一种互联网环境下的金融市场风险预警方法与流程
本发明涉及文本数据挖掘以及风险预警领域,具体的说是一种互联网环境下的金融市场风险预警方法。
背景技术:
金融市场在国民经济中扮演重要的角色,是中国市场经济发展过程中的重要一环。对金融市场风险进行预警从宏观层面来说不仅可以保证社会经济健康稳定发展,使得中国经济形成良性循环,而且可以对金融市场的实施较为有效的监管和分析;从微观层面上看,为降低广大投资者投资风险,为投资决策提供参考,获取投资利益,对金融市场进行科学分析,预警建模是很有必要的。
国内外学者对金融市场风险预警的研究从传统的通过股票市场内部历史数据以及相关指标进行预测逐渐向互联网金融领域转变,预警模型中使用了媒体因素作为特征指标,通过新闻数量,新闻情感倾向或对新闻进行分类,在不同的新闻类别下对金融风险进行预测。此外,还有研究将在线评论文本数据作为风险预警的影响因素,包括评论的数量,评论的情感值指数,但是传统方法在情感强度的计算过程中对并没有完全覆盖领域内及网络情感词,程度副词权重的定义主观性较强,缺少客观评测,导致情感强度计算不够准确。此外,目前对金融市场风险预警的研究方法并没有统一的认识,没有将市场内外因素同时加入到模型中,忽略了各因素间相互作用,综上所述,目前的风险预警模型准确度欠佳。
技术实现要素:
本发明是为了解决上述现有技术的不足之处,提出一种互联网环境下的金融市场风险预警方法,以期能构建出更加精准的风险预警模型,从而实现更加准确的风险预测,为金融市场监管提供依据,为投资者投资决策提供参考。
为达到上述目的,本发明采用的技术方案为:
本发明一种互联网环境下的金融市场风险预警方法的特点是按照如下步骤进行:
步骤1、数据预处理:
步骤1.1、定义时间段为t,t={t1,…tt,…tf},1≤t≤f,tt表示第t个时间段,在第t个时间段tt内选取任意一支股票i所对应的股吧评论文本集合,记为
步骤1.2、对第t个时间段tt内股票i所对应的股吧评论文本集合
步骤2、计算情感指数:
步骤2.1、在股票i上涨时刻后的一段时间内对股票i所对应的股吧评论进行抓取后使用tf词频算法,选出词频最高的n个积极情感词语,记为{posn|n=1,2,…,n},并作为积极情感词典的种子词语;
同理,在所选股票i下跌时刻后的一段时间内对股票i所对应的股吧评论进行抓取后使用tf词频算法,选出词频最高的n个消极情感词语,记为{negn|n=1,2,…,n},并作为消极情感词典的种子词语;
由n个积极情感词典的种子词语和n个消极情感词典的种子词语合并为2n个情感词典的种子词语;
步骤2.2、使用word2vec模型将文本语料库中的词语映射到高维连续向量空间中,以实现词向量训练,并得到词向量集合
步骤2.3、计算词向量集合
设置相似值阈值为ε,当max(sim(wt))≥ε时,将第t个词语wt加入max(sim(wt))所对应的情感词典种子词语所属的情感词典中,从而得到扩充后的情感词典集,记为se={sep,sen},sep为积极情感词典,sen为消极情感词典;
步骤2.4、确定程度副词权重:
获取基础程度副词词典,记为adv={adv1,…,advd,…,advu},1≤d≤u,advd为基础程度副词词典adv中第d个程度副词;
从基础程度副词词典adv中选择最轻程度副词advs和最重程度副词advh并分别赋予初始权重
使用word2vec模型训练所述基础程度副词词典adv,得到基础程度副词词典adv中所有程度副词的词向量;计算最轻程度副词advs和最重程度副词advh分别与基础程度副词词典adv中所有程度副词的词向量的余弦相似度,得到相似值向量组
步骤2.5、利用式(1)计算第d个程度副词advd的权重
步骤2.6、计算单词的情感值:
从在第t个时间段tt内股票i所对应的股吧评论文本集合
式(2)中,
步骤2.7、计算文本的情感值:
假设第t个时间段tt内股票i所对应的股吧评论文本集合
利用式(3)得到第t个时间段tt内股票i所对应的股吧评论文本集合
步骤3、计算交叉多重分形谱:
步骤3.1、根据t时间段内股票i的情感强度
步骤3.3、对两个时间序列进行多重交叉分形分析处理,得到t时间段的奇异指数序列
步骤3.4、利用式(4)计算t时间段内股票i的多重分型谱的宽度
步骤4、构建t时间段内股票i的风险特征变量
所述市场内部特征指标包括:t时间段内股票i的价格记为
所述市场外部特征指标包括:t时间段内股票i的媒体关注度为
步骤5、构建预测分析模型:
步骤5.1、构建样本集:
由所述风险特征变量
步骤5.2、利用twin-svm分类方法对所述样本集合
与现有技术相比,本发明的有益效果体现在:
1、本发明在特定场景下结合tf词频算法构建情感词典种子词语,通过该算法选择情感词典种子词语更加具有互联网环境下和金融领域情感词的代表性,克服了现有方法中使用基础情感词典而不能完全适用于网络环境,缺乏领域知识的文本情感分类的缺陷。
2、本发明利用word2vec算法扩展情感词典,使得情感词典涵盖面更广,从而对文本的情感计算更加的精准和确切,克服了由于目前网络发展迅速,而基础情感词典已经不能涵盖全部网络用语,从而对情感计算上精度缺失的问题。
3、本发明结合word2vec算法以及向量归一化算法重新定义了程度副词权重。以往研究使用的程度副词权重往往是人工标注,而本发明定义的权重克服了主观性,更加客观地定义程度副词的权重,从而使得最终情感强度的计算也更加的客观真实。
4、本发明利用多重交叉分形mf-dcca算法计算出投资者情感强度为与媒体关注度的多重分形谱,并创造性地将多重分形谱作为投资者情感强度与媒体关注度的交互作用的量化指标,此方法更能体现出在金融市场上投资者情感强度与媒体关注度的交互作用,将这种交互作用作为模型的风险特征指标之一,从而使得模型预测结果更加准确。
5、本发明从市场内部及市场外部两个方面构建了影响股票市场风险的特征指标,并通过文本挖掘技术计算出的投资者情感强度以及通过和交叉多重分形方法得到投资者情感强度与媒体关注度之间的多重分型谱共同作为市场外部指标,结合机器学习算法构建金融市场风险预警模型,模型指标的计算和选择使得风险预警模型更加稳健,效果更加精准。
附图说明
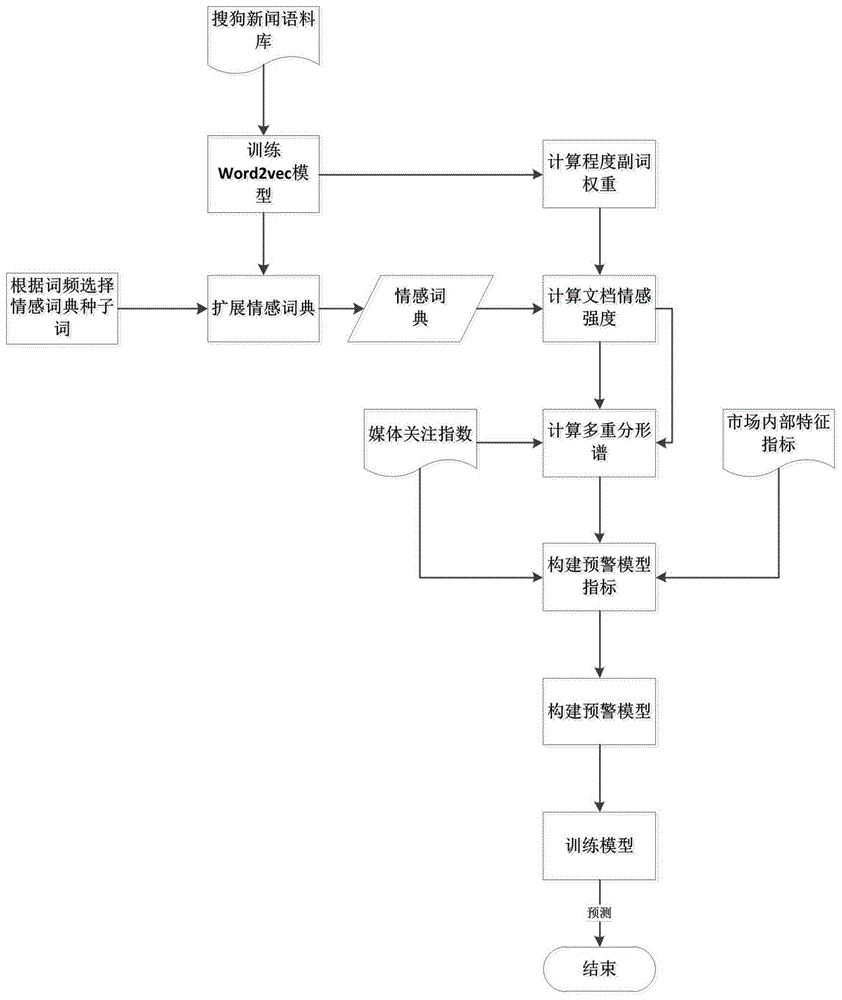
图1为本发明方法的流程示意图。
具体实施方式
本实施例中,如图1所示,一种互联网环境下的金融市场风险预警方法,是通过文本挖掘技术并结合机器学习算法更加准确地计算出投资者情感强度,结合市场内外指标构建出更加稳健和精准的风险预警模型,具体的说,是按照如下步骤进行:
步骤1、数据预处理,本实施例中,选取的文档合集是股吧评论数据:
步骤1.1、定义时间段为t,t={t1,…tt,…tf},1≤t≤f,tt表示第t个时间段,在第t个时间段tt内选取任意一支股票i所对应的股吧评论文本集合,记为
步骤1.2、对第t个时间段tt内股票i所对应的股吧评论文本集合
步骤2、计算情感指数:
步骤2.1、在股票i上涨时刻后的一段时间内对股票i所对应的股吧评论进行抓取后使用tf词频算法,选出词频最高的n个积极情感词语,记为{posn|n=1,2,…,n},并作为积极情感词典的种子词语;
同理,在所选股票i下跌时刻后的一段时间内对股票i所对应的股吧评论进行抓取后使用tf词频算法,选出词频最高的n个消极情感词语,记为{negn|n=1,2,…,n},并作为消极情感词典的种子词语;
由n个积极情感词典的种子词语和n个消极情感词典的种子词语合并为2n个情感词典的种子词语;
步骤2.2、本实施例中word2vec模型向量维数选取为150维,基于搜狗新闻语料库进行训练。使用word2vec模型将文本语料库中的词语映射到高维连续向量空间中,以实现词向量训练,并得到词向量集合
步骤2.3、计算词向量集合
设置相似值阈值为ε,本实施例中阈值ε设定为0.7,当max(sim(wt))≥ε时,将第t个词语wt加入max(sim(wt))所对应的情感词典种子词语所属的情感词典中,从而得到扩充后的情感词典集,记为se={sep,sen},sep为积极情感词典,sen为消极情感词典;
步骤2.4、确定程度副词权重:
获取基础程度副词词典,记为adv={adv1,…,advd,…,advu},1≤d≤u,advd为基础程度副词词典adv中第d个程度副词;
从基础程度副词词典adv中选择最轻程度副词advs和最重程度副词advh并分别赋予初始权重
使用word2vec模型训练基础程度副词词典adv,得到基础程度副词词典adv中所有程度副词的词向量;计算最轻程度副词advs和最重程度副词advh分别与基础程度副词词典adv中所有程度副词的词向量的余弦相似度,得到相似值向量组
步骤2.5、利用式(1)计算第d个程度副词advd的权重
步骤2.6、计算单词的情感值:
从在第t个时间段tt内股票i所对应的股吧评论文本集合
式(2)中,
步骤2.7、计算文本的情感值:
假设第t个时间段tt内股票i所对应的股吧评论文本集合
利用式(3)得到第t个时间段tt内股票i所对应的股吧评论文本集合
步骤3、计算交叉多重分形谱:
步骤3.1、根据t时间段内股票i的情感强度
步骤3.3、对两个时间序列进行多重交叉分形分析处理,得到t时间段的奇异指数序列
步骤3.4、利用式(4)计算t时间段内股票i的多重分型谱的宽度
步骤4、构建t时间段内股票i的风险特征变量
市场内部特征指标包括:t时间段内股票i的价格记为
市场外部特征指标包括:t时间段内股票i的媒体关注度为
步骤5、构建预测分析模型:
步骤5.1、构建样本集:
由风险特征变量
步骤5.2、利用twin-svm分类方法对样本集合
- 还没有人留言评论。精彩留言会获得点赞!