一种面向出行领域的车载多轮对话方法与流程
本发明属于人工智能技术领域,特别是面向出行领域的人车交互技术领域,涉及一种面向出行领域的车载多轮对话方法。
背景技术:
近年来,人机对话在在移动终端、智能家居、智慧医疗、智能网联汽车等各个领域的产品层出不穷,理解人类语言并能够与人类对话,给出相应信息反馈的机器人成为了大多数人的需求。任务驱动的多轮对话是人机对话的主要形态之一,目前国内外在任务型多轮对话系统方面的研究如火如荼,主要是针对智能客服领域,但是在出行领域,人车对话交互涉及多方面专有的知识,这使得这些对话系统无法满足人车交互的需要。
现有技术中,人车交互多采用关键词、关键句匹配的方式判断客户问题是否命中知识库,若严格限制用户的对话方式,则将造成对话过程机械、交互自然度低。且当用户对意图表述不清楚、对话过程中存在省略、重复等不符合语法逻辑现象,或是更改先前对话所提信息时,整个多轮对话周期会变长,降低了用户体验。
对于目前存在的问题,迫切需要开发一种针对特定领域的多轮对话交互技术,而大数据与深度学习近年来在自然语言处理方向的显著进展为车载多轮对话提供了新的思路。
技术实现要素:
有鉴于此,本发明的目的在于提供一种面向出行领域的车载多轮对话方法,实现在车载人机对话中提供快捷高效与人性化的用户体验。
为达到上述目的,本发明提供如下技术方案:
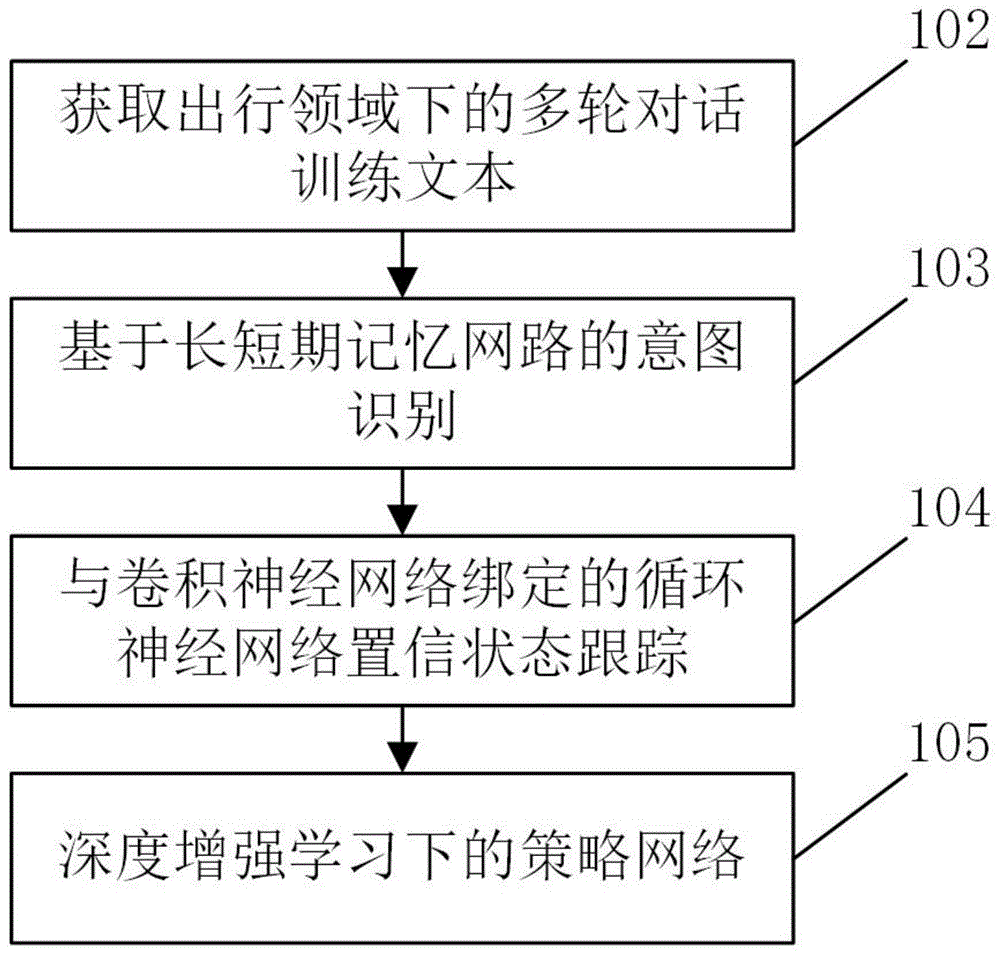
一种面向出行领域的车载多轮对话方法,该方法基于深度学习,所述深度学习包括:基于长短期记忆网路的意图识别、与卷积神经网络绑定的循环神经网络置信状态跟踪、深度增强学习下的策略网络;该方法包括以下步骤:
s1、获取出行领域下的多伦对话训练数据集,意图识别模型训练数据集与置信状态跟踪模型训练数据集,构建长短期记忆网络;
s2、对于给定的意图识别模型训练数据集,在超参数选择约束下,对学习模型进行训练与交叉验证,最终生成模型用于识别用户意图,并将结果提交给用于对话管理的策略网络;
s3、搭建与卷积神经网络绑定的循环神经网络进行置信状态跟踪任务,对每个槽构建专用状态跟踪器,利用卷积神经网络提取特征向量,通过循环神经网络计算对话置信状态;
s4、通过数据驱动训练置信跟踪器,并设计数据库查询方法进行查询;
s5、通过意图类别,置信状态和数据库真值向量构建对话状态,设计总体回报函数与q网络,搭建深度增强学习模型;
s6、通过调整q网络对迭代的bellman目标参数进行求解,利用出行领域的多轮对话数据集进行端到端的模型训练;
s7、依据对话状态的全局置信概率分布与策略回报选择所有可能的并行对话路径,最终生成下一时刻对话动作。
进一步,在步骤s1中,对多轮对话中的每一轮对话进行编码,得到对话的编码向量
其中it表示输入门,ft表示遗忘门,ot表示输出门,ci-1,ci表示储存信息的短期忆状态,wxc,whc是可训练的参数,hi-1表示隐藏层。
进一步,在步骤s3中,采用与卷积神经网络绑定的循环神经网络进行置信状态跟踪任务,用于维护和更新车载多轮对话的状态(对话状态是一种机器能够处理的数据表征,包含所有可能会影响到接下来决策的信息);
对每个槽构建专用状态跟踪器,每个跟踪器都由一个带有卷积神经网络特征提取器与jordan型循环神经网络构成;在每轮的话语语境中进行建模,设计特征向量
其中,尺寸为n的独热向量表示使用者输入ut和系统响应st-1;为了使跟踪器知道何时将去词汇化应用于一个槽或者值,槽值专用卷积神经网络运算
进一步,循环神经网络更新规则为:
其中向量ws,矩阵ws,偏置项bs和b′s以及标量gφ,s是参数,
进一步,在步骤s4中,置信跟踪器针对每个信息槽(可以用来约束搜索的槽,如票价范围)维持多项式分布p,并且维持每个请求槽(可询问值的槽,如地址)的二进制分布;
基于置信状态跟踪器的输出
其中si是一组信息槽;然后将该查询内容应用于数据库,在数据库实体上创建二进制真值矢量xt,其中1表示对应的实体与查询一致(因此它与最可能的置信状态一致);如果x不完全为空时,则关联实体指针保持标识随机选择的一个匹配实体;如果当前实体不再匹配搜索条件,则更新实体指针,否则保持不变;实体指针引用的实体用于形成最终系统响应。
进一步,在步骤s5-s7中,通过意图网络的zt,置信状态
定义增强学习预期总回报
构建含有动作值a的bellman方程
通过调整q-network对迭代的bellman目标参数进行求解,利用出行领域的多轮对话数据集进行端到端的模型训练,最终输出多轮对话该轮次的系统动作。
本发明的有益效果在于:本发明充分利用了大数据与深度学习近年来在自然语言处理方向的发展成果,能够为用户提供快捷高效与人性化的用户体验,在面向出行领域的车载多轮对话算法及系统对于任务型多轮对话具有重要的理论意义和应用价值。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为本发明面向出行领域的车载多轮对话方法的流程示意图;
图2为本发明面向出行领域的车载多轮对话系统总体框架图;
图3为本发明与卷积神经网络绑定的循环神经网络置信状态跟踪模型图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为本发明面向出行领域的车载多轮对话方法的流程示意图,本方法主要包括:a、基于长短期记忆网路的意图识别,设计长短期记忆网络更新规则与结构,对多轮对话中的每一轮对话进行编码,在超参数选择约束下训练验证网络,获得用户意图;b、与卷积神经网络绑定的循环神经网络置信状态跟踪,针对每个槽构建专用状态跟踪器,通过卷积神经网络提取特征向量,再利用jordan型循环神经网络进行对话状态跟踪,之后获取数据库查询真值矢量;c、深度增强学习下的策略生成,构建对话状态并定义增强学习预期总回报,采用动作值函数观察状态对应的预期回报,并利用神经网络近似动作值函数,构建含有动作值的bellman方程,通过调整q网络对迭代的bellman目标求解,通过多轮对话数据训练模型,最终得到该轮对话动作。
其中:对话意图识别过程包含以下3个步骤:1)采集出行领域的对话训练文本;2)构建长短期记忆网络,完成意图识别网络结构设计;3)在超参数选择约束下,对学习模型进行训练与交叉验证。
置信状态跟踪过程包含以下4个步骤:1)对每个槽构建专用状态跟踪器,设计其模型架构;2)搭建卷积神经网络,提取词语中间特征和句子表示特征,并设计特征向量为两个卷积神经网络派生特征的链接;3)设计循环神经网络的更新规则,迭代计算每轮用户所表达的内容的置信状态概率;4)训练置信跟踪器,并设计数据库查询方法进行查询。
对话策略生成过程包含以下3个步骤:1)设计总体回报函数与q网络,搭建深度增强学习模型;2)通过多轮对话数据进行端到端训练;3)依据对话状态的全局置信概率分布与策略回报选择所有可能的并行对话路径,生成下一时刻对话动作。
图2为本发明面向出行领域的车载多轮对话系统总体框架图,图3为本发明与卷积神经网络绑定的循环神经网络置信状态跟踪模型图。
具体来说本方法包括以下步骤:
s1、获取出行领域下的多伦对话训练数据集,意图识别模型训练数据集与置信状态跟踪模型训练数据集,构建长短期记忆网络。
对多轮对话中的每一轮对话进行编码,得到对话的编码向量
其中it表示输入门,ft表示遗忘门,ot表示输出门,ci-1,ci表示储存信息的短期忆状态,wxc,whc是可训练的参数,hi-1表示隐藏层。
s2、对于给定的意图识别模型训练数据集,在超参数选择约束下,对学习模型进行训练与交叉验证,最终生成模型用于识别用户意图,并将结果提交给用于对话管理的策略网络。
s3、搭建与卷积神经网络绑定的循环神经网络进行置信状态跟踪任务,对每个槽构建专用状态跟踪器,利用卷积神经网络提取特征向量,通过循环神经网络计算对话置信状态。
采用与卷积神经网络绑定的循环神经网络进行置信状态跟踪任务,用于维护和更新车载多轮对话的状态(对话状态是一种机器能够处理的数据表征,包含所有可能会影响到接下来决策的信息);
对每个槽构建专用状态跟踪器,每个跟踪器都由一个带有卷积神经网络特征提取器与jordan型循环神经网络构成;在每轮的话语语境中进行建模,设计特征向量
其中,尺寸为n的独热向量表示使用者输入ut和系统响应st-1;为了使跟踪器知道何时将去词汇化应用于一个槽或者值,槽值专用卷积神经网络运算
循环神经网络更新规则为:
其中向量ws,矩阵ws,偏置项bs和b′s以及标量gφ,s是参数,
s4、通过数据驱动训练置信跟踪器,并设计数据库查询方法进行查询。
置信跟踪器针对每个信息槽(可以用来约束搜索的槽,如票价范围)维持多项式分布p,并且维持每个请求槽(可询问值的槽,如地址)的二进制分布;
基于置信状态跟踪器的输出
其中si是一组信息槽;然后将该查询内容应用于数据库,在数据库实体上创建二进制真值矢量xt,其中1表示对应的实体与查询一致(因此它与最可能的置信状态一致);如果x不完全为空时,则关联实体指针保持标识随机选择的一个匹配实体;如果当前实体不再匹配搜索条件,则更新实体指针,否则保持不变;实体指针引用的实体用于形成最终系统响应。
s5、通过意图类别,置信状态和数据库真值向量构建对话状态,设计总体回报函数与q网络,搭建深度增强学习模型;
s6、通过调整q网络对迭代的bellman目标参数进行求解,利用出行领域的多轮对话数据集进行端到端的模型训练;
s7、依据对话状态的全局置信概率分布与策略回报选择所有可能的并行对话路径,最终生成下一时刻对话动作。
在步骤s5-s7中,通过意图网络的zt,置信状态
构建含有动作值a的bellman方程
通过调整q-network对迭代的bellman目标参数进行求解,利用出行领域的多轮对话数据集进行端到端的模型训练,最终输出多轮对话该轮次的系统动作。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!