一种基于多任务学习的行人重识别特征描述子的制作方法
本发明涉及视频智能监控领域中的行人重识别问题,尤其是涉及一种基于多任务学习的行人重识别特征描述子,以及一种新的网络模型tdfn(traditionalanddeepfeaturesfusionnetwork)。
背景技术:
行人重识别(re-identification)旨在匹配跨摄像头监控视频中包含相同行人的图像帧,是智能监控分析领域中一项具挑战性的课题。由于其在安全和监控方面的重要应用,例如视频监控分析和基于内容的图像、视频检索,行人重识别在工业界和学术界引起了广泛的关注。重识别模型通常包括表征学习和度量学习两个部分。典型的重识别中,通常使用单个特征描述每幅行人图片,然后在特定任务的度量空间中匹配这些特征,其中相同行人的特征向量具有比不同行人特征向量更小的距离。
现实场景中,由于不同摄像头下存在视角、光照、背景杂乱以及遮挡等显著变化,同一行人在不重叠的摄像机视图中经常出现较大的差异。手工制作不同视觉特征的组合,可以克服重识别任务中的交叉视点变化,有时会更加可靠。在手工制作的特征中,颜色和纹理是其中最有用的两个特征。例如,hsv和lab颜色直方图信息被用来测量图像中的颜色信息,lbp直方图和gabor滤波器被用来描述图像纹理信息。这些手工特征虽然具有一定的独特性,但其效果要差于使用深度学习提取的行人特征。近年来,许多算法通过神经网络直接从原始输入图片中学习相应特征,并且针对行人重识别研究了不同的网络。例如,通过联合学习识别损失、验证损失来研究行人重识别的孪生网络结构,通过学习三类图像(包括锚点,正对和负对图像)之间的相对相似性,研究了三元网络,以及从四个输入图像中学习基于边缘的难例挖掘策略的四重深度网络。这些方法可以有效地学习全局行人表示,但是它们忽略了身体局部位置周围非常丰富的信息,在某些场景下反而会产生次优的效果。lomo特征是手工制作的局部特征,由局部块的颜色、纹理直方图信息构成,含有丰富的细节信息。基于此,lomo特征与由孪生网络学习的深层特征具有互补性。
技术实现要素:
本发明提出了一种基于多任务学习的行人重识别特征描述子,采用成对输入的孪生网络结构,将局部最大出现(localmaximaloccurrence,lomo)特征和深层特征一起送入网络并映射到单一的特征空间中进行训练,形成一种新的网络模型tdfn(traditionalanddeepfeaturesfusionnetwork)。利用神经网络自我学习特性,联合多种任务的损失函数更新网络,使得深层特征学习到更多与手工局部特征互补的细节信息,得到更有辨别力的新特征。
本发明通过以下技术方案来实现上述目的:
(1)提取成对图片的深层特征和局部最大出现(localmaximaloccurrence,lomo)特征,并使用全连接层将lomo特征降低维度。
(2)将深层特征与降低维度后的lomo特征一起送入网络并映射到单一的特征空间中进行训练。
(3)网络使用多任务学习网络,不仅分析两张图片的行人相似度,还预测每幅图片中的行人身份。
(4)联合多个任务的损失函数,利用神经网络的自我学习性,使得深层特征的学习受到lomo特征中细节信息的影响。
附图说明
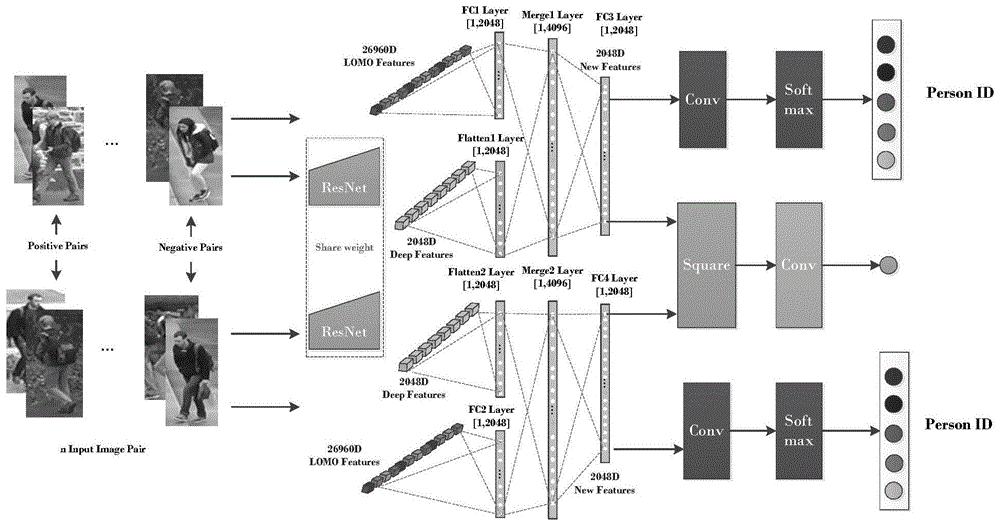
图1一种基于多任务学习的行人重识别特征描述子框架图;
具体实施方式
下面结合附图对本发明作进一步说明:
tdfn模型网络结构具体如下:
模型采用孪生网络结构,包含两个cnn模型(由resnet-50网络移除最后一层fc得到),并且两个cnn模型共享权重。输入两幅图片,两个cnn模型输出两个深层特征。另外,提取两幅图片的lomo特征并送入全连接层降低维度,这样可以缓和两种特征维度之间的巨大差异以便融合。然后将孪生网络提取的深层特征与降维后的lomo特征一起送入merge1层和merge2层进行两种特征的融合,再一起送入fc3层和fc4层中进行学习,得到两个新的特征。网络中有三个任务(两个预测行人身份任务和一个获取两幅图像行人相似度任务),将每个任务产生的损失函数加权在一起更新网络,利用神经网络的自我学习特性,使得图像卷积核的参数得到优化,促进深层特征学习到更多与lomo特征互补的细节信息,从而得到具有辨别力的新特征。
tdfn模型新的融合特征具体如下:
为了获得更好的特征表示,需要大量的图像用于模型训练。然而重识别数据集中没有那么多图像,因此本发明使用在imagenet参数上预训练了的孪生网络提取深层特征。虽然孪生网络生成的特征可以有效地学习全局行人表示,但是它们忽略了身体局部位置周围非常丰富的信息,而lomo特征是手工制作的局部特征,由局部块的颜色、纹理直方图信息构成,含有丰富的细节信息,两种特征具有互补性。因此本发明提取成对图片的lomo特征和深层特征,将两种特征一起送入多任务学习的网络中训练,利用反向传播的原理,通过加权不同任务损失函数更新网络,使得深层特征的提取受到局部手工特征中细节信息的规范,从而得到具有平移不变性的新特征。输入两幅图片pi和pj,分别获取两个图片的深层特征和lomo特征并一起送入merge1层和merge2层中,再通过全连接层fc3层和fc4层形成两个新的特征
x1=[lomo1,deep_feature1](1)
x2=[lomo2,deep_feature2](2)
则fc3层和fc4的输出为:
其中h(·)为激活函数,在fc3和fc4层采用激活函数relu并且使用了丢弃层来学习冗余的表达式,防止过拟合,丢弃率设置为0.5。根据反向传播的原理,迭代后第z层的权重为:
联合多任务损失学习新特征具体如下:
在tdfn网络中,不仅有效地对每幅图像进行特征提取,还通过深度网络对成对图片进行比较,这种基于多任务学习的联合损失可以更好地提取特征。我们利用多任务学习的联合损失对全连接层的两个新特征进行学习,通过反向传播,使得深层特征的提取受到手工特征中局部块的影响,两个特征进行互补学习。本文模型中共有三个任务,其中包括一个获取行人相似度任务和两个预测行人身份任务,其具体过程如下:
获取行人相似度:fc3层和fc4层的两个行人描述子
然后使用一个卷积层将
θs表示卷积层的参数,o表示卷积运算,sigmoid是激活函数。并且
当pi和pj为同一人,则qi=1,否则qj=0。
预测行人身份:每个行人描述子
其中,θi表示卷积层的参数,o表示卷积运算,
其中
最后本文网络的损失函数被定义为:
lossmuti=lossv+lossid(12)
深层特征与lomo特征互补学习具体如下:
训练过程中,假设其中一张图片的深层特征为f,lomo特征为
其中
假设fc3层在第6层q节点的输出为
因此在tdfn网络中
本发明使用两种不同的度量学习方法在market1501和dukemtmc-reid数据库上对所提特征进行了验证,并分别与基准模型和一些主流算法进行了比较。使用单一查询设置进行评估,并使用rank-k精度(k=1、5、10)和平均精度(map)两种评价指标。实验结果如表1,表2和表3所示:
表1与基准模型比较的结果
表2market1501数据集与主流算法结果对比
表3dukemtmc-reid数据集与主流算法结果对比
- 还没有人留言评论。精彩留言会获得点赞!