一种基于规则和词典的地铁设计规范中主体识别方法与流程
本发明属于计算机自然语言处理技术领域,涉及一种基于规则和词典的地铁设计规范中主体识别方法。
背景技术:
随着大数据的兴起,面对海量数据信息如何正确合理利用是大数据分析的关键所在。而知识图谱可以将结构化、半结构化数据用图的方式表示出来,从而简化知识,方便数据的进一步处理利用。自谷歌2012年提出了“知识图谱”的概念后,知识图谱首先被应用于搜索领域,而近几年,知识图谱已经开始向行业知识图谱领域发展。
当前,建筑行业的信息化建设还处于起步阶段,传统建筑行业审图多为专家模式、人工操作,规范的检查过程复杂耗时且容易出错。地铁是新兴的建筑行业,由于地铁设计规范多为文本形式表示,其陈述结构也与知识图谱表示相契合,故可利用知识图谱来对地铁设计规范进行知识表示,从而推动轨道交通行业信息化进程,传统基于词典的命名实体识别无法对地铁设计规范中出现的歧义词和未登录词进行识别,现在该方面的专利申请还是空白。
技术实现要素:
本发明的目的是提供一种基于规则和词典的地铁设计规范中主体识别方法,解决了现有技术中基于词典的命名实体识别无法对地铁设计规范中歧义词和未登录词进行识别的问题。
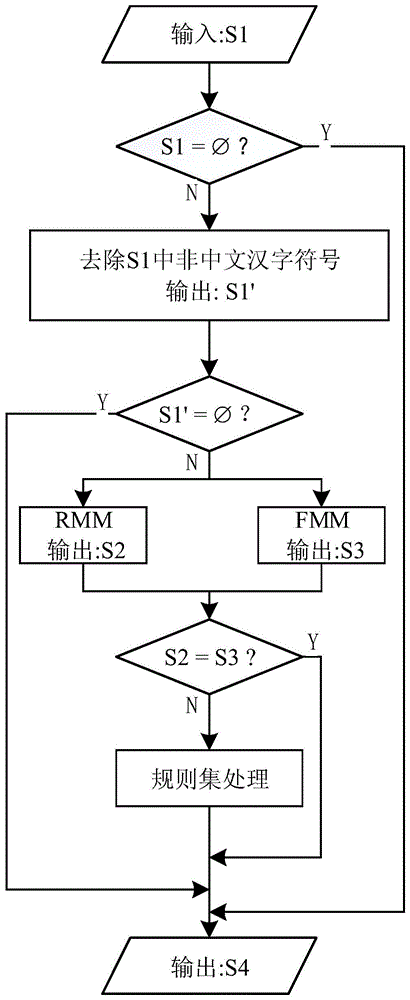
本发明所采用的技术方案是,一种基于规则和词典的地铁设计规范中主体识别方法,按照以下步骤实施:
步骤1,利用词典文件构建名词哈希词典索引;
词典文件是从IFC实体类得到,构建名词哈希词典索引采用hash_map数据结构;
步骤2,将待处理《地铁设计规范》文本作为输入文本S1;
步骤3,对输入文本S1进行处理,去除中英文标点符号,生成句子集合S1’;
步骤4,对步骤3得到的句子集合S1’进行逆向最大匹配算法处理,生成第一结果集S2;
步骤5,对步骤3得到的句子集合S1’进行正向最大匹配算法处理,生成第二结果集S3;
步骤6,对步骤4得到的第一结果集S2、步骤5得到的第二结果集S3分别进行规则集匹配,生成地铁设计规范中名词的最终结果集S4,输出该最终结果集S4。
本发明的有益效果是,先将建筑规范中的名词存入名词哈希词典,再根据名词哈希词典,对地铁设计规范同时进行正向最大匹配和逆向最大匹配算法处理,得到两个结果集,再根据自定义规则集对结果集进行处理,最后输出地铁设计规范中的实体词,整个流程均为全自动实现。本发明方法根据IFC实体类构建词典,以规则加词典的形式对地铁设计规范中实体词进行识别,并自动抽取,在基于名词哈希词典进行匹配的基础上,针对地铁设计规范制定规则集,从而使主体词识别结果更加准确,整个流程均为全自动实现,为后期知识图谱的构建减轻负担。
附图说明
图1为本发明识别方法的总流程图;
图2为本发明识别方法的实施例流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
参照图1,本发明基于规则和词典的地铁设计规范中主体识别方法,先将建筑规范中的名词存入哈希词典,再根据构建的词典,对地铁设计规范同时进行正向最大匹配和逆向最大匹配算法处理,得到两个结果集,再根据自定义规则集对结果集进行处理,最后输出地铁设计规范中的实体词,具体按照以下步骤实施:
步骤1,利用词典文件构建名词哈希词典索引;
词典文件是从IFC实体类得到,构建名词哈希词典索引采用hash_map数据结构。
步骤2,将待处理《地铁设计规范》文本作为输入文本S1;
步骤3,对输入文本S1进行处理,去除中英文标点符号,生成句子集合S1’;
在步骤3中将输入文本S1存入数组S1[]中,设定S1[0]为第一个字符;先根据ASCII码值对输入文本S1中的英文标点符号(比如空格、回车、换行)进行识别,并添加预定义的分隔符“/”,初步对输入文本S1进行划分,并以英文标点符号作为划分结点将输入文本S1划分为多个部分;然后根据汉字GB2312编码利用高低区位码进行再次识别,并进行再次划分,并以中文符号作为划分结点,并添加分隔符“/”,最终生成句子集合S1’。
实施例中,步骤3中的伪代码如下:
去除非中文符号
Input:Stair specifications(S1)
Output:S1’
01.S1’:=“”;
02.While
03.根据ASCII码值对输入文本S1中的空格、回车及换行进行识别并作为划分节点将输入文本S1划分为多个部分;
04.再根据汉字GB2312编码利用高低位对初次划分后的句子中中文标点进行查找判断,以此为第二次界定将句子再次划分;
05.Return S1’。
步骤4,对步骤3得到的句子集合S1’进行逆向最大匹配算法处理,生成第一结果集S2;
在步骤4中,逆向最大匹配算法的具体过程如下:
4.1)在经步骤3处理的句子集合S1’中,将句子集合S1’中的句子按照从前往后的顺序,从第一个划分点处获取一个句子;
4.2)若步骤4.1)中获取的一个句子长度小于预设定的最大词长n,n即名词哈希词典中最长词的长度,则将该句作为匹配字段w,执行步骤4.3);
若大于或者等于最大词长n,则从该句的最右侧开始,取最大词长长度的字符串作为匹配字段w,执行步骤4.3);
4.3)查找步骤1中的词典文件,根据哈希索引匹配步骤4.2)中所得的匹配字段w,判断其是否在名词哈希词典中,若匹配成功,则添加分隔符“/”,输出至第一结果集S2中,并将匹配字段w从句子中剔除;
再将剩余句子重复步骤4.2);若不存在,则执行步骤4.4);
4.4)将匹配字段w的最左侧字剔除,用剩下的n-1个字组成的字段作为新的匹配字段w,反复执行步骤4.2);若剔除至单个字还未匹配成功,则添加分隔符“/”并将该字从句子中剔除,直至句子为空;
4.5)对一个句子处理完成后,该句子即从句子集合S1’中剔除,在剩余的句子集合S1’中,按照从前往后的顺序,从第一个划分点处获取一个新句子;
4.6)重复执行步骤4.2)~步骤4.5),直至句子集合S1’为空,最终输出第一结果集S2。
步骤5,对步骤3得到的句子集合S1’进行正向最大匹配算法处理,生成第二结果集S3;
在步骤5中,正向最大匹配算法的具体过程如下:
5.1)在经步骤3处理得到的句子集合S1’中,将句子集合S1’中句子按照从前往后的顺序,从第一个划分点处获取一个句子;
5.2)若步骤5.1)中获取的一个句子长度小于预设定的最大词长n(名词哈希词典),则将该句作为匹配字段w,执行步骤5.3);若大于或者等于最大词长n,则从该句的最左侧开始,取最大词长长度的字符串作为匹配字段w,执行步骤5.3);
5.3)查找步骤1中的词典文件,根据名词哈希词典索引匹配步骤5.2)中所得匹配字段w,判断其是否在名词哈希词典中,若匹配成功,则添加分隔符“/”,输出至S3中,并将匹配字段w从句子中去除;
再将剩余句子重复步骤5.2);若不存在,则执行步骤5.4);
5.4)将匹配字段w的最右侧字剔除,用剩下的n-1个字组成的字段作为新的匹配字段w,反复执行步骤5.2;若剔除至单个字还未匹配成功,则添加分隔符“/”并将该字从句子中剔除,直至句子为空;
5.5)对一个句子处理完成后,该句子即从句子集合S1’中剔除,在剩余的句子集合S1’文本中,按照从前往后的顺序,从第一个划分点处获取一个新句子;
5.6)重复执行步骤5.2)~步骤5.5),直至句子集合S1’为空,最终输出第二结果集S3。
步骤6,对步骤4得到的第一结果集S2、步骤5得到的第二结果集S3分别进行规则集匹配,生成地铁设计规范中名词的最终结果集S4,输出该最终结果集S4;
在步骤6中对步骤4得到的第一结果集S2、步骤5得到的第二结果集S3进行规则匹配,生成地铁设计规范中名词最终结果集S4的具体过程是:
6.1)读取第一结果集S2、第二结果集S3,将第一结果集S2、第二结果集S3分别存入数组S2[]、S3[]中,设定S2[0]、S3[0]均为第一个字符,再将S2[]、S3[]数组中的分隔符所在位置的下标分别存入数组a[]、b[]中;
6.2)循环遍历数组a[]、b[],判断a[]、b[]中的相同下标下的对应的数组元素是否相同,若所有相同下标下的对应数组元素均相同,则执行步骤6.3);
若a[]、b[]两个数组中相同下标下的对应数组元素出现不同,则执行步骤6.4);
6.3)判断若a[0]大于3且a[1]减去a[0]大于3,则将第一结果集S2中a[0]位置处的分隔符去除,否则不做处理;
再从a[]中第二个元素位置(a[1])开始循环,判断若a[i]-a[i-1]大于3且a[i+1]-a[i]大于3,则将第一结果集S2中a[i]位置处的分隔符去除,否则不做处理,直至a[]中最后一个元素,结束循环,输出最终结果集S4,直接执行步骤6.5);
实施例中,步骤6.3)伪代码如下:
规则1:
Input:逆向最大匹配算法处理结果S2,正向最大匹配算法处理结果S3
Output:S4
S4=””;
for i←0to S2.length
do if S2[i]==47
then a[j]=i;j++
for i←1to S2.length
do if(a[0]>3)&&(a[1]-a[0]>3)
then S2[a[0]]=NULL
if(a[i]-a[i-1]>3)&&(a[i+1-a[i]>3])
then S2[a[i]]=NULL
S4=S2
Return S4;
6.4)循环遍历a[]、b[]中元素,直到找出不一致的元素所对应的下标j,将第一结果集S2中a[j]位置处的分隔符去除,当a[]、b[]两个数组中元素均相同时,返回执行步骤6.3);
实施例中,步骤6.4)伪代码如下:
规则2
Input:逆向最大匹配算法处理结果S3
Output:S2
S2=””;
for i←0to S3.length
do if S3[i]==47
then a[j]=i;j++
for i←0to S3.length
do if S3[i]==47
then b[j]=i;j++
for i←0to S3.length
do if a[i]!=b[i]
then S3[a[i]]=NULL
S2=S3
Return S2;
6.5)重复步骤6.2)~步骤6.4),直至将第一结果集S2、第二结果集S3中对应句子都比较处理完,并输出最终结果集S4,即成。
参照图2,本发明识别方法的实施例是,以“地铁通信设备机房不应与电力变电所相邻。”为例。首先对其进行步骤3数据预处理,其结果为S1=“地铁通信设备机房不应与电力变电所相邻/。/”,然后再同时进行逆向和正向最大匹配,对应本专利中步骤4和步骤5,其结果分别为:S2=“地铁/通信设备机房/不/应/与/电力/变电所/相/邻/。/”,S3=“地铁通信设备/机房/不/应/与/电力/变电所/相/邻/。/”。最后对其进行规则集匹配处理,其结果为S4=“地铁通信设备机房/不/应/与/电力变电所/相/邻/。/”。
本发明的地铁设计规范中主体识别方法,创新点在于规则加词典、自定义规则、全自动、面向地铁设计规范(领域),先根据IFC实体类将地铁设计规范中的名词存入哈希词典,再根据词典,对地铁设计规范同时进行正向最大匹配和逆向最大匹配算法处理,得到两个结果集,再根据自定义规则集对结果集进行处理,最后输出地铁设计规范中的实体词,整个流程均为全自动实现。本发明利用哈希结构对词典进行预处理,从而提升查找标记的效率;在基于词典进行匹配的基础上,针对地铁设计规范制定规则集,从而使主体词识别结果更加准确,整个流程均为全自动实现,为后期知识图谱的构建减轻负担。
- 还没有人留言评论。精彩留言会获得点赞!