告提交的源代码,并得到代码克隆对,查找出每个缺陷报告中有源代码克隆部分的diff信息,并分别对每份diff信息做修改模式差异图;
(5)计算差异比例,若差异比例不小于65~75%,则认为两者大多做了同种修改,则其余缺陷的修改可能存在问题,并将有修复问题的缺陷发送给报告提出者进行重新检验、修复。
本发明中通过将缺陷平台中状态为resolved(已解决)的缺陷报告按照duplicate关系形成簇,利用tf-idf算法对各簇提取主题词,再将其余缺陷按照自身的关键词进行匹配和归类,这种方法可以将缺陷报告进行基于关键词的分类,更有利于后期在各簇中查找出代码克隆对;再利用基于语法的代码克隆检测算法检测出完全相同的代码、重命名/参数化的代码、几乎相同的代码以及语义相似的代码,使用这种方法可以更全面地检测出代码克隆对;在检测出代码克隆对后,对diff(修改对比代码)信息做修改模式差异图,,存在差异的缺陷报告则可能成为修改方式有问题的缺陷,对已有的缺陷报告进行纠错,可以帮助开发人员更快速便捷地查找出已修改缺陷存在的问题,增强开发人员的缺陷修复经验,提高缺陷检索的有效性和高效性;可应用于给已解决的缺陷问题纠错的工作中。
为了进一步实现关键词的提取,所述步骤(2)中,提取关键词的具体步骤为:tf-idf算法由tf和idf两部分组成,tf是对文本中各个词的出现进行频率统计,而idf是用来赋予每个词特定的权重,分别计算两个值之后,将两者相乘得到tf-idf值,并对文档中每个词的值进行排序,选取其中值最高的几个作为主题词。
为了进一步实现是否为代码克隆对的判定,所述步骤(4)中,判断两个缺陷报告中的两段代码是否是代码克隆对的步骤具体的为,
(401)输入原始代码片段,并将其转化为ast;
(402)使用基于ast的lstm来获得每个代码片段的实值表示;
(403)通过哈希函数将步骤(402)中得到的实值编码转化为二进制哈希码;
(404)给定一对哈希代码
其中,ai和aj为两个哈希表示的代码段,k为汉明空间的维度,m为汉明空间的维度总数,ai,k表示代码段ai在维度k中的哈希值,aj,k为代码段aj在维度k中的哈希值,
为了计算出两个缺陷报告的差异比例,所述步骤(5)中,差异比例的计算公式具体的为:
其中,
附图说明
图1为本发明中bugzilla平台缺陷报告的状态转化图。
图2为本发明的流程示意图。
图3为本发明中举出的bug报告示例截图。
图4为本发明的示例中bugzilla平台归类到簇中的缺陷图。
图5为本发明的示例中一个bug的diff信息截图。
图6为本发明的示例中另一个bug的diff信息截图。
图7为本发明的示例中diff信息修改模式差异图。
具体实施方式
如图2所示的基于代码修改模式差异的缺陷纠错方法,包括以下步骤:
(1)通过爬虫获取缺陷检索平台bugzilla中状态为resolved的缺陷报告,包括其title(标题)、description(描述)、缺陷间关系以及代码部分,并进行数据清洗,再按照缺陷报告id(序号)的顺序将以duplicate(重复)关系连接起来的缺陷报告形成一个簇;
(2)利用tf-idf(termfrequency–inversedocumentfrequency)算法对各簇内缺陷的title和description进行关键词提取,作为该簇的主题词;
(3)在确认好簇的主题词后,再利用tf-idf算法对其余缺陷报告进行关键词提取,并加入相应关键词的簇中;
(4)对于每个簇中的报告,运用一种称为cdlh的代码克隆检测算法对比每两个报告提交的源代码,并得到代码克隆对,查找出每个缺陷报告中有源代码克隆部分的diff信息,并分别对每份diff信息做修改模式差异图;
(5)根据差异比例计算公式,若差异比例不小于65~75%,则认为两者大多做了同种修改,则其余缺陷的修改可能存在问题,并将有修复问题的缺陷发送给报告提出者进行重新检验、修复;
差异比例的计算公式具体的为:
其中,
步骤(2)中,提取关键词的具体步骤为:tf-idf算法由tf(词频)和idf(逆文本词频)两部分组成,tf是对文本中各个词的出现进行频率统计,而idf是用来赋予每个词特定的权重,分别计算两个值之后,将两者相乘得到tf-idf值,并对文档中每个词的值进行排序,选取其中tf-idf值最高的几个作为主题词。
步骤(4)中,判断两个缺陷报告中的两段代码是否是代码克隆对的步骤具体的为,
(401)输入原始代码片段,并将其转化为ast(抽象语法树);
(402)使用基于ast的lstm(长短期记忆网络,是一种时间递归神经网络,能够学习长的依赖关系)来获得每个代码片段的实值表示;
(403)通过哈希函数将步骤(402)中得到的实值编码转化为二进制哈希码,使得克隆对的代码片段在汉明空间(hammingspace)中的汉明距离(hammingdistance)能够彼此接近,以此方便判断两段代码是否是克隆代码对;
(404)给定一对哈希代码
其中,ai和aj分别为两个哈希表示的代码段,k为汉明空间的维度,m为汉明空间的维度总数,ai,k表示代码段ai在维度k中的哈希值,aj,k为代码段aj在维度k中的哈希值,
本发明中通过将缺陷平台中状态为resolved(已解决)的缺陷报告按照duplicate关系形成簇,利用tf-idf算法对各簇提取主题词,再将其余缺陷按照自身的关键词进行匹配和归类,这种方法可以将缺陷报告进行基于关键词的分类,更有利于后期在各簇中查找出代码克隆对;再利用基于语法的代码克隆检测算法检测出完全相同的代码、重命名/参数化的代码、几乎相同的代码以及语义相似的代码,使用这种方法可以更全面地检测出代码克隆对;在检测出代码克隆对后,对diff(修改对比代码)信息做修改模式差异图,存在差异的缺陷报告则可能成为修改方式有问题的缺陷,对已有的缺陷报告进行纠错,可以帮助开发人员更快速便捷地查找出已修改缺陷存在的问题,增强开发人员的缺陷修复经验,提高缺陷检索的有效性和高效性;可应用于给已解决的缺陷问题纠错的工作中。
下面给出具体实施例对本发明作进一步说明。
如图3所示为bugzilla平台中的一个缺陷报告,bug#1215247的缺陷报告中,duplicate关系的缺陷有bug#1215252和bug#1280804,且这两个缺陷报告没有duplicate关系的缺陷,所以这三个缺陷暂时成为一个簇;使用tf-idf算法对于图3中缺陷形成的簇进行关键词的提取,可以得到关键词ecmascriptinternationalizationapi,并将其作为该簇的主题词;平台中一些缺陷通过关键词归类到主题词为ecmascriptinternationalizationapi的簇,如图4为归类到簇中的缺陷示例,图5和图6分别为bug#864843和bug#866301经过对比中源代码相似的diff信息;为了方便社会公众理解如何判断克隆代码对,给出以下示例,图5中的94行(ai)和图6中的90行(aj)均为:case“$os_target”in,则用哈希表示的ai为[1,1,1],用哈希表示的aj为[1,1,1],则
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!