一种基于图片验证码的图像处理与字符分割方法与流程
本发明涉及一种用于图片验证码的高效的图像处理和字符分割方法,属于图片验证码技术领域。
背景技术:
图片验证码技术是现代网络安全技术的一部分,用于区分访问对象是人还是机器人,以防止程序中出现大流量的有目的的访问。一般的验证码可以阻止一些简单的机械式的访问,但是在如今机器识别已经成熟的时代,对于简单排列的数字和字母的图片识别已经不是什么难题了。国内外有很多学者对验证码的识别进行研究,尝试机器识别验证码的目的不是破解验证码而是发明更有效的、难以让机器识别的验证码,进而保持发明验证码的初衷。
验证码的识别一般包括图片预处理阶段、字符分割阶段和机器学习与预测阶段,其中,图片预处理阶段包括图片灰度化、图片二值化、图片去噪和图片增强等。字符分割阶段是识别验证码最难最关键的阶段,字符分割的好与坏会直接影响到下一步分类学习识别阶段。机器学习与预测阶段在字符分割的基础上对验证码进行识别,这一阶段常用的分类及预测的方法有knn和svm算法。现阶段的研究表明,字符分割是验证码处理的重难点,目前还没有通用的完美的算法去解决复杂粘连字符的分割问题,甚至有些验证码人眼也需要一定时间去区分,这是阻碍机器识别验证码的主要障碍,也成为如今验证码依然可以成为人机区分手段的基础保障。国外学者指出,当一组样本的验证码能够被机器有效识别(完全识别正确)超过10%则该验证码(系统)已经不再安全。
研究验证码机器识别可以为后续对验证码生成规则的改进提供数据支持,避免使用那些已经可以近乎完美解决的方法,为开发新的干扰要素提供支持,使得图片验证码能够继续提供有效的人机区分服务。
技术实现要素:
本发明提出了一种基于图片验证码的图像处理与字符分割方法,在图像处理阶段,通过模板滤波器和统计法给图像去燥,在字符分割阶段,根据基准线垂直分割法获得初始的分割位置,然后对分割位置进行修正,最终确定分割位置。本发明方法的去燥性能更好,且字符分割精度较高,生成的字符样本有利于后续机器识别学习。
为解决上述技术问题,本发明采用了如下技术手段:
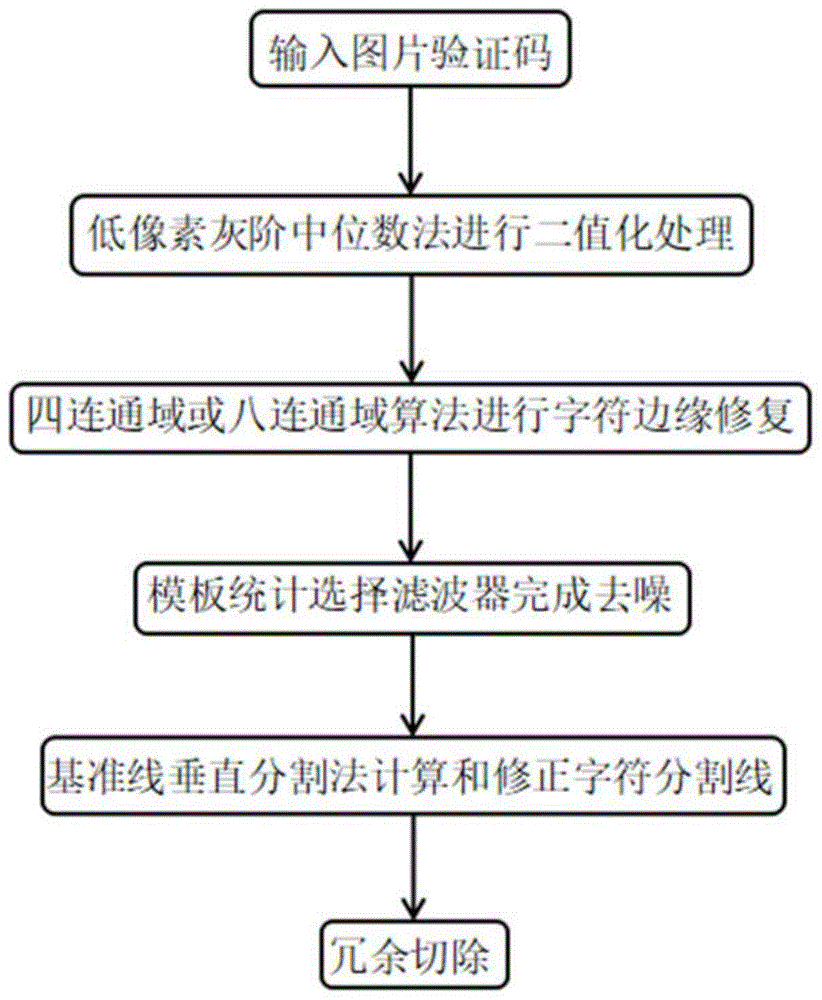
一种基于图片验证码的图像处理与字符分割方法,具体包括以下步骤:
s1、利用低像素灰阶中位数法对图片验证码进行二值化处理;
s2、利用四连通域或八连通域算法对二值化后的图像中的字符边缘进行修复;
s3、利用模板统计选择滤波器给修复后的图像去噪,所述的模板统计选择滤波器的算法是:采用模板算法将图像中特定像素点相邻区域的像素值排序,根据统计法确定选择位置,将选择位置上的像素值赋值给特定像素点;
s4、基于基准线垂直分割法计算和修正字符分割线,将去燥后的图像分割为r个字符样本,r为图像中的字符数量;
s5、计算每个字符样本冗余部分的切割位置并按照位置切割字符,获得切除冗余部分的字符样本。
进一步的,步骤s1的具体操作如下:
s11、分析验证码图像,获得原图像的灰度直方图h(x)。
s12、在定义域的子集i中观测一个界定值m。
s13、将区间i中满足h(x)<m的x记为xi,得到集合x=x1,x2......xn,i=1,2,...,n。
s14、计算集合x的中位数median1≤i≤n{xi},令二值化阈值t=median1≤i≤n{xi}。
s15、利用二值化阈值对原图像进行二值化处理:
其中,(x,y)为图像像素坐标,g(x,y)为原图像中像素点的灰度值,g(x,y)为二值化图像中像素点的灰度值。
进一步的,步骤s2的具体操作如下:
s21、采用复数z=x+yi表示像素点,i为虚数单位,g(z)表示像素点的灰度值,设g(z)=1时,像素点为白点,g(z)=0时,像素点为黑点。
s22、依次检索二值化后图像中的像素点,当一个像素点为白点时,获取该像素点四连通域或八连通域的像素点。
s23、当该像素点四连通域内有3个即以上黑点,或者该像素点八连通域内有5个即以上的黑点时,将该白像素点修正为黑点,否则保留该白点,并将该像素点标记为已操作。
s24、检索下一个未操作的像素点,重复步骤s22和s23,直到检索完图像中的所有像素点。
进一步的,步骤s3的具体操作如下:
s31、构建一个模板a,a为a×b的区域,a、b为奇数。
s32、设计模板窗口取数函数w(a,z),以图像中任一像素点位置z为卷积核中心,提取模板a区域内所有像素点的像素值生成有穷数列c。
s33、设计排序和标序函数si(c),依次对比数列c中各项值的大小,将所有项按照从小到大的顺序排列并标序,生成有序数列d。
s34、设计选择函数sel(d,s),将有序数列d中序号位置为s的数值提取出来,s是通过统计法确定的。
s35、设计模板统计选择滤波器y,在滤波器内输入任一像素点位置z,滤波器y的输出为像素点z修正后的像素值:
y(z,a,s)=sel{si[w(a,z)],s}(2)
g修正后(z)=y(z,a,s)(3)
s36、重复步骤s35,依次修正图像中所有像素点,给步骤s2修复后的图像去噪。
进一步的,步骤s4的具体操作如下:
s41、沿着图像宽度依次扫描图像每一列中黑色像素的个数,通过统计和人工筛选,获得字符分割基准线集合k={keyk|k=1,2,...,l},keyk表示第k条基准线,l为基准线个数,l-1为图像中的字符个数。
s42、计算各个字符分割的起始位置,建立不等式:
其中,p(e)表示第e列黑色像素的数量,p(e+1)表示第e+1列黑色像素的数量,th为距离阈值,height表示图像厚度,即第e列的像素总数,g(e,f)第e列第f行像素点的像素值。
当不等式的解集
s43、计算各个字符分割的结尾位置,建立不等式:
当不等式的解集
s44、进行第一次修正,建立下列不等式:
其中,key为s42中不等式解集为空的keyk或者s43中不等式解集为空的keyk+1。
当不等式的解集
s45、进行第二次修正,依次将s42、s43、s44选出的分割位置代入下列不等式:
其中,keye为分割位置e对应的分割基准线,dth为意外判断距离阈值,dth的取值是人工设置的且dth≤th。
当分割位置e满足上述不等式,将该分割位置e从所有分割位置中移除。
s46、将s44中使不等式解集为空的key代入下列不等式:
其中,w为粘连判定阈值。
当上述不等式的解集
ve=a·p(e)+b·de(10)
其中,a、b为人为设定的参考权重,de=|e-key|,e∈ek。
当上述不等式的解集
s47、根据s42-s46选出的分割位置对去燥后的图像进行字符分割,获得分割后的字符样本。
进一步的,步骤s5的具体操作如下:
s51、选取一张字符样本,依次扫描字符样本每一行的黑色像素个数:
其中,qr(f)表示第r个字符样本第f行的黑色像素个数,r=1,...,r,width表示字符样本宽度,即第f行的像素总数,gr(e,f)表示第r个字符样本第f行第e列像素点的像素值。
s52、根据qr(f)大小绘制yb曲线,yb曲线的公式如下:
根据yb曲线获得切除冗余部分的顶部经验准轴hcs和底部经验准轴hce。
s53、确定字符样本顶部切割位置,建立不等式:
其中,rth为容差阈值;当不等式的解集
s54、确定字符样本底部切割位置,建立不等式:
当不等式的解集
s55、根据s53和s54确定的顶部切割位置和底部切割位置对字符样本进行冗余切除。
采用以上技术手段后可以获得以下优势:
本发明提出了一种基于图片验证码的图像处理与字符分割方法,在图像处理过程中,采用低像素灰阶中位数法进行二值化处理,与其他二值化处理方法相比,本方法不仅处理效果较好而且计算量较小,本方法大量减少了迭代次数,使算法复杂度降低到o(n)阶;将常规模板滤波器与统计法结合,建立模板统计滤波器,以统计学方法进行预处理,能够在不增加实现复杂度的情况下提升处理精度,有效去除干扰区域的黑色像素。在字符分割阶段,针对垂直字符分割法获取的分隔位置进行多次修正,提高了字符分割的正确率,同时对分割后的字符样本进行冗余切除,可以提高单个字符样本中有效信息的占比。本发明方法计算较为简单,图像处理和字符分割的精度更高、适用性更好,经过本方法处理的字符样本更加方便后续机器识别,提高机器识别的正确率。
附图说明
图1为本发明一种基于图片验证码的图像处理与字符分割方法的步骤流程图。
图2为本发明实施例中验证码的灰度直方图。
图3为本发明实施例中采用ostu法和mlpg法分别进行二值化处理,其中,(a)为ostu法和mlpg法计算出的阈值,(b)为ostu法和mlpg法计算出的阈值在所有图片中的占比。
图4为本发明方法二值化处理后的图像与字符边缘修复后的图像的对比图。
图5为本发明方法的模板统计选择滤波器不同选择位置的去燥效果图。
图6为本发明方法中字符分割的步骤流程图。
图7为本发明字符切割中实验样本图片各列位置与黑色像素数量的关系图。
图8为本发明方法未进行分割修正时不同th值的分割正确率统计图。
图9为本发明实施例中th=10、w=4、a=1、b=0的情况下不同的dth值的分割正确率统计图。
图10为本发明方法冗余切除中实验样本图片高度与黑色像素数量的关系图。
图11为本发明方法中同一字符样本未进行冗余切除和己进行冗余切除的尺寸对比图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明:
一种基于图片验证码的图像处理与字符分割方法,如图1所示,具体包括以下步骤:
s1、以图片验证码的左下角像素点作为坐标原点,图像宽度方向为x轴,高度方向为y轴,建立直角坐标系,定义像素点o的坐标为(xo,yo),此外,如果将图像看做复平面,定义像素点o的坐标复数表达式为zo=xo+yoi,i为虚数单位。
利用低像素灰阶中位数法对图片验证码进行二值化处理,具体操作如下:
s11、以图2中的验证码图像为例,分析验证码图像,获得原图像的灰度直方图h(x)。
s12、根据灰度直方图获取定义域的子集i=[21,179],在子集中i中观测一个界定值m,m的取值可以根据实验精度的要求调整。
s13、依次比较h(x)和m的大小,将区间i中满足h(x)<m的x记为xi,得到集合x=x1,x2......xn,i=1,2,...,n。
s14、计算集合x的中位数median1≤i≤n{xi},令二值化阈值t=median1≤i≤n{xi}。
s15、设(x,y)为图像像素坐标,g(x,y)为原图像中像素点的灰度值,利用二值化阈值对原图像进行二值化处理:
其中,g(x,y)为二值化图像中像素点的灰度值。
本具体实施例对500张图片验证码同时采用低像素灰阶中位数(mlpg)法和ostu法进行二值化处理,图3中的(a)是500张图片分别采用两种方法计算出的阈值,图3中的(b)是通过两种方法计算出的阈值在所有图片中的占比,可以看出,ostu法计算的二值化阈值较高,且各个样本的阈值比较接近,mlpg法计算出的二值化阈值较低,最大值与最小值相差在20左右。mlpg法的计算量相对来说较小,不需要进行重复的迭代,只需要扫描一遍图片像素点即可。
同时,我们可以看出,不同的样本的二值化阈值较为接近,样本总体接近正态分布,如果对所有样本采用同一个二值化阈值,可以进一步简化算法,使用一个全局的二值化阈值可以使得不同样本间的字符粗细均衡,对于机器学习需要的归一化条件是很有利的。在本具体实施例中,二值化阈值尝试选取t=80,t=100,t=120,经过后期的去噪分析、字符分割分析,最终选取全局二值化阈值t=80。该阈值较好地保留了字符的骨干部分,没有过度强调干扰线,且不易造成字符粘连,是本发明方法优选的二值化阈值。
s2、利用四连通域或八连通域算法对二值化后的图像中的字符边缘进行修复;具体操作如下:
s21、采用复数z=x+yi表示像素点,g(z)表示像素点的灰度值,设g(z)=1时,像素点为白点,g(z)=0时,像素点为黑点。
s22、依次检索二值化后图像中的像素点,当一个像素点为白点时,获取该像素点四连通域或八连通域的像素点;四连通域是获取该像素点位置的上下左右四个位置的像素,依次用z+i0、z+i1、z+i2、z+i3表示这四个位置的像素。八连通区域是获取该像素点的上、下、左、右、左上、左下、右上、右下八个位置的像素,为了方便处理定义旋转用模长为1的复数:
同时为了保证旋转45°时依旧是格点复数,即像素点坐标x、y是整数,需要在旋转45°时做模长伸缩变换。八连通域的八个像素位置可以用如下方式选取:
其中,c=0,1,2,3,4,5,6,7。设
zc=z+τc(19)
s23、采用四连通域算法时,计算该像素点四连通域内像素点的灰度值之和:
当该像素点四连通域内有3个即以上的黑点时,将该白像素点修正为黑点,否则保留该白点:
采用八连通域算法时,计算该像素点八连通域内像素点的灰度值之和:
当该像素点八连通域内有5个即以上的黑点时,将该白像素点修正为黑点,否则保留该白点:
为了方便区分,将修正后的像素点标记为已操作。
s24、自动检索下一个未操作的像素点,重复步骤s22和s23,直到检索并处理完图像中的所有像素点。
图4给出了一组二值化后的图像和字符边缘散点修复后的图像,可以看出修复后的图像的字符边缘明显变得平滑,且白点、黑点零散分布的现象减少,此外,本发明的字符边缘修复算法不会明显加粗干扰线,有利于后续操作。
s3、本发明设计一种新的模板统计滤波器,采用模板算法将图像中特定像素点相邻区域的像素值排序,根据统计法确定滤波器中滤波的选择位置,将选择位置上的像素值赋值给特定像素点,进而完成利用模板统计选择滤波器给修复后的图像去噪的目的。具体操作如下:
s31、构建一个模板窗口a,a为a×b的区域,a、b为奇数;考虑到需要去噪的特征为穿越主字符区域的、厚度一般不大于3个像素的、主要为横线发展的干扰线,在本具体实施例中,选取厚度为5、宽度为3的[5×3]模板窗口,假设该窗口可以完全覆盖三个宽度的干扰线,窗口中共读入9个干扰线点和6个其他点,相比其他的奇数×奇数的矩形窗口,[5×3]模板窗口中干扰点的占比较为适中。
s32、设计模板窗口取数函数w(a,z),以图像中任一像素点位置z为卷积核中心,提取模板a区域内所有像素点的像素值生成有穷数列c。
s33、设计排序和标序函数si(c),依次对比数列c中各项值的大小,将所有项按照从小到大的顺序排列并标序,生成有序数列d。
s34、设计选择函数sel(d,s),将有序数列d中序号位置为s的数值提取出来,s是通过统计法确定的,一般选取可以较好去除干扰区域黑色像素且不会过多去除字符区域黑色像素的位置。本具体实施例给出了[5×3]模板窗口下采用不用的选择位置的黑色像素去除率,如下表所示:
根据上表的信息,本实施例进一步选取s=8、9、10、11对几个图片验证码进行去燥测试,测试结果如图5所示,当s=9时,既可以较好的去除字符与字符之间、字符与相邻干扰线散点的一些连通部分,使字符间距更加明显,也可以较好的保留字符骨干,所以,使用[5×3]模板窗口时,本发明方法优选的选择位置是9。
s35、设计模板统计选择滤波器y,在滤波器内输入任一像素点位置z,滤波器y的输出为像素点z修正后的像素值:
y(z,a,9)=sel{si[w(a,z)],9}(24)
g修正后(z)=y(z,a,9)(25)
s36、重复步骤s35,依次修正图像中所有像素点,给步骤s2修复后的图像去噪。
s4、基于基准线垂直分割法计算和修正字符分割线,将去燥后的图像分割为r个字符样本,r为图像中的字符数量。如图6所示,具体操作如下:
s41、输入图像和分割区块数(即图像中的字符数),沿着图像宽度依次扫描图像每一列中黑色像素的个数:
其中,p(e)表示第e列黑色像素的数量,height表示图像厚度,即第e列的像素总数,g(e,f)第e列第f行像素点的像素值,p(e)=0表示该列无黑色像素。如图7所示,对500个图片验证码样本进行上述操作,得到样本集中图片每列位置与黑色像素数量的关系图,可以观察出字符存在的置信区间i=[45,165],同时,图7中曲线的各个峰值即为可能的分割基准线位置,通过统计图可以得到初始的基准线集合:
k∈{45,47,52,82,106,119,131,146,165}
因为本具体实施例采用的是4个字符的图片验证码,所以需要5条分割线,经过人工筛选,获得字符分割基准线集合:
k={keyk|k=1,2,...,5}={52,82,106,131,165}
其中,keyk表示第k条基准线。
s42、计算各个字符分割的起始位置,建立不等式:
其中,p(e+1)表示第e+1列黑色像素的数量,th为距离阈值。
当不等式(27)的解集
s43、计算各个字符分割的结尾位置,建立不等式:
当不等式(28)的解集
为了确定最佳的th的取值,本具体实施例先在没有进行修正的情况下,即步骤s42、s43中解集
s44、在实际的操作中,如果针对解集
其中,key为s42中不等式解集为空的keyk或者s43中不等式解集为空的keyk+1。
当不等式(29)的解集
s45、为了对一些意外和轻微粘连字符做出修正处理,进行第二次修正,首先依次将s42、s43、s44选出的分割位置代入下列不等式:
其中,keye为分割位置e对应的分割基准线,dth为意外判断距离阈值,dth的取值是人工设置的且dth≤th。
当分割位置e满足上述不等式,将该分割位置e从所有分割位置中移除。
s46、继续第二次修正,将s44中使不等式解集为空的key代入下列不等式:
其中,w为粘连判定阈值,在本具体实施例中,字符轻微粘连多数是由于去燥不够充分,在两个字符间间距过小时错误的把干扰线作为字符的一部分而产生的粘连,所以粘连判定阈值设置为4。
当不等式(31)的解集
ve=a·p(e)+b·de(32)
其中,a、b为人为设定的参考权重,本具体实施例中,a=1,b=0,de=|e-key|,e∈ek。
当不等式(31)的解集
s47、根据s42-s46选出的分割位置对去燥后的图像进行字符分割,获得分割后的字符样本。
本具体实施例对dth的最佳取值也做了研究,在th=10、w=4、a=1、b=0的情况下,分析不同的dth值对字符分割正确率的影响,如图9所示,dth的设定主要是为了防止两个字符之间的间隙正好只有1个像素宽的“巧合”,从图中可以看出,dth值设置为1~3来预防上文提到的“巧合”即可。
s5、经过字符分割得到的单个字符样本,在字符区域的上下都会有部分空白区域,因为输入到机器训练的样本是需要归一化的,如果直接将得到的单字符样本进行大小归一化,空白部分所占比例未免过大,即有效信息所占比例太低,容易造成机器识别的误差过大,因此本发明方法会进一步计算每个字符样本冗余部分的切割位置并按照位置切割字符,获得切除冗余部分的字符样本。具体操作如下:
s51、选取一张字符样本,依次扫描字符样本每一行的黑色像素个数:
其中,qr(f)表示第r个字符样本第f行的黑色像素个数,r=1,...,r,width表示字符样本宽度,即第f行的像素总数,gr(e,f)表示第r个字符样本第f行第e列像素点的像素值。
s52、根据qr(f)大小绘制yb曲线,yb曲线的公式如下:
利用500个图片验证码获得2000个字符样本,经处理得到的yb曲线如图如图10所示,根据yb曲线获得切除冗余部分的顶部经验准轴hcs和底部经验准轴hce,使得98%的样本字符在hcs和hce之间。
s53、确定字符样本顶部切割位置,建立不等式:
其中,rth为容差阈值;当不等式(36)的解集
s54、确定字符样本底部切割位置,建立不等式:
当不等式(37)的解集
s55、根据s53和s54确定的顶部切割位置和底部切割位置对字符样本进行冗余切除,图11为几个字符样本冗余切除前后的尺寸对比,冗余切除提高了字符有效信息(黑色像素)占总像素的比值,使得机器训练阶段进行图像归一化时不同样本的字符占据图像的比例更加均衡一些,一定程度上避免了在机器字符识别时由于字符占比大小的差别过大而导致的字符识别正确率偏低。
上面结合附图对本发明的实施方式作了详细地说明,但是本发明并不局限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!