一种基于属性加密的支持多关键字的模糊搜索方法与流程
本发明属于智能电网系统中通信传输及安全防护技术领域,具体涉及一种基于属性加密的支持多关键字的模糊搜索方法。
背景技术:
随着社会人口的增加和工业的发展,居民和住宅对用电的需求越来越大。智能电网具有双向传输,可靠性高,响应及时和安全性高的特点。在典型的智能电网设施中,高性能的智能电表是其重要的组成部分。智能电表同时和我们的生活息息相关,在日常生活中可以远程的读取电力计量信息,实现对智能电力设备的操控。用户可以合理的安排电器使用,电力主管部门也可以通过智能电表来收集用户的用电信息,用于对电网系统进行改善升级,提高其可靠性。同时,也可以在用电高峰时智能的调节用电分配,防止线路拥堵和过载,维系智能电网的稳定性。把电力计量数据上传至分布式的云服务器上,可以有效的提高对数据的访问效率,但是却给用户的用电数据隐私带来了问题。为了有效保护用户用电数据的安全性,电力计量数据在上传之前需要先进行加密,但是如何在不可信的云服务器上高效的查询用户的用电数据却成为当前面临的挑战之一。
传统的基于属性的可搜索加密技术允许用户安全地搜索加密数据,可搜索加密技术(se,searchableencryption)支持用户对加密后的密文进行关键字查找,同传统方法相比,可以大幅的降低用户的时间开销。可搜索加密技术可以分为对称可搜索加密技术(see,symmetricsearchableencryption)和非对称可搜索加密技术(ase,asymmetricsearchableencryption),二者在性能和功能方面的侧重点不同,分别适合不同的业务需求场景。可搜索加密技术的基本框架是:数据所有者(发送方)对要上传的数据进行加密,并创建安全索引,然后将加密后的数据及索引上传到云端服务器存储。当数据查询者(接收方)需要查询云端服务器的加密数据时,利用密钥生成陷门发送给云端服务器,云服务器利用陷门为数据查询者匹配相应的加密数据,实现搜索;但是传统的云端服务器没有检索功能,只能把所有的存储的加密信息全部返还给用户,在本地进行解密以后再二次查找,这样显然效率是非常低的;此外,在用电高峰时不能合理的调节用电分配,线路容易拥堵和过载,智能电网的稳定性差;其次,传统的电网不能够对用户数据实现细粒度的访问控制,现有的方法不能够实现在属性的搜索方案之同时支持模糊搜索和多关键字搜索,而且智能电网的终端计算能力匮乏,传统的发明不能够有效的运用在智能电网系统中;如何多维度的查询大量数据精确的计算电力功耗,或是对电力能源使用进行改善是目前面临的挑战。云存储访问控制是近年来新兴的研究领域,云服务器可以提供灵活的计算、存储和需要的网络资源。随着云计算的不断发展,越来越多的用户选择将本地的用电信息上传至云服务器存储,这样可以减少计算开销并且降低成本。然而云计算在提供便利服务的同时也面临着安全问题,各式各样的攻击会威胁到用户和企业的数据信息安全。数据用户先对电力计量数据进行加密,然后再上传到云服务器上,从而保证信息的安全性。当查询用户需要查询信息时,由于传统的云端服务器没有检索功能,只能把所有的存储的加密信息全部返还给用户,在本地进行解密以后再二次查找,这样显然效率是非常低的。
2014年sun和lou提出了基于属性的密文搜索方案,方案基于密文属性关键字搜索,搜索的范围相对于密文内容搜索存在较大的局限性,无法满足密文信息的搜索需求,且泄露了包含搜索关键词的文件数量;同年,han等人通过对kp-abe方案进行转换,提出可搜索加密方案的一种构造方案,但不适用于智能电网搜索场景;随后,zheng等人提出了一个可验证的基于属性的关键字查询方案,其通过使用属性签名和关键字标识验证的bloomfilter,可验证云端是否诚实的执行了检索操作。方案中一个关键字对应一个访问策略,搜索用户对不同的关键字查询就必须申请不同的私钥,而且提前定义好的关键字列表也会泄露搜索结果中包含关键字标志文件的数量,且一旦执行更新操作将会需要重新签名文档,非常耗时。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提供了一种基于属性加密的支持多关键字的模糊搜索方法,本发明要解决的技术问题通过以下技术方案实现:
本发明实施例提供了一种基于属性加密的支持多关键字的模糊搜索方法,包括以下步骤:
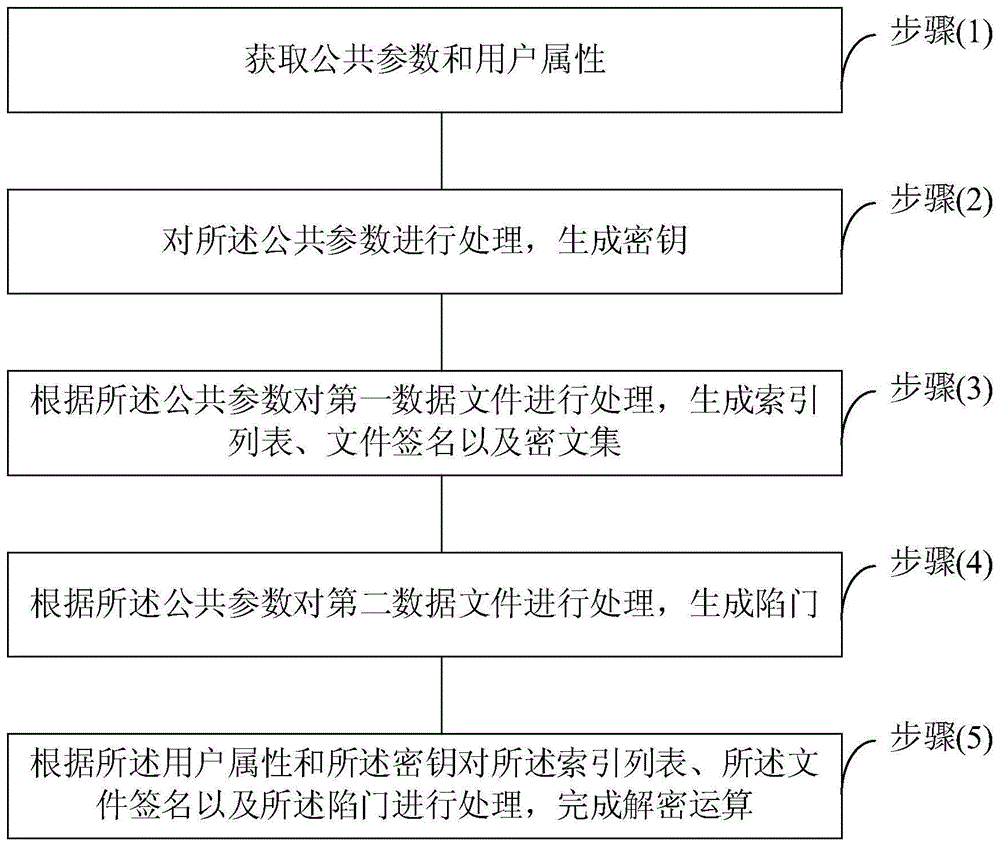
获取公共参数和用户属性;
对所述公共参数进行处理,生成密钥;
根据利用所述公共参数对第一数据文件进行处理,生成索引列表和、文件签名以及密文集;
利用根据所述公共参数对第二数据文件进行处理,生成陷门;
根据所述用户属性和所述密钥对所述索引列表、所述文件签名以及所述陷门进行处理,完成解密运算。
在本发明的一个实施例中,所述密钥包括:第一公钥、第二公钥、第三私钥、第四私钥以及第五私钥。
在本发明的一个实施例中,根据所述公共参数对第一数据文件进行处理,生成索引列表、文件签名以及密文集,包括:
根据所述公共参数计算得到对称密钥;
利用所述对称密匙对所述第一数据文件进行处理,得到所述文件签名和所述密文集;
根据签名后的所述第一数据文件得到第一关键字集,所述第一关键字集中包含若干第一关键字;
根据所述第一关键字集得到所述索引列表。
在本发明的一个实施例中,利用所述对称密匙对所述第一数据文件进行处理,得到所述文件签名和所述密文集,包括:
利用所述对称密钥对所述第一数据文件进行签名,得到文件签名;
利用所述对称密钥对签名后的所述第一数据文件进行加密,得到所述密文集。
在本发明的一个实施例中,根据所述第一关键字集得到所述索引列表,包括:
利用cp-abe算法对所述第一关键字进行加密,生成所述索引列表。
在本发明的一个实施例中,根据所述公共参数对第二数据文件进行处理,生成陷门,包括:
根据所述第二数据文件得到第二关键字集,所述第二关键字集中包含若干第二关键字;
根据所述第二关键字集生成所述陷门。
在本发明的一个实施例中,根据所述第二关键字集生成所述陷门,包括:
利用局部敏感哈希函数将所述字符集映射成对应的常数;
根据所述常数计算得到所述陷门。
在本发明的一个实施例中,根据所述密钥对所述索引列表、所述文件签名以及所述陷门进行处理,包括:
利用所述第一私钥和所述第二公钥对所述索引列表、所述文件签名进行处理;利用所述第三私钥对所述陷门进行处理。
与现有技术相比,本发明的有益效果:
1、与之前的方案不同的是,本申请在基于属性的搜索方案之上,提出了一个同时支持模糊搜索和多关键字搜索的属性基搜索方案,采用局部敏感哈希函数lsh(localitysensitivehashing)的相似性映射原理来实现了属性基可搜索加密中的模糊搜索,支持一些微小的拼写错误词和形近词的搜索;
2、本申请通过搜索词的散列值定位到索引关键词中相对应的位置,实现了多关键字的匹配,本申请可以一次匹配多个搜索词,当所有词均匹配时才返回相关结果,从而提高了搜索结果的准确性。进一步地,由于每个关键字在某个文件中的重要性是不一样的,通过相关分数对匹配文件进行排序,进一步提升搜索结果的准确性。
附图说明
图1为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的流程示意图;
图2为本发明实施例提供的另一种基于属性加密的支持多关键字的模糊搜索方法的流程示意图;
图3为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索系统的结构示意图;
图4为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的系统初始化时间的对比示意图;
图5为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的密钥生成时间的对比示意图;
图6为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的加密时间的对比示意图;
图7为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的陷门生成时间的对比示意图;
图8为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的搜索时间的对比示意图;
图9为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的解密时间的对比示意图。
具体实施方式
下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。
实施例一
请同时参见图1和图2,图1为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的流程示意图;图2为本发明实施例提供的另一种基于属性加密的支持多关键字的模糊搜索方法的流程示意图。
一种基于属性加密的支持多关键字的模糊搜索方法,具体包括以下步骤:
步骤1:获取公共参数和用户属性。
对可信任授权中心进行初始化,并在可信任授权中心中输入安全参数d,根据安全参数d生成系统公钥pb和主密钥mtk,可信任授权中心保存主密钥mtk,并把公钥pb公布。
进一步地,初始化的过程包括:
步骤10:选定双线性群e:
进一步地,设g和gt都是阶为素数p的乘法循环群,,假设离散对数问题在这两个循环群中为困难问题,定义映射e:g×g→gt,如果e满足下面这些性质,则e为一个双线性对:
双线性对具有以下特点:
(1)双线性,e(ga,hb)=e(g,h)ab,其中g,h为g中的任意元素,a,b为
(2)非退化性,存在g中的一个元素g,满足e(g,g)≠1,1表示gt的单位元。
(3)可计算性,对于g中的一切元素p,q,都存在着一个有效的算法来计算e(p,q)。
如果存在上述双线性映射e:g×g→gt以及群gt,则称g为双线性群。又因为映射满足e(ga,gb)=e(g,g)ab=e(gb,ga),所以映射e具有对称性。
步骤11:假设hash函数h1:{0,1}*→g1是个随机预言模型,h2:
步骤12:选取摘要函数
步骤13:选取一个对称加密方案se=(se.enc,se.dec)。
步骤14:任意选取
进一步地,对于每个属性atbj∈atbs,设定撤销属性atbj的用户属性撤销列表为rlj,被授予属性atbj的用户集合表示为属性授权列表glj。为每个属性atbj∈atbs随机选择一个
需要说明的是,用户属性指的是用户的一些身份信息以及其他特征,每个用户的用户属性都是不同的。
步骤2:对所述公共参数进行处理,生成密钥。
进一步地,密钥包括:第一公钥、第二公钥、第三私钥、第四私钥以及第五私钥。
进一步地,步骤2可以包括以下步骤:
步骤21:可信任授权中心选取
步骤22:可信授权中心选取
步骤23:对于每个属性atbj∈atbs,可信授权中心为授权用户选取r,
步骤3:根据公共参数对第一数据文件进行处理,生成索引列表、文件签名以及密文集。
进一步地,步骤3可以包括以下步骤:
步骤31:根据所述公共参数计算得到对称密钥。
数据拥有者选取随机信息
步骤32:利用所述对称密匙对所述第一数据文件进行处理,得到所述文件签名和密文集。
需要说明的是,第一数据文件指的是通过数据拥有者得到的数据文件。
进一步地,步骤32可以包括以下步骤:
步骤321:利用所述对称密钥对所述第一数据文件进行签名,得到文件签名。
数据拥有者将智能电表文件,也就是第一数据文件f=(f1,f2,...,fn)的唯一标识符设置为fid=(fid1,fid2,...,fidn),对每个第一数据文件fi通过拥有者私钥签名得
需要说明的是,对第一数据文件进行签名是为了防止数据文件被篡改。
步骤322:利用所述对称密钥对签名后的所述第一数据文件进行加密,得到所述密文集。
利用对称密钥kse对所述第一数据文件进行加密,经kse加密得到密文集c=(c1,c2,...,cn),tag2=h4(tag1||c)。
步骤33:根据签名后的所述第一数据文件得到第一关键字集,所述第一关键字集中包含若干第一关键字。
数据拥有者从签名后的第一数据文件中提取第一关键字集kw={kw1,kw2,...,kwm},对于每个文件fi,记录对应的索引表tbi,将关键字kwj映射到布隆过滤器相应的位置上,并设置该位置的值为kwj在文件fi中出现的词频tf值,于是tb=(tb1,...,tbn)。
需要说明的是,词频指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数的归一化,以防止它偏向长的文件,(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否)对于在某一特定文件里的词语ti来说,它的重要性可表示为:
以上式子中ni,j是该词在文件di,j中的出现次数,而分母则是在文件di,j中所有字词的出现次数之和。
因此,词频是为了反映第一关键字集中每个关键字的重要程度,在本实施例中起到一个辅助的作用。
在一个具体实施例中,还通过局部敏感哈希函数对第一数据文件进行了处理。首先将每个第一关键字kwi∈kw转换成它对应的uni-gram(一元文法向量)字符集lsi,再通过局部敏感哈希函数将它对应的uni-gram向量vi映射成常数lsh;假设空向量长度为26*5=160比特,表示连续5行的26个英文字母,输出的uni-gram向量为vi=(x1,x2,...,x160)。
向局部敏感哈希函数中输入明文字符集ls,对于每个lsi生成一个对应的向量vi。假设长度为leni,将lsi拆分为lsi[j](0<j<leni),统计每个字符出现的次数,记录在数组u中,其中u[j]对应字符lsi[j]出现的次数。将向量{0,1}160所有位置初始化为0,把lsi[j]和u[j]映射到新向量vi中。当字符lsi[j]第一次出现时,向量中字符lsi[j]第一行的相应的位置置1;当字符lsi[j]第二次出现时,向量中字符lsi[j]第二行的相应的位置置1;如此直至字符lsi[j]第u[j]次出现。输出的向量即是关键字kwi相应的向量vi;计算向量vi的局部敏感哈希函数值为
利用该局部敏感哈希函数,可以得到第一数据文件中的每个文件的相似文件,从而实现了模糊搜索以及形近词的搜索,从而使用户在查询数据时能够节省时间,快速找到需要查询的文件。
步骤34:根据所述第一关键字集得到所述索引列表。
获取索引列表是为了方便数据查询者在查询数据时节省时间,不用对所有的第一数据文件遍历。
进一步地,步骤34可以包括以下步骤:
利用cp-abe算法对所述第一关键字进行加密,生成所述索引列表。
进一步地,对于访问树γ,cp-abe算法首先从根节点r开始,自上而下地为每个节点x选取对应的多项式qx。对于每个节点x,设置其对应的阶dx与节点阈值kx之间存在关系dx=kx-1。任意选取
进一步地,对每个第一关键字kwi∈kw,计算
步骤4:根据公共参数对第二数据文件进行处理,生成陷门。
需要说明的是,第二数据文件为通过数据查询者得到的数据。
进一步地,步骤4还可以包括以下步骤:
步骤41:根据所述第二数据文件得到第二关键字集,所述第二关键字集中包含若干第二关键字。
数据查询者随机选取
数据查询者选取查询第二关键字集为kw'={kw′1,kw'2,...,kw′t},该第二关键字集由若干第二关键字组成。
步骤42:根据所述第二关键字集生成所述陷门。
进一步地,步骤42还可以包括以下步骤:
步骤421:利用布鲁姆过滤器计算得到所述第二关键字集的字符集。
将每个第二关键字kw′i∈kw'映射到布隆过滤器相应的位置上,在设置该位置的值为kw′i的逆向词频idf值,记为tb’,数据查询者将kw′i转换成它对应的uni-gram字符集ls′i。
需要说明的是,布隆过滤器是一个m位的数组,在起始时全部设为0,给定集合{a1,a2,...,an},布隆过滤器使用k个独立的哈希函数
需要说明的是,逆向词频是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
式中,|d|:语料库中的文件总数;{j:ti∈dj}包含词语ti的文件数目(即ni,j≠0的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用1+{j:ti∈dj}。
因此得到tf-idf值tfidfi,j=tfi,j×idfi。
通过计算某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。
需要说明的是,tf-idf的核心思想是:如果某个词或短语在一篇文章中出现的频率tf高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。tf表示词条在文档d中出现的频率。idf表示如果包含词条t的文档越少,也就是n越小,idf越大,则说明词条t具有很好的类别区分能力。如果某一类文档c中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照idf公式得到的idf的值会小,就说明该词条t类别区分能力不强。如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。
步骤422:利用局部敏感哈希函数将所述字符集映射成对应的常数。
步骤423:根据所述常数计算得到所述陷门。
生成该陷门的整体算法为gentrap(skdu,kw',pb,atbs)→(tkw',atbs)。
选取
步骤5:根据所述用户属性和所述密钥对所述索引列表、所述文件签名以及所述陷门进行处理,完成解密运算。
进一步地,通过所述第一私钥和所述第二公钥将所述索引列表、所述文件签名以及所述陷门上传给所述云服务器进行存储;通过所述第三私钥将所述陷门上传给所述云服务器进行查询。
进一步地,步骤6包括搜索过程和解密过程。
搜索过程的整体算法为:search(atbs,tkw',i,c,pb)→(rst),rst指最后返回的结果。
云服务器使用自己的私钥及数据拥有者的公钥对数据拥有者的密文集进行解密。首先判断属性集atbs是否满足访问结构,如果属性集atbs不满足访问结构,返回⊥;否则,云服务器继续执行搜索算法,并验证搜索结果是否匹配成功。如果验证匹配成功,云服务器计算ψ,最终将
进一步地,对任意的属性atbj∈atbs,若节点y∈λ(γ),设atbj=atbs(y),云服务器计算
若节点y不是叶子节点,云服务器使用递归算法计算ey;假设z为y的所有子节点,计算所有的ez;令sy为包含ky个子节点z的集合,且ez≠⊥。如果集合sy不存在,则输出⊥;否则
进一步地,云服务器验证等式
需要说明的是,⊥表示无效休止符,表示前面的用户属性不满足,返回空集的意思。
需要说明的是,如果
进一步地,云服务器进行预解密运算,计算
进一步地,执行解密过程,通过数据拥有者的公钥验证密文及其身份的合法性,接着,用户计算ψσ和
请参见图3,图3为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索系统的结构示意图,本发明的另一个实施例还提供了一种基于属性加密的支持多关键字的模糊搜索系统,包括:可信任授权中心(ta)、数据所有者(do)、数据查询者(du)以及云服务器(csp);
可信任授权中心,可信任授权中心负责分发密钥给数据所有者和数据查询者。
需要说明的是,可信任授权中心在本方案中是完全可信的。
数据所有者,数据所有者首先采用对称加密方式对第一数据文件进行加密,然后根据cp-abe制定访问策略,生成相对应的索引列表和授权文件,并将其上传至云服务器。
数据查询者,授权用户根据密钥和第二关键字集生成对应的陷门,并将第二关键字集和陷门发送至云服务器进行查询。
云服务器,云服务器负责储存和计算大量的数据。
需要说明的是,本发明实施例中的云服务器是半可信的,即会忠诚的履行协议内容,也对用户上传的敏感数据感兴趣,当云服务器收到查询请求时,会首先验证书记查询者是否满足数据的访问策略,同时计算和匹配安全索引和陷门;当验证通过后,云服务器把第一数据文件部分解密后还给查询者,云服务器在撤销期间也承担着大量的计算任务。
本发明实施例的模糊搜索方法的过程大致为:数据所有者采用对称密钥对数据文件进行加密,然后提取关键字,根据cp-abe制定访问策略,加密对称密钥,生成相对应的索引列表和授权文件,并把其上传至云服务器。然后授权用户根据密钥和关键字集生成对应的陷门,并将关键字集和搜索陷门发送至云服务器进行查询。云服务器会负责储存和计算大量的数据。当云服务器收到查询请求时,会首先验证授权用户是否满足数据的访问策略,同时计算和匹配安全索引和搜索陷门。当验证通过后,云服务器把数据文件部分解密后返还给授权用户。最后,授权用户通过秘钥将密文解密得到明文的文件。
请参见图4~图9,图4为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的系统初始化时间的对比示意图;图5为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的密钥生成时间的对比示意图;图6为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的加密时间的对比示意图;图7为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的陷门生成时间的对比示意图;图8为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的搜索时间的对比示意图;图9为本发明实施例提供的一种基于属性加密的支持多关键字的模糊搜索方法的解密时间的对比示意图。图中,abks-ur和p2q分别指另外两种不同的搜索方法;ours指本申请的搜索方法;横坐标是属性数量,也就是查询的用户数量;本发明的另一个实施例还提供了本申请的方法与其他方法的性能分析,由图可知,在整个运行过程中,本申请的方法的运行时间都要比abks-ur和p2q这两种方法的运行时间短,也进一步证明了本申请的搜索方法消耗的时间少,节省了用户的时间成本。
本发明实施例提供的方法与之前的方案不同的是,本申请在基于属性的搜索方案之上,提出了一个同时支持模糊搜索和多关键字搜索的属性基搜索方案,采用局部敏感哈希函数lsh的相似性映射原理来实现了属性基可搜索加密中的模糊搜索,支持一些微小的拼写错误词和形近词的搜索。
此外,本发明实施例通过搜索词的散列值定位到索引关键词中相对应的位置,实现了多关键字的匹配,本申请可以一次匹配多个搜索词,当所有词均匹配时才返回相关结果,从而提高了搜索结果的准确性;进一步地,由于每个关键字在某个文件中的重要性是不一样的,通过相关分数对匹配文件进行排序,进一步提升搜索结果的准确性。
此外,该发明引入了可验证的外包解密技术,为了提高解密效率,采用对称密钥对明文文件进行加密,再将对称密钥采用cp-abe加密和外包解密,极大的降低了用户端的解密开销,最后可以采用摘要函数验证对称密钥的正确性和完整性。
在本发明的描述中,术语“第一”、“第二”、“第三”、“第四”、“第五”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”、“第三”、“第四”、“第五”的特征可以明示或者隐含地包括一个或者更多个该特征。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!