基于注意力机制与逻辑回归的长短期记忆网络预测方法与流程
本发明涉及化工生产的
技术领域:
,尤其涉及一种基于注意力机制与逻辑回归的长短期记忆网络预测方法。
背景技术:
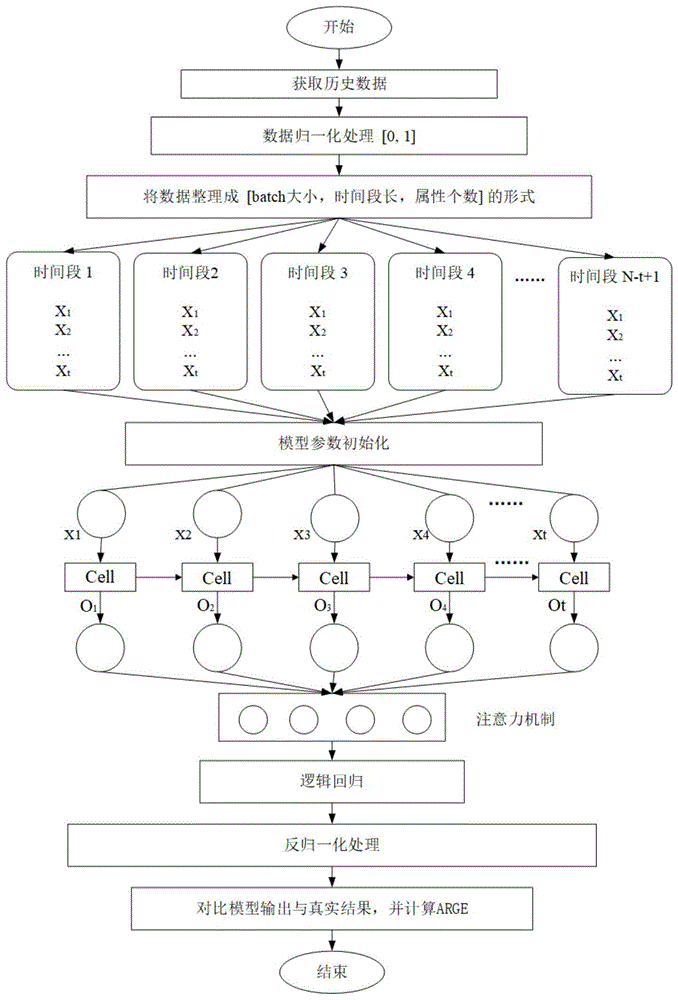
:乙烯生产工业已经成为国内石化工业的龙头产业,其产量的输出已经成为判断一个国家工业发展水平的主要标志之一。据统计,生产1000,000吨乙烯需要约320万吨石油烃,其中18%(约576,000吨)被处理能量消耗,因此国内乙烯行业存在较大的能效提升空间。乙烯的能源消耗费用占乙烯装置操作成本的50%以上,因此建立乙烯装置生产预测模型对于降低乙烯工业能耗有着很好的指导意义。另外,乙烯装置对于实现节能、低碳经济和绿色国内生产总值(gdp)这一总体目标具有直接影响。然而,复杂化工生产数据具有高维、不确定性以及噪声等特点,导致难以直接控制原材料消耗,无法保证复杂化工生产的产品质量。技术实现要素:为解决现有技术存在的局限和缺陷,本发明提供一种基于注意力机制与逻辑回归的长短期记忆网络预测方法,包括:获取乙烯生产数据;对所述乙烯生产数据进行归一化处理;对归一化之后的乙烯生产数据进行整理形成[b,s,d]的形式,其中b表示批处理的大小,s表示输入数据的时长,d表示数据属性的个数;使用长短期记忆网络模型对整理之后的乙烯生产数据进行训练,所述长短期记忆网络模型的输入门在t时刻的计算公式如下:所述长短期记忆网络模型的遗忘门在t时刻的计算公式如下:所述长短期记忆网络模型的输出门与输出在t时刻的计算公式如下:其中,wil与分别代表输入数据-输入门、输入数据-遗忘门之间的权重矩阵,wcl与分别代表上一时刻的状态-输入门、上一时刻的状态-遗忘门之间的权重矩阵,wiw与wcw分别代表输入数据-输出门、上一时刻的状态-输出门之间的权重矩阵,wic代表输入层的初始权重矩阵,wh*与w*h分别代表与隐层相关的权重矩阵;根据注意力机制对多个历史时间点的结果进行加权计算,以获得不同时间点的数据依赖关系;使用基于逻辑回归的非线性变换拟合乙烯生产数据,以获得最终的预测输出。可选的,所述根据注意力机制对多个历史时间点的结果进行加权计算的步骤包括:根据注意力机制相关公式对多个历史时间点的结果进行加权计算,所述注意力机制相关公式如下:ut=tanh(wwht+bw)(12)其中,ww与uw是注意力机制的权重矩阵,ut是第一次加权计算的结果,bw代表偏置项,ht代表注意力机制的输入,αt是作用在不同时刻的输出ht上的权重。可选的,所述使用基于逻辑回归的非线性变换拟合乙烯生产数据的步骤包括:使用逻辑回归相关公式拟合乙烯生产数据,所述逻辑回归相关公式如下:z=wxt+b(15)可选的,还包括:使用均方误差公式计算误差,所述均方误差公式如下:可选的,使用均方根误差公式和平均相对误差公式对输出结果进行评估,所述均方根误差公式和所述平均相对误差公式如下:其中,分别代表真实结果与预测的输出结果,n是样本总数。本发明具有下述有益效果:本发明提供的基于注意力机制与逻辑回归的长短期记忆网络预测方法,包括:获取乙烯生产数据,对所述乙烯生产数据进行归一化处理,对归一化之后的乙烯生产数据进行整理,使用长短期记忆网络模型对整理之后的乙烯生产数据进行训练,根据注意力机制对多个历史时间点的结果进行加权计算,以获得不同时间点的数据依赖关系,使用基于逻辑回归的非线性变换拟合乙烯生产数据,以获得最终的预测输出。本发明提供的技术方案能够提高乙烯生产数据的时序特征进而提高长短期记忆网络模型的性能,从而实现乙烯生产过程的准确预测,提升乙烯生产能力,实现节能减排的目的。附图说明图1为本发明实施例一提供的长短期记忆网络预测方法的流程图。图2为本发明实施例一提供的不同模型对乙烯产量预测结果的示意图。图3为本发明实施例一提供的长短期记忆网络预测方法对乙烯产量的预测结果与真实结果的误差示意图。图4为本发明实施例一提供的乙烯生产优化方案示意图。具体实施方式为使本领域的技术人员更好地理解本发明的技术方案,下面结合附图对本发明提供的基于注意力机制与逻辑回归的长短期记忆网络预测方法进行详细描述。实施例一近年来,出现了许多用来解决复杂化工能效问题的方法,例如经典的主元分析方法、数据包络、改进的dea交叉模型、层析分析法以及改进的基于模糊c均值的层次分析法等都被用来分析能效水平,降低能耗,提高能源利用率。同时,一些基于神经网络的方法也被用于分析能效问题,例如基于样本聚类的极限学习机、自组织极限学习机、自联想神经网络等方法都被用来解决工业生产中遇到的生产效率和能源利用率等问题。通过对原始问题进行建模将其转换成类似数学拟合的问题来实现对工业生产中一些变量的预测的目的,并以此为参考得到改进的措施。随着人工智能的发展以及计算性能的提升,深度学习也得到了越来越广泛的研究与应用,目前为止在一些领域已经取得了显著的成就,比如基于卷积神经网络的深度学习模型在图像处理以及视觉领域的成就已经非常突出,甚至已经超越了人类。擅长处理序列数据的循环神经网络以及其改进型的长短期记忆网络在语音识别、文本处理、机器翻译等领域均取得了很好的结果。除此之外,深度学习也被用来处理化工过程中的故障识别与诊断、医学药物发现、电力负荷预测等领域,而且与其他方法的效果相比均有较大的提升。乙烯生产数据均是由设备在不同的时间点所采集而来,因此是典型的时序数据,基于这种数据特征,本实施例提出了一种基于注意力机制与逻辑回归的深度学习模型,用来实现对复杂化工过程中乙烯产量的准确预测,作为生产决策的依据。首先将采集的乙烯数据进行归一化处理,整理成模型输入所需要的形式,然后通过基于深度学习的长短期记忆网络提取数据之间的时序性特征,得到不同时刻的输出,采用注意力机制获取不同时刻数据之间的依赖关系,通过逻辑回归得到最终的预测输出。对于新的后续采集的乙烯数据,仍然采用相同的方式进行预处理,然后放到模型中即可得到预测结果。图1为本发明实施例一提供的长短期记忆网络预测方法的流程图。如图1所示,本实施例首先将数据进行归一化预处理并整理成模型所需要的格式,然后送入模型进行训练和预测。具体来说,本实施例将一段时间内的乙烯生产数据进行归一化预处理至0到1的之间:其中,与分别表示一个属性数据的最小值与最大值,表示t时刻第个属性的数据,表示归一化的结果。本实施例对于模型的输出也要进行反归一化处理:本实施例对工业数据进行建模之前还需要将其转换成模型所需要的特定的格式,实现利用过去一段时间内的数据来预测当前输出的目标,因此模型的每一次输入为一段时间内的历史数据,输出则为当前时刻的数据。将数据整理成[b,s,d]的形式,其中b表示一个batch的大小,s表示一次输入的数据的时长即s条历史数据,d表示属性的个数。当b=1时,输入形式即为:本实施例中,整理的方式为:从第一条数据开始,连续s条数据作为一次新的输入数据,同样从第二条开始连续s条数据也作为一次新的输入数据,那么对于n条数据,就可以整理成n-s+1条新的输入数据。本实施例构建了一个专门用于处理序列数据的深度学习模型即长短期记忆网络(longshort-termmemory,lstm)用来对工业乙烯数据进行建模,该模型通过输入门、遗忘门、输出门的方式来实现信息流的保护与控制。由于乙烯的生产环境比较复杂且持续生产,因此不同时刻的装置的运行状态对当前的影响也是不同的,因此本实施例在长短期记忆网络模型的基础上结合了注意力机制(attentionmechanism)用于发现不同时刻的数据间的依赖关系,使得预测的结果更加准确。所述长短期记忆网络模型的输入门在t时刻的计算公式如下:所述长短期记忆网络模型的遗忘门在t时刻的计算公式如下:所述长短期记忆网络模型的输出门与输出在t时刻的计算公式如下:其中,wil与分别代表输入数据-输入门、输入数据-遗忘门之间的权重矩阵,wcl与分别代表上一时刻的状态-输入门、上一时刻的状态-遗忘门之间的权重矩阵,wiw与wcw分别代表输入数据-输出门、上一时刻的状态-输出门之间的权重矩阵,wic代表输入层的初始权重矩阵,wh*与w*h分别代表与隐层相关的权重矩阵。注意力机制是相当于为不同时刻的结果进行了加权计算,将当前的结果与之前一段时间的输出建立了关联,使得不同时刻的输出对当前结果的影响是不同的,这也比较符合工业生产的实际情况。根据注意力机制相关公式对多个历史时间点的结果进行加权计算,所述注意力机制相关公式如下:ut=tanh(wwht+bw)(12)其中,ww与uw是注意力机制的权重矩阵,ut是第一次加权计算的结果,bw代表偏置项,ht代表注意力机制的输入,αt是作用在不同时刻的输出ht上的权重。本实施例使用逻辑回归相关公式拟合乙烯生产数据,所述逻辑回归相关公式如下:z=wxt+b(15)本实施例使用均方误差公式计算误差,所述均方误差公式如下:本实施例使用均方根误差公式和平均相对误差公式对输出结果进行评估,所述均方根误差公式和所述平均相对误差公式如下:其中,分别代表真实结果与预测的输出结果,n是样本总数。本实施例提供的基于注意力机制与逻辑回归的长短期记忆网络预测方法,包括:获取乙烯生产数据,对所述乙烯生产数据进行归一化处理,对归一化之后的乙烯生产数据进行整理,使用长短期记忆网络模型对整理之后的乙烯生产数据进行训练,根据注意力机制对多个历史时间点的结果进行加权计算,以获得不同时间点的数据依赖关系,使用基于逻辑回归的非线性变换拟合乙烯生产数据,以获得最终的预测输出。本实施例提供的技术方案能够提高乙烯生产数据的时序特征进而提高长短期记忆网络模型的性能,从而实现乙烯生产过程的准确预测,提升乙烯生产能力,实现节能减排的目的。本实施例选取了2011年至2012年采用同一技术的乙烯装置所采集的数据作为训练数据和测试数据,其中2011年的228条数据作为训练数据,2012年的100条数据作为测试数据。由于乙烯的生产比较复杂,所需条件繁多,本实施例选取了5种主要的因素作为模型的输入:分别是原油消耗量、燃料、水、蒸汽和电力,将乙烯的产量作为输出,单位为吨。通过本实施例提供的模型来实现乙烯装置的产能预测与节能减排的目标,首先根据公式(1)对数据进行归一化预处理,使得每一个变量的取值都在[0,1]之间,然后利用以上介绍的处理方法把数据规整成为[b,s,d]的形式,在本实施例中b=10表示batchsize的大小是10,s=10表示选取之前的10个时间点的数据来对当前时间点的乙烯产量进行预测,d=5表示输入属性的个数,lstm隐层节点数h=100。因此,一次输入数据的维度即为[10,10,5],[10,10,1]。然后将规整后的数据作为lstm模型的输入提取数据的时序性特征,得到不同时刻的输出,此时输出数据维度为[10,10,100],然后将这些输出作为注意力机制的输入得到不同时刻所对应的权重值,再将这些权重作用在不同时刻的输出上,使得不同时刻的结果对最终的结果产生不同的影响,最后通过逻辑回归进行非线性变换得到最终的预测结果,根据公式(2)进行反归一化处理后即可得到当前乙烯产量的预测结果。本实施例使用谷歌开源的用深度学习框架tensorflow来构建整个深度学习模型,具体的神经网络模型参数如表1所示:表1网络模型的参数项目所需数目输入维度[10,10,5],[10,10,1]时间段长10lstm隐层节点100lstm层数1逻辑回归节点数64逻辑回归激活sigmod损失函数mse优化方法adamoptimizer为了验证模型的有效性与优越性,分别与反向传播网络(bp),极限学习机(elm)以及普通的lstm模型在训练集与测试集上的预测结果进行对比,最后得到的结果如表2所示:表2不同模型的训练与测试的结果图2为本发明实施例一提供的不同模型对乙烯产量预测结果的示意图。如图2所示,横坐标代表测试集,纵坐标代表不同模型的预测结果以及真实值。图3为本发明实施例一提供的长短期记忆网络预测方法对乙烯产量的预测结果与真实结果的误差示意图。如图3所示,横坐标代表测试集,纵坐标代表真实值与预测值之间的差值。由表2以及图2可知,本实施例提供的模型的性能明显优于bp、elm以及普通的lstm模型。由此通过该模型可以得到乙烯工艺中乙烯产量的一个相当准确的预测值,此信息可以作为能效水平评估的依据以及提供乙烯生产指导。例如,根据图3得到第97组数据得到乙烯的实际产量要明显低于模型的预期输出,表明此时乙烯生产装置的负荷低,能源利用率低,需要做相应的改进措施来提高能源利用率,以降低能耗水平。图4为本发明实施例一提供的乙烯生产优化方案示意图。为了提高第97组的生产效率,各个变量的变化如图4示,其中横坐标1-5分别代表原油消耗量、燃料、水、蒸汽和电力这5种原料。根据以上调整,原油、燃料和蒸汽的参数消耗量参数应分别增加553、0.42和0.05,同时水和电力的参数分别降低1.16和0.55(为了便于观察,图4将原油变化量缩减了100倍即5.53,而实际变化量为553),根据以上分析与调整,乙烯的产量可以增加约5884吨,因此大大提升了乙烯生产能力和能源利用率,从而实现指导乙烯生产的目标。本实施例提供的基于注意力机制与逻辑回归的长短期记忆网络预测方法,包括:获取乙烯生产数据,对所述乙烯生产数据进行归一化处理,对归一化之后的乙烯生产数据进行整理,使用长短期记忆网络模型对整理之后的乙烯生产数据进行训练,根据注意力机制对多个历史时间点的结果进行加权计算,以获得不同时间点的数据依赖关系,使用基于逻辑回归的非线性变换拟合乙烯生产数据,以获得最终的预测输出。本实施例提供的技术方案能够提高乙烯生产数据的时序特征进而提高长短期记忆网络模型的性能,从而实现乙烯生产过程的准确预测,提升乙烯生产能力,实现节能减排的目的。可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1