基于数据流架构的快速傅里叶变换方法、系统和存储介质与流程
本发明涉及计算机体系结构领域,特别涉及一种基于数据流架构的快速傅里叶变换方法、系统和存储介质。
背景技术:
作为数字计算机之父,20世纪30年代中期,美国科学家冯·诺依曼提出,抛弃十进制,采用二进制作为数字计算机的数制基础。同时,他还提出预先编制计算程序,然后由计算机来按照人们事前制定的计算顺序来执行数值计算工作。人们把冯·诺依曼的这个理论称为冯·诺依曼体系结构,把利用这种概念和原理设计的电子计算机系统统称为“冯·诺依曼型结构”计算机。从最初的计算机到当前最先进的计算机都采用的是冯诺依曼体系结构。
冯·诺依曼结构处理器具有以下几个特点:必须有一个存储器;必须有一个控制器;必须有一个运算器,用于完成算术运算和逻辑运算;必须有输入设备和输出设备,用于进行人机通信。另外,程序和数据统一存储并在程序控制下自动工作。
根据冯·诺依曼体系结构构成的计算机,必须具有如下功能:把需要的程序和数据送至计算机中;必须具有长期记忆程序、数据、中间结果及最终运算结果的能力;能够完成各种算术、逻辑运算和数据传送等数据加工处理的能力;能够按照要求将处理结果输出给用户。
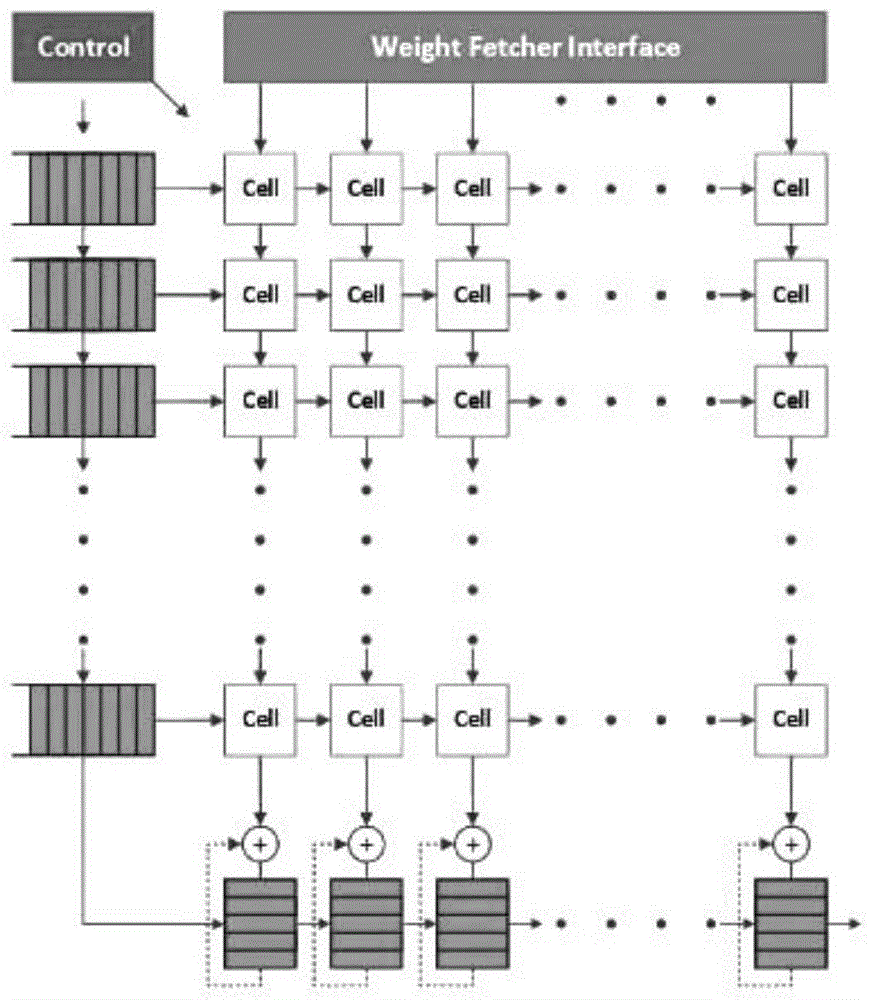
与之形成强烈对比的是数据流结构多核处理器,如图1所示的google的tpu,指令的执行依靠数据来驱动,一旦操作数齐备该条指令就可以执行,利用图扩展的方式,规范不同指令之间的依赖关系,可以使得数据在不同指令之间流动起来。使用这种方式,提前将指令映射到各处理单元(pe),并设定好指令之间的依赖关系,将不再需要额外逻辑,指令执行完毕后,自动送给依赖关系指定的后续指令。
相对于控制流结构,数据流结构不存在指令计数器,指令启动执行的时机取决于操作数具备与否,并且执行顺序由指令间的依赖关系决定。换言之,只要有足够多的处理单元(pe),凡是相互间不存在数据相关的指令,都可以并行执行,极大程度上提高了指令的并行性和处理器结构的浮点利用率。另外,数据流指令之间直接通信,不再需要共享寄存器堆或者共享缓存来实现数据交互,减少了访存次数,提高了存储带宽的有效利用率。同时,数据流计算模式中的执行单元都相对简单,没有分支预测逻辑、乱序执行控制逻辑、重排序队列、保留站等复杂控制逻辑和存储单元,因此数据流执行单元的集成度较高,具有更高能效比。
传统的控制流处理器cpu能够提供各种通用计算但由于内存瓶颈以及指令计数器的影响,对于某种高性能计算(如快速傅立叶变换)性能并不高,如今设计各种专用计算加速器已经成为一种趋势,通用处理器并不能对所有计算保证较高的性能。
现有技术中该项缺陷是由控制流架构本身特点导致的,仅考虑计算的通用性,没有考虑特定高性能计算数据的并行处理及数据之间的复用。
技术实现要素:
针对上述问题,发明人经过对数据流架构的研究发现,解决该项缺陷可以利用数据流结构控制逻辑简单、单指令多数据执行方式、并行度高的特点,设计一种专用的多核处理器指令映射方法。
具体来说,本发明公开了一种基于数据流架构的快速傅里叶变换方法,其中包括:
步骤1、获取待快速傅里叶变换的x个源操作数,并获取具有y个处理单元的多核数据流处理器;
步骤2、各处理单元根据该源操作数的码位倒置顺序表,从该x个源操作数中按照码位倒置顺序载入2(log2x-log2y)个源操作数和旋转因子,以在处理单元本地完成log2x-log2y层蝶形运算,得到运算结果;
步骤3、设运算层数q=1;
步骤4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表,序列表中有一位标识位,初始化所有处理单元标识位都为true;
步骤5、在序列表中选择标号最小且标识位为true的处理单元pei,将其与编号为i+2q-1的处理单元构成交换对,并将该交换对中两个pe的标志位更改为false;
步骤6、循环该步骤5直到序列表中所有处理单元标识位均为false,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
步骤7、循环执行该步骤4到该步骤6直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
该基于数据流架构的快速傅里叶变换方法,其中该典型蝶形运算为:
x1[i]+x1[j]·ω=x2[i]
x1[i]-x1[j]·ω=x2[j]
式中x1[i]和x1[j]分别代表参与一次蝶形运算的两个输入点,ω代表旋转因子,x2[i]和x2[j]分别代表一次蝶形运算得到的两个结果。
该基于数据流架构的快速傅里叶变换方法,其中源操作数的数量x与处理单元的数量y均为2的幂次方。
该基于数据流架构的快速傅里叶变换方法,其中将该步骤4到该步骤7替换为如下步骤:
步骤s4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表;
步骤s5、交换规则编号为1的处理单元pe1和编号为i+2q-1的处理单元构成交换对,在该序列表中删除该交换对;
步骤s6、从该序列表中挑选标号最小的该处理单元pei与编号为i+2q-1的处理单元
步骤s7、循环该步骤6直到该序列表为空,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
步骤s8、循环执行该步骤s4到该步骤s7直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
本发明还公开了一种基于数据流架构的快速傅里叶变换系统,其中包括:
模块1、获取待快速傅里叶变换的x个源操作数,并获取具有y个处理单元的多核数据流处理器;
模块2、各处理单元根据该源操作数的码位倒置顺序表,从该x个源操作数中按照码位倒置顺序载入2(log2x-log2y)个源操作数和旋转因子,以在处理单元本地完成log2x-log2y层蝶形运算,得到运算结果;
模块3、设运算层数q=1;
模块4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表,序列表中有一位标识位,初始化所有处理单元标识位都为true;
模块5、在序列表中选择标号最小且标识位为true的处理单元pei,将其与编号为i+2q-1的处理单元构成交换对,并将该交换对中两个pe的标志位更改为false;
模块6、循环该模块5直到序列表中所有处理单元标识位均为false,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
模块7、循环调用该模块4到模块6直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
该基于数据流架构的快速傅里叶变换系统,其中该典型蝶形运算为:
x1[i]+x1[j]·ω=x2[i]
x1[i]-x1[j]·ω=x2[j]
式中x1[i]和x1[j]分别代表参与一次蝶形运算的两个输入点,ω代表旋转因子,x2[i]和x2[j]分别代表一次蝶形运算得到的两个结果。
该基于数据流架构的快速傅里叶变换系统,其中源操作数的数量x与处理单元的数量y均为2的幂次方。
该基于数据流架构的快速傅里叶变换系统,其中将该模块4到该模块7替换为如下模块:
模块s4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表;
模块s5、交换规则编号为1的处理单元pe1和编号为i+2q-1的处理单元构成交换对,在该序列表中删除该交换对;
模块s6、从该序列表中挑选标号最小的该处理单元pei与编号为i+2q-1的处理单元
模块s7、循环该模块6直到该序列表为空,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
模块s8、循环调用该模块s4到模块s7直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
本发明还公开了一种存储介质,用于存储执行所述快速傅里叶变换方法的程序。
本发明还公开了一种用于所述快速傅里叶变换系统的实施方法。
本发明技术效果包括:
本发明基于数据流结构,在pe阵列上形成了多级运算之间的数据流图,使得不同级之间的中间数据能够复用,大大减少了共享存储的访存次数,同时多个处理单元之间的数据没有相关依赖,可以并行执行多个蝶形运算,大大提高了运算效率和部件利用率。
附图说明
图1为tpu结构图;
图2为快速傅立叶变换算法流程图;
图3为一次蝶形运算指令示意图;
图4为32点按时间抽取快速傅立叶变换码位倒置表;
图5为一次蝶形运算数据流图;
图6为32点快速傅立叶变换示意图;
图7为单个pe执行一个蝶形运算示意图;
图8为单个pe执行两个蝶形运算示意图;
图9为单个pe执行四个蝶形运算示意图;
图10为两个pe数据交换示意图;
图11为四个pe数据交换示意图;
图12为八个pe数据交换示意图;
图13为十六个pe数据交换示意图;
图14为pe编号示意图;
图15为实施例中第0时刻的pe操作图;
图16为实施例中第1时刻的pe操作图;
图17为实施例中第2时刻的pe操作图;
图18为本实施例中第3时刻的pe操作图;
图19为本实施例中第4时刻的pe操作图;
图20为本实施例中第5时刻的pe操作图。
具体实施细节
本发明的目的是解决(克服)上述现有技术的没有考虑特定运算的数据复用及并行性,导致效率不高问题,提出了一种基于数据流结构的快速傅立叶实现方法,能够利用数据流结构的优越性,提高专用高性能算法的计算效率。
本发明关键点包括:
1、在快速傅里叶变换中,程序是通过三层循环来实现的。最外层循环控制快速傅里叶变换的级数,中层循环控制每一级里需要进行蝶形运算的组数,最内层循环控制每一组里蝶形运算的个数。在每一级的蝶形运算中,不同分组使用不同旋转因子,只有将相同旋转因子的分组计算完成后,才能进入下一分组的蝶形运算。当某一级所有分组计算完毕,最外层循环下移一级,进行下一层的蝶形运算,直到全部计算完毕。快速傅立叶变换算法流程图如图2所示。
2、快速傅立叶变换的核心程序是蝶形运算,每一次蝶形运算称为一次任务(task)。每一次蝶形运算需要由以下三种指令组成:载入(load)指令、运算指令、复制(copy)指令。对于load指令,由指令码、内存地址、寄存器号组成,将源数据从指定内存地址load到指定寄存器号。对于运算指令,由指令码、源操作数寄存器号、目的寄存器号组成,将源操作数从寄存器取出,计算完成后,结果保存至目的寄存器。对于copy指令,由源寄存器号、目的寄存器号组成,将本pe上某一寄存器的结果,复制至目的pe上的某一寄存器。不同task之间通过图扩展的方式,规定不同pe之间的依赖关系,确保数据的流动性。最后一级的蝶形运算则将copy指令换成保存(store)指令,将运算的最终结果保存回内存。一次蝶形运算的指令示意图如图3所示。
3、对于按照时间抽取采样点的快速傅立叶变换,如果要保证输出是顺序的,则其输入并不能够按照这个顺序,这种顺序看似毫无规律,但是当用二进制表示样点下标时,这恰好是“码位倒置”的结果。对于32点按时间抽取的快速傅立叶变换,其码位倒置表如图4所示,这种倒置关系可以在运算单元pe从内存中读取源操作数的时候处理。
4、在将一次蝶形运算流程图转换为数据流图时,需要注意的是参与运算的采样点和旋转因子实质上都是复数,分别由实部和虚部参与运算得到最终结果。以一次典型蝶形运算为例,其原型为:
x1[i]+x1[j]·ω=x2[i]
x1[i]-x1[j]·ω=x2[j]
式中x1[i]和x1[j]分别代表参与一次蝶形运算的两个输入点,ω代表旋转因子,x2[i]和x2[j]分别代表一次蝶形运算得到的两个结果。如前面所提到的,每一个点都是复数,包括实部real和虚部image,将两个原始公式按照复数运算法则展开后,即得到下面的四个公式。其中下标为real代表是某个点的实部,下标为image代表是某个点的虚部。
分别将其按照实部和虚部展开参与运算,展开式为:
x1[i].real+(x1[j].real*ω.real-x1[j].image*ω.image)=x2[i].real
x1[i].image+(x1[j].real*ω.image+x1[j].image*ω.real)=x2[i].image
x1[i].real-(x1[j].real*ω.real-x1[j].image*ω.image)=x2[j].real
x1[i].image-(x1[j].real*ω.image+x1[j].image*ω.real)=x2[j].image
将以上公式用数据流的形式表现出来,就得到一次蝶形运算的数据流图,如图5所示。
5、在多核处理器的每一个pe中,都存储有需要执行的指令集合,一个算法在多核处理器上执行,需要将算法的指令集分块映射在处理器阵列中。本发明提出了一种“对于x点快速傅里叶变换映射至y个pe的方法和数据流动方式”,此处约定x与y均为2的幂次方,如果x不是2的幂次方,可通过补零等方式调整,对于pe阵列的个数,本发明仅针对2的幂次方个pe阵列提出。
首先,对于x点的快速傅里叶变换,会进行log2x层(级)计算,每一层进行x/2个蝶形运算,为了使pe之间负载均衡且时间均等,每个pe在每一层需要承担x/2y个蝶形运算,考虑层数,每个pe总共承担x/2y×log2x个蝶形运算,在每一层中,对蝶形运算进行分组,第i层可被分为x/2i组,每组包括2i-1个蝶形运算。如图6所示的32点快速傅里叶变换中,总共进行了五级计算,每一级包括16个蝶形运算,每个pe在每一层承担1个蝶形运算。在第一层,共包括16组,每组一个蝶形运算,在第二层,共有8组,每组2个蝶形运算,在最后一层,共有1组,16个蝶形运算。
由此单个pe在每一层承担的蝶形运算数直接影响本pe可单独执行完成的层数,此处可单独执行完成指pe通过复用上一层的本地结果,即可完成当前层全部结果的运算,而不需要与其他pe交互。下面详细说明。
如果pe0和pe1在第一层分别只执行一个蝶形运算,那么在第二层两个pe就需要交换数据完成运算了,即当x/2y=1时,单个pe可独立完成的层数只有一层。如图7所示。
如果pe0和pe1在第一层分别执行两个蝶形运算,那么在第二层pe可复用自己第一层两个蝶形运算的结果,继续独立完成第二层的运算,在第三层时,两个pe交换数据完成运算。即当x/2y=2时,单个pe可独立完成的层数为两层。如图8所示。
如果pe0和pe1在第一层分别执行四个蝶形运算,那么在第二层,pe可分别复用自己第一层前两个和后两个蝶形运算的结果,独立完成第二层运算,在第三层,pe可继续复用自己第二层四个蝶形运算的结果,完成第三层运算,在第四层时,才开始pe之间交互完成蝶形运算。即当x/2y=4时,单个pe可独立完成的层数为三层。如图9所示。
以上过程同样可推定,假设pe在第一层承担x/2y个蝶形运算,pe可独立完成蝶形运算的层数为q,那么应有2q-1=x/2y,即单个pe承担的蝶形运算个数,恰好等于某一层一组蝶形运算个数,即有q=log2x-log2y。
综上,对于x点快速傅里叶变换映射至y个pe上,快速傅里叶变换的第一层至(log2x-log2y)层都可在本地pe上计算完成而不需要pe之间的数据传输。
下面定义pe间的数据传输规则,因为仍有log2x-(log2x-log2y),即log2y层需要数据传输,可见需要数据传输的层数仅与pe个数有关,而与傅里叶变换的输入个数无关。为了表达方便,后面将需要进行数据传输的层重新排序,后面所称的第一层指的是需要数据传输的第一层,而不是整个数据流图的第一层。
概括来说,pei将依次与
当pe=2,进行任意点的快速傅里叶变换,仅需要一层数据传输,此时q=1,两个pe互换数据。即
当pe=4,进行任意点的快速傅里叶变换,pe之间会交互最后两层数据,此时q=1,2。在第一层,
当pe=8,进行任意点的快速傅里叶变换,pe之间会交互最后三层数据,此时q=1,2,3。在第一层,
当pe=16,进行任意点的快速傅里叶变换,pe之间会交互最后四层数据,此时q=1,2,3,4。在第一层,
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
其中包括:
步骤1、获取待快速傅里叶变换的x个源操作数,并获取具有y个处理单元的多核数据流处理器;
步骤2、各处理单元根据该源操作数的码位倒置顺序表,从该x个源操作数中按照码位倒置顺序载入2(log2x-log2y)个源操作数和旋转因子,以在处理单元本地完成log2x-log2y层蝶形运算,得到运算结果;
步骤3、设运算层数q=1;
步骤4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表,序列表中有一位标识位,初始化所有处理单元标识位都为true;
步骤5、在序列表中选择标号最小且标识位为true的处理单元pei,将其与编号为i+2q-1的处理单元构成交换对,并将该交换对中两个pe的标志位更改为false;
步骤6、循环该步骤5直到序列表中所有处理单元标识位均为false,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
步骤7、循环执行该步骤4到该步骤6直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
或将该步骤4到该步骤7替换为如下步骤:
步骤s4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表;
步骤s5、交换规则编号为1的处理单元pe1和编号为i+2q-1的处理单元构成交换对,在该序列表中删除该交换对;
步骤s6、从该序列表中挑选标号最小的该处理单元pei与编号为i+2q-1的处理单元
步骤s7、循环该步骤6直到该序列表为空,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
步骤s8、循环执行该步骤s4到该步骤s7直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
下述实施例以32点,按时间抽取为例,“点”即输入,每个点都是复数,包括实部和虚部。由于32点快速傅立叶变换每一级需要16个蝶形运算,且同一级的蝶形运算之间没有数据依赖,本实施例以16个pe为例进行说明,pe之间的箭头代表了copy指令的数据流向。pe标号如图14所示。
步骤601:在0时刻,16个pe主要完成load操作,包括两部分,一是load本pe需要的两个源操作数,需要注意的是,由于码位倒置的关系,并非0号peload出n[0]和n[1]两个源操作数,在0时刻不同pe执行的具体task如图15所示;二是load出本pe上后续所需要的所有旋转因子ω并保存至本地寄存器,旋转因子可通过查表得到,此处指将查找好的旋转因子load进本地寄存器供后续使用。
步骤602:在1时刻,如图16所示,运算单元pe利用两个源操作数和旋转因子进行一次蝶形运算,获得结果并通过copy指令完成数据在pe之间的流动。以pe0和pe1为例,pe0获取到了n[0]、n[16]和ω,计算出结果a[0]和a[1],将根据交换规则将运算结果a0拷贝至pe1;pe1获取到了n[8]、n[24]和ω,计算出结果b[0]和b[1],将运算结果b1拷贝至pe0。
步骤603:在2时刻,如图17所示,以前四个pe为例,pe0利用上一时刻计算出的a[1]和来自pe1的b[1]以及旋转因子,计算出这一时刻的结果a[0]和a[1],并将运算结果a[1]拷贝至pe2;pe1利用上一时刻计算出的b[0]和来自pe0的a[0]以及旋转因子,计算出这一时刻的结果b[0]和b[1],并将运算结果b[1]拷贝至pe3;pe2利用上一时刻计算出的c[1]和来自pe3的d[1]以及旋转因子,计算出这一时刻的结果c[0]和c[1],并将运算结果c[0]拷贝至pe0;pe3利用上一时刻计算出的d[0]和来自pe2的c[0]以及旋转因子,计算出这一时刻的结果d[0]和d[1],并将运算结果d[0]拷贝至pe1。
步骤604:在3时刻,如图18所示,以前八个pe为例,pe0利用上一时刻计算出的a[0]和来自pe2的c[0]以及旋转因子,计算出这一时刻的结果a[0]和a[1],并将运算结果a[1]拷贝至pe4;pe1利用上一时刻计算出的b[0]和来自pe3的d[0]以及旋转因子,计算出这一时刻的结果b[0]和b[1],并将运算结果b[1]拷贝至pe5;pe2利用上一时刻计算出的c[1]和来自pe0的a[1]以及旋转因子,计算出这一时刻的结果c[0]和c[1],并将运算结果c[1]拷贝至pe6;pe3利用上一时刻计算出的d[1]和来自pe1的b[1]以及旋转因子,计算出这一时刻的结果d[0]和d[1],并将运算结果d[1]拷贝至pe7;pe4利用上一时刻计算出的e[0]和来自pe6的g[0]以及旋转因子,计算出这一时刻的结果e[0]和e[1],并将运算结果e[0]拷贝至pe0;pe5利用上一时刻计算出的f[0]和来自pe7的h[0]以及旋转因子,计算出这一时刻的结果f[0]和f[1],并将运算结果f[1]拷贝至pe1;pe6利用上一时刻计算出的g[1]和来自pe4的e[1]以及旋转因子,计算出这一时刻的结果g[0]和g[1],并将运算结果g[0]拷贝至pe2;pe7利用上一时刻计算出的h[1]和来自pe5的f[1]以及旋转因子,计算出这一时刻的结果h[0]和h[1],并将运算结果h[0]拷贝至pe3。
步骤605:在4时刻,如图19所示,每个pe利用自己上一级产生的结果以及上一时刻来自其他pe的结果和旋转因子,完成第四级的十六个蝶形运算,每个pe完成运算后,将结果的一部分与其他pe交换,完成数据的流动,过程与前面类似,不再赘述。
步骤606:在5时刻,如图20所示,pe完成最后一级的蝶形运算后将结果存回内存。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还提出了一种基于数据流架构的快速傅里叶变换系统,其中包括:
模块1、获取待快速傅里叶变换的x个源操作数,并获取具有y个处理单元的多核数据流处理器;
模块2、各处理单元根据该源操作数的码位倒置顺序表,从该x个源操作数中按照码位倒置顺序载入2(log2x-log2y)个源操作数和旋转因子,以在处理单元本地完成log2x-log2y层蝶形运算,得到运算结果;
模块3、设运算层数q=1;
模块4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表,序列表中有一位标识位,初始化所有处理单元标识位都为true;
模块5、在序列表中选择标号最小且标识位为true的处理单元pei,将其与编号为i+2q-1的处理单元构成交换对,并将该交换对中两个pe的标志位更改为false;
模块6、循环该模块5直到序列表中所有处理单元标识位均为false,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
模块7、循环调用该模块4到模块6直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
该基于数据流架构的快速傅里叶变换系统,其中该典型蝶形运算为:
x1[i]+x1[j]·ω=x2[i]
x1[i]-x1[j]·ω=x2[j]
式中x1[i]和x1[j]分别代表参与一次蝶形运算的两个输入点,ω代表旋转因子,x2[i]和x2[j]分别代表一次蝶形运算得到的两个结果。
该基于数据流架构的快速傅里叶变换系统,其中源操作数的数量x与处理单元的数量y均为2的幂次方。
该基于数据流架构的快速傅里叶变换系统,其中将该模块4到该模块7替换为如下模块:
模块s4、将该y个处理单元标号分别对应1至y,保存各处理单元与标号的对应关系构成序列表;
模块s5、交换规则编号为1的处理单元pe1和编号为i+2q-1的处理单元构成交换对,在该序列表中删除该交换对;
模块s6、从该序列表中挑选标号最小的该处理单元pei与编号为i+2q-1的处理单元
模块s7、循环该模块6直到该序列表为空,各交换对包括的处理单元间交换该运算结果以完成一层蝶形运算,该运算层数q自加1;
模块s8、循环调用该模块s4到模块s7直到该运算层数q为log2x时,停止循环并输出当前该运算结果作为傅里叶变换结果。
模块s4到s8和模块4到7的区别在于,前者使用删除的方式标记已构成的交换对,后者以标志位的方式标记已构成的交换对,两者的相同点在于目的均是为了确定交换对。
本发明还提出了一种存储介质,用于存储执行所述快速傅里叶变换方法的程序。
本发明还提出了一种用于所述快速傅里叶变换系统的实施方法。
- 还没有人留言评论。精彩留言会获得点赞!