一种基于强化学习的网络舆情装置的调度方法与流程
本发明属于自动控制领域,特别涉及一种基于强化学习的网络舆情装置的调度方法。
背景技术:
近年来,互联网发展迅速,作为继电视、广播、报纸之外的第四媒体,已经成为反映社会舆情的一个重要载体。另一方面,由于网络的开放性和虚拟性,网上舆情已经越来越复杂,对现实生活的影响与日俱增,一些重大的网络舆情事件往往对社会产生较大的影响力。对政府部门、公众媒体和大型企业来说,如何加强对网络舆情的及时应对回复,成为网络舆情管理的一大难点。网络舆情装置集群系统即通过构建分布式集群结构的网络舆情装置,来对网络上的舆情进行大规模的应对,引导操作。
如何对构建的分布式集群形式的网络装置进行高效合理的调度,成为了一个具有挑战性的问题,这属于一个系统决策问题。智能决策支持系统的概念提出20多年来,随着决策理论、信息技术、数据库技术、办公自动化、专家系统等相关技术的发展,智能决策系统取得了长足的进展,在许多领域得到应用。智能决策支持系统是以日常业务处理系统的数据为基础,利用数学的或智能的方法,对业务数据进行综合、分析,预测未来业务的变化趋势,在企业发展、市场经营战略等重大问题上为领导层提供决策帮助的计算机系统。近年来企业(包括商业)部门业务处理以及信息管理系统的广泛使用,既为决策支持系统的建立提供了基础,也为它的应用产生了强大的推动力。然而,目前的只能决策系统不能很好地处理以及调度分布式集群结构、以行为导向为基础的资源。
另一方面,近年来,深度强化学习在值函数近似、策略搜索、环境建模这三大方法上取得了突破性进展,业界初步研究表明,深度强化学习方法在各种复杂环境中具有优于传统资源分配方法的潜力。长期以来,大量的文献和专利都集中于对如何提高调度方法精度和调度结果的多样性等性能指标的问题进行深入研究。由Hinton等人于2006年提出深度学习的概念,深度学习(Deep Learning,DL)作为机器学习领域一个重要的研究热点,已经在图像分析、语音识别、自然语言处理、视频分类等领域取得了令人瞩目的成功。DL的基本思想是通过多层的网络结构和非线性变换,组合低层特征,形成抽象的、易于区分的高层表示,以发现数据的分布式特征表示。因此DL方法侧重于对事物的感知和表达。强化学习(Reinforcement Learning,RL)作为机器学习领域另一个研究热点,已经广泛应用于工业制造、仿真模拟、机器人控制、优化与调度、游戏博弈等领域。RL的基本思想是通过最大化智能体(agent)从环境中获得的累计奖赏值,以学习到完成目标的最优策略。因此RL方法更加侧重于学习解决问题的策略。随着人类社会的飞速发展,在越来越多复杂的现实场景任务中,需要利用DL来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自我激励的RL,优化解决问题的策略。
由此,谷歌的人工智能研究团队DeepMind创新性地将具有感知能力的DL和具有决策能力的RL相结合,形成了人工智能领域新的研究热点,即深度强化学习(Deep Reinforcement Learning,DRL)。此后,在很多挑战性领域中,DeepMind团队构造并实现了人类专家级别的agent。这些agent对自身知识的构建和学习都直接来自原始输入信号,无需任何的人工编码和领域知识。因此DRL是一种端对端(end-to-end)的感知与控制系统,具有很强的通用性。其学习过程可以描述为:
(1)在每个时刻agent与环境交互得到一个高维度的观察,并利用DL方法来感知观察,以得到抽象、具体的状态特征表示;
(2)基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作;
(3)环境对此动作做出反应,并得到下一个观察。通过不断循环以上过程,最终可以得到实现目标的最优策略。目前DRL技术在游戏、机器人控制、参数优化、机器视觉等领域中得到了广泛的应用,并被认为是迈向通用人工智能(Artificial General Intelligence,AGI)的重要途径。
技术实现要素:
针对现有技术存在的缺陷,解决如何加强对网络舆情的及时应对回复的技术问题,本发明提供了一种基于强化学习的网络舆情装置的调度方法,包括:
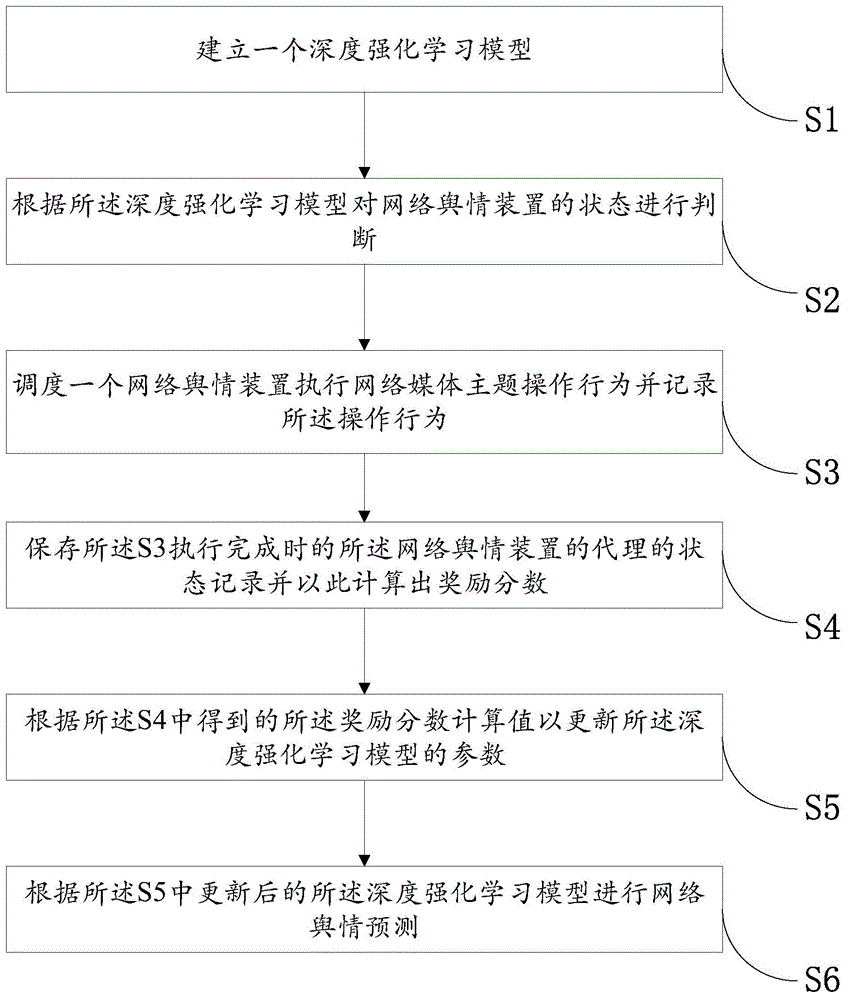
S1:建立一个深度强化学习模型;
S2:根据所述深度强化学习模型对网络舆情装置的状态进行判断;
S3:调度一个网络舆情装置执行网络媒体主题操作行为并记录所述操作行为;
S4:保存所述S3执行完成时的所述网络舆情装置的代理的状态记录并以此计算出奖励分数;
S5:根据所述S4中得到的所述奖励分数计算损失值以更新所述深度强化学习模型的参数;
S6:根据所述S5中更新后的所述深度强化学习模型进行网络舆情预测。
进一步,所述S1中,所述深度强化学习模型为基于DQN的模型,所述深度强化学习模型包括:策略生成网络、代理操作行为、代理状态和代理本次操作的奖励;其中,所述策略生成网络是一个3层前馈神经网络模型
进一步,在所述S3中,装置的操作行为采用日志的方式对每一个操作进行在线记录,所述日志的内容包括:代理节点id、代理的操作行为和代理的操作状态。
进一步,所述S3中,所述网络媒体主题操作行为包括:是否选取当前目标、是否进行转发操作、是否进行点赞操作、是否进行关注操作、是否进行发帖操作和是否进行回复操作。
代理的状态建模为一个向量va=<a1,a2,…,am>,向量的长度为m,m=6;其中每个元素对应了上述的每个操作的内容,是为1,否为0,发布正面意见为1,发布负面意见为0。
进一步,所述S4中,代理的状态至少包括以下之一:上一次转发是否成功、转发前的原帖总转发数量、上一次点赞是否成功、点赞前的总点赞数量、上一次回复是否成功、上一次发帖是否成功、上一次关注是否成功、回复前的原帖总回复数量、当前时间、当前代理网络节点、当前剩余可用代理、当前操作代价、当前路径长度。
将代理的状态建模为一个向量vs=<s1,s2,…,sk>,k为向量长度,k=12;其中,每个元素对应了上述的每个状态的内容;将其中每个元素的值的定义为:成功为1,失败为0。
进一步,所述S5中,强化学习模型的奖励分数的计算定义为:
R=r1+r2+r3+r4;
其中R为奖励总和,rt对应为第t个考核目标,具体对应以下4个考核目标:
r1:操作是否成功,成功为1,失败为-1;
r2:路径长度相比上次的差值;
r3:发布的意见结果对总体的舆论导向的影响程度;
r4:代理的时间损耗log值。
与现有的技术相比,本发明具有以下的优点和有益效果:
1、本发明专门为网络舆论媒体的装置设计的智能调度方法,针对特定领域的专业用户和公司。
2、智能调度方法结合强化学习模型进行建模和调度,从历史数据中以及当前数据中在线灵活学习掌握规律,具有非常好的环境适应性和鲁棒性。
3、本发明采用神经网络模型进行智能决策,自动从输入的状态中学习最佳的行为,相比传统的调度方法,可以降低调度错误率、失误率;另外采用的神经网络模型可以有效解决特征工程的弊端。
4、智能调度方法将舆论媒体装置的各种操作的行为与状态进行合理特征建模,完整覆盖了代理装置所有的行为与状态。
附图说明
图1是本发明的一种基于强化学习的网络舆情装置的调度方法的流程示意图。
具体实施方式
以下描述中,为了说明而不是为了限定,提出了诸如特定装备结构、接口、技术之类的具体细节,以便透彻理解本发明。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
如图1所示,一种基于强化学习的网络舆情装置的调度方法,包括:
S1:建立一个深度强化学习模型;
S2:根据所述深度强化学习模型对网络舆情装置的状态进行判断;
S3:调度一个网络舆情装置执行网络媒体主题操作行为并记录所述操作行为;
S4:保存所述S3执行完成时的所述网络舆情装置的代理的状态记录并以此计算出奖励分数;
S5:根据所述S4中得到的所述奖励分数计算以更新所述深度强化学习模型的参数;
S6:根据所述S5中更新后的所述深度强化学习模型进行网络舆情预测。
本发明中的网络舆情装置指基于强化学习网络的能够自主根据网络舆情进行发帖/回帖的网络舆情分析代理机。包含舆情监测系统的功能、以及智能回帖功能;如分析帖子中的问题,对分析后的内容,根据分析的关键词的数量和含义,选择相应的预先设置的具有匹配关系的帖子,主动将这些帖子发出并引导舆情。
本发明的S5中所述深度强化学习模型的参数包括:目标参数Objective、状态参数State、动作参数Action和奖励参数Reward。
对于网络舆情装置的强化学习模型而言,目标参数为控制网络舆情导向,状态参数为当前网络舆情状态分析的评分,动作参数为发帖/回帖操作,奖励参数为所述奖励分数的参数。
通过神经网络反向传播算法,将计算得到的奖励分数的参数传回所述深度强化学习模型中,根据计算得到的奖励分数的正负数值修正深度强化学习模型中的神经网络的具体参数数值。所述神经网络反向传播算法为本领域技术人员可以知晓的公知技术,在此不做赘述。
通过这种不断的参数修正可以得到一个最优的深度强化学习模型,进而实现进一步的网络舆情预测过程。
所述S6中根据深度强化学习模型进行网络舆情预测的过程包括:
首先对网络舆情数据进行整理,减少样本数量;
之后对网络舆情进行特征提取;
最后将提取后的特征根据参数类型分别输入所述强化学习模型中进行网络舆情预测。
通过本发明可以将有价值的内容可以增加曝光量,提高内容的传播互动量,将负面内容加以遏制,防止进一步造成恶劣影响,对社会具有积极作用。
通过本发明的智能调度方法将舆论媒体装置的各种操作的行为与状态进行合理特征建模,完整覆盖了代理装置所有的行为与状态。
在一些说明性实施例中,在所述S2中,装置的行为采用日志的方式对每一个操作进行在线记录,所述日志的内容包括:代理节点id、代理的操作行为和代理的操作状态。
在一些说明性实施例中,在所述S1中,所述深度强化学习模型为基于DQN的模型,所述深度强化学习模型包括:策略生成网络、代理操作行为、代理状态和代理本次操作的奖励;其中,所述策略生成网络是一个3层前馈神经网络模型。
在一些说明性实施例中,所述S3中,所述网络媒体主题操作行为包括:是否选取当前目标、是否进行转发操作、是否进行点赞操作、是否进行关注操作、是否进行发帖操作和是否进行回复操作。
将代理的状态建模为一个向量va=<a1,a2,…,am>,向量的长度为m,m=6;其中每个元素对应了上述的每个操作的内容,是为1,否为0,发布正面意见为1,发布负面意见为0。
在一些说明性实施例中,所述S4中,代理的状态至少包括以下之一:上一次转发是否成功、转发前的原帖总转发数量、上一次点赞是否成功、点赞前的总点赞数量、上一次回复是否成功、上一次发帖是否成功、上一次关注是否成功、回复前的原帖总回复数量、当前时间、当前代理网络节点、当前剩余可用代理、当前操作代价、当前路径长度。
将代理的状态建模为一个向量vs=<s1,s2,…,sk>,k为向量长度,k=12;其中,每个元素对应了上述的每个状态的内容;将其中每个元素的值的定义为:成功为1,失败为0。
将上述向量va=<a1,a2,…,am>和向量vs=<s1,s2,…,sk>作为深度强化学习模型的输入,进行学习训练。
在一些说明性实施例中,所述S5中,强化学习模型的奖励分数的计算定义为:
R=r1+r2+r3+r4;
其中R为奖励总和,r为奖励参数,具体对应以下4个考核目标:
r1:操作是否成功,成功为1,失败为-1;
r2:路径长度相比上次的差值;
r3:发布的意见结果对总体的舆论导向的影响程度;
r4:代理的时间损耗log值。
读者应理解,在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!