中文篇章树的构建方法与流程
本发明涉及自然语言处理领域,具体涉及一种中文篇章树的构建方法。
背景技术:
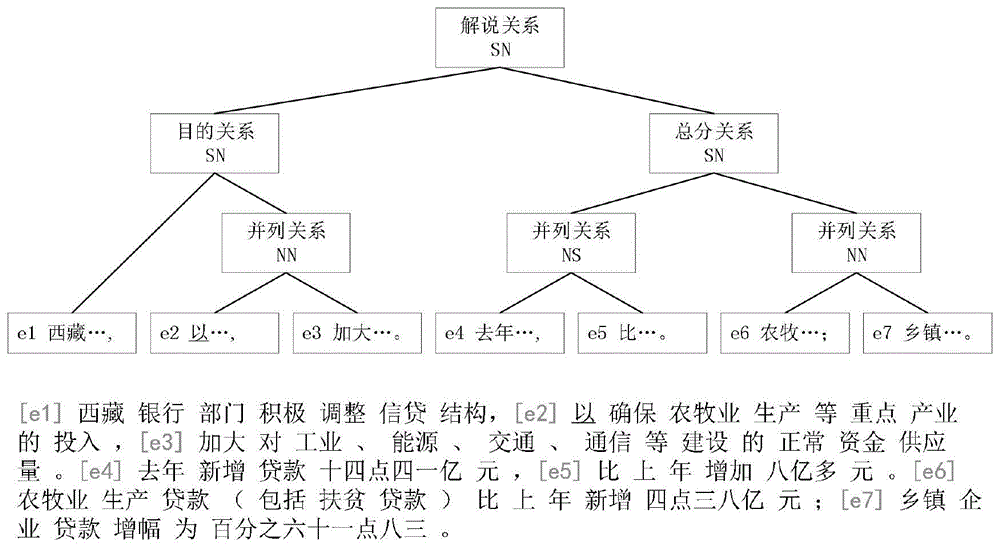
篇章分析(discourseparsing)旨在将序列形式的篇章分割成若干连续的篇章基本单元并采用自底向上或者自顶向下的方式将这些篇章基本单元合并,最终形成一棵篇章修辞结构树。一棵完备的修辞结构树的各相邻节点间分配了修辞关系和核性关系,这对许多自然语言处理应用有推动作用。图1中给出了利用篇章分析技术对一段篇章解析得到的篇章树的示例,叶节点为篇章基本单元,内部节点代表功能语句,各内部节点均标注了该节点的孩子节点之间的修辞关系和核性关系。
传统技术存在以下技术问题:
当前的篇章分析技术在英文篇章树库rst-dt中研究的最多。自2014年中文篇章树库cdtb发布以来,中文篇章分析技术才逐渐发展起来,但是关于中文篇章分析的研究还不够成熟,相关研究较少。此外,当前已出现的篇章解析器均采用自底向上的篇章树构建方式。在该模式中,篇章基本单元作为最小的功能语句先由修辞关系连接以合并成上层的更大的功能语句,这些功能语句之间自底向上不断合并,最终形成与该篇章对应的修辞结构树。自底向上的节点构建过程的局限性主要体现在两方面:1.难以并行计算;2.构建各个功能语句的根节点表征时无法考虑篇章的全局信息。所以,将自底向上的节点构建过程转换成自顶向下的分割点选择的过程是解决这两个问题的有效方法。
现有的篇章解析器均采用自底向上的解析模式,在该模式下,篇章级别的文本表征直接来自左右孩子,破坏了篇章原有的长序列结构,表征具有较强的模糊性。同时,人类在阅读长文本时,从整体到局部的阅读顺序会使得文章更容易被理解,而自底向上的解析模式与人类的这种行为逻辑相悖。此外,自底向上的解析方式使得模型的训练效率大打折扣,很难利用当前丰富的并行计算资源。
技术实现要素:
本发明要解决的技术问题是提供一种中文篇章树的构建方法,首次采用了自顶向下的篇章解析模式。在该模式下,我们的解析器将自底向上的节点表征问题转换为自顶向下的分割点的选择问题。在解析过程中,本发明最先选择的切割点所在的位置即为根节点位置,同样地,将切割得到的各个分部分别再做切割则得到各个分部对应的子树的根节点,重复这个操作直到所有分部均不可再分为止。该方法使得对顶端节点的预测过程中充分考虑了篇章的全局信息。同时,从整体到局部的篇章理解顺序也符合人类的行为逻辑。此外,本发明在技术上实现了批量处理,大大提升了篇章解析器模型的训练效率。
为了解决上述技术问题,本发明提供了一种中文篇章树的构建方法,包括:
从cdtb语料库中获取人工分割字句得到的标准篇章基本单元,依次将篇章中的各个篇章基本单元的词向量和词性标记向量拼接并输入eduencoder获取各个篇章基本单元的编码结果;
将eduencoder编码得到的各个篇章基本单元的向量表示输入splitencoder实现对相邻篇章基本单元之间的分割点的表征;
将splitencoder编码的当前功能语句中的分割点输入到encoder-decoder结构,编码端利用一个单向gru对分割点表征进行编码,解码端以篇章的首、尾分割点序号对初始化解码端的栈结构;
从栈中弹出顶层元素作为当前需要进行分割点挑选的区域,即功能语句区域;对当前区域的分割点进行挑选并以挑选出的分割点作为当前功能语句的根节点,从而将原功能语句划分成两个更小的功能语句并压入栈中;重复该步骤,直到所有功能语句不可再分;
由根节点开始,各功能语句以分割点位置为根节点分别以左、右功能语句对应的根节点为左、右孩子节点进行连接,最终解析得到对应的篇章修辞结构树。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
本发明的有益效果:
本发明首次采用了自顶向下的篇章解析模式,将传统的自底向上的篇章树节点的构建过程转换为自顶向下的分割点选择的过程。本发明中分割点的表征充分地考虑了篇章的全文信息,因而在进行分割点选择时充分考虑了篇章整体。本发明使用的编码-解码结构充分利用了分割点序列的串行特点实现了对篇章的批量解析。本发明运用biaffineattention同时实现了对分割点、分割点的核性关系和修辞关系的选择。在中文cdtb语料库上的测试结果表明:当前最好的中文篇章解析器相比,本发明在span,nuclearity和relation三个指标上均取得了最好性能。本发明在nuclearity预测上比当前最好的方法提升了近9.5%,在relation预测上比当前最好的中文篇章分析方法提升近10.4%。实验结果表明。本发明对于中文篇章分析的研究进展有重要的推进作用。
附图说明
图1是背景技术相关技术中中文篇章树的构建方法中的cdtb语料库中编号005文件中一个篇章树标准样例。
图2是本发明中文篇章树的构建方法中的edu编码器结构示意图。
图3是本发明中文篇章树的构建方法中的分割点编码器结构示意图。
图4是本发明中文篇章树的构建方法中的编码器-解码器结构示意图。
图5是本发明中文篇章树的构建方法的流程图。
图6是本发明中文篇章树的构建方法中的解码时可选分割点位置的概率分布示意图。
图7是本发明中文篇章树的构建方法自动解析图1实例得到的篇章树。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
篇章基本单元(elementdocumentunit,edu):也称子句,篇章中最基本的单位,具有相对独立的语义。
子句分割(edusegmentation):将一个完整的句子序列分割成若干个连续的篇章基本单元的过程。
功能语句(textspan):由若干连续的篇章基本单元构成,是篇章中功能明显的组成部分。
修辞结构理论(rhetoricalstructuretheory,rst):篇章基本单元和功能语句组成了篇章单元集合。篇章修辞理论具体将篇章分成若干篇章基本单元作为树的叶节点,以多个连续的篇章基本单元由特定关系连接而成的功能语句作为树的内部节点。相邻的有关联的篇章单元之间用特定的修辞关系(rhetoricalrelation)进行连接,用核性(nuclearity)关系标注出该修辞关系的主要部分(核星,nuclear)和次要部分(卫星,satellite)。
篇章树(discoursetree):根据修辞结构理论针对篇章的树结构表示,该树结构以篇章基本单元为叶节点,以功能语句为非叶节点,邻节点间以具体的篇章修辞关系和核性关系进行连接。
篇章分析(discourseparsing):是实现篇章修辞结构树自动构建的技术,主要包含子句分割和篇章树的自动构建两个部分,该技术的直接产物是篇章解析器(discourseparser)。给定一组连续的篇章基本单元,篇章解析器根据篇章修辞结构理论自动构建篇章树并为各相邻树节点之间分配合理的修辞关系以及核性标签。
中文篇章树库(chinesediscoursetreebank,cdtb):一个采用修辞结构理论构建的中文篇章树库,该语料库包含500篇文章,共2336个段落,是目前中文篇章分析领域中规模较大且具有代表性的语料库。
召回率(recall):系统正确抽取的事件个数占所有正确事件的比例。衡量事件抽取性能的指标之一。
准确率(precision):系统正确抽取的事件个数占所有抽取出的事件的比例。衡量事件抽取性能的指标之一。
f1指数(f1-measure):衡量事件抽取性能的综合指标之一,准确率(p)和召回率(r)的加权几何平均值,即:
本发明旨在提供一种高效的、高性能的中文篇章解析器,以解决现有中文篇章解析器的低准确率和低效率的问题。
针对现有技术存在的问题,本发明首次采用自顶向下的解析模式提出了一种能更好的结合全局信息的、高性能的中文篇章解析器。该解析器主要包括:篇章基本单元编码器(eduencoder)、分割点编码器(splitencoder)和一个针对分割点选择的编码器-解码器结构(encoder-decoder)。本发明的基本思想是:先用eduencoder编码篇章基本单元,再用splitencoder编码篇章基本单元之间的分割点,最后将分割点的编码结果输入encoder-decoder中选择分割点以形成左、右两个新的功能语句并选择两个功能语句之间的修辞关系以及核性关系。重复该分割点选择过程直到所有功能语句不可再分为止。以第一个分割点作为根节点,每个分割点左右两个功能语句各自对应的分割点作为该分割点的左右孩子节点,最终形成一棵完整的篇章树。这种序列的编码-解码模式使得本发明具备并行处理的能力。下面将介绍这三个主要部分在本发明中具体实现的技术方案。
eduencoder具体采用一个双向gru用于编码各个篇章基本单元。首先,从cdtb语料库中选取一组篇章的篇章基本单元(一批篇章并行处理),首先采用分词工具将这些文本序列切分成以词语为单位的序列。然后,借助预训练词向量和随机初始化的词性标签向量以拼接的方式建立篇章基本单元的词表征输入eduencoder,得到双向gru的最后一个状态
splitencoder用于编码篇章基本单元之间的分割点。首先,将eduencoder输出的一组篇章基本单元的特征向量输入一个双向gru,得到篇章基本单元的篇章级表征。在每个篇章的篇章基本单元的篇章级表征序列的首、尾各添加补位0向量表示开始和结束(无实际含义)。然后,使用一个宽度为2的带relu激活函数的卷积核扫过篇章基本单元的篇章级编码序列,得到相邻篇章基本单元之间的分割点表征。图3给出了分割点编码器的结构示意图。
encoder-decoder结构用于分割点选择。其中,编码端为一个双向gru网络,它以分割点编码器的输出作为输入(第i个输出hei即第i个分割点的表示)。解码端是一个包含栈结构的单向gru网络,解码段借助该栈结构存储待处理的分割点区域。编码、解码过程:首先,将这批篇章的分割点输入到编码器-解码器结构的编码端(双向gru)对分割点进行再编码并拼接gru的正、反向的最后一个状态向量作为解码端的初始状态。然后,用整个篇章的分割点序列的首、尾分割点的序号对初始化解码端的栈结构。在解码时,先弹出栈顶元素(首、尾分割点序号对)作为下一个要进行分割点选择的区域并将两个序号对应的编码端输出进行拼接并作为解码端的输入。紧接着,对解码端的输出和首、尾序号对之间的编码端输出做biaffineattention操作(下文将详细介绍biaffineattention),取分值最大的分割点作为当前功能语句的分割点并将功能语句划分为两个更小的功能。此时,若该分割点分割出来的两个新的功能语句中还有待选择的分割点,则将两个功能语句对应的两对新的分割点序号对压入栈中供下次处理,如图4所示。在技术细节上,因为栈的变化情况已知,所以在自顶向下解析的模式中可以实现批量解码。每次生成一批篇章的所有分割点首、尾序号对以及各个首、尾序号对区域中对应序号的一批编码端输出,在这批篇章的解码端输出和对应的一批编码端输出做批量的biaffineattention,从而实现对分割点、核性关系和修辞关系的批量学习和预测。
为了更直观地阐述本发明的分割点选择的实现,我们对图1中实例作编码-解码分析,如图5所示。首先,以分割点的特征表示(hs0...hs7)作为左边编码器的输入。其中,序号0和7分别表示篇章的开头和结尾,这两个分割点不参与解码过程中的分割点选择(将权重置为负无穷以屏蔽分割点)。解码端第1步用(0,7)初始化解码端栈结构并以[he0;he7]作为解码器的输入,对序号0到7之间的6个分割点的编码端的输出计算一次biaffineattention权重,得到权重最高的分割点序号为3(图中红色箭头表示该分割点权重最大)。此时,新的序号对(0,3)和(3,7)各自区域中均存在待处理的分割点,本发明采取先左后右的分割点选择顺序,因此依次将(3,7)和(0,3)压入栈等待继续处理。每次解码端选择分割点时,同时使用biaffineattention计算该分割点的核性和细粒度关系的概率分布。
biaffineattention在本发明中被用于确定分割点的位置、核性关系和篇章修辞关系,分别对应三个biaffineattention模型。每个biaffineattention做公式(1)、(2)和(3)的运算。在解码第j步,解码端的输出为hdj,需要求得第j步时编码端对应区域中各个分割点位置上的分数,i位置上的分数为
其中,k表示类别数(分割点挑选、核性分类和关系分类对应的类别数分别为1、3和17)。
此外,针对分割点、核性关系和修辞关系这三个学习目标,本发明采用负对数似然损失函数(negativeloglikelihoodloss)计算预测值和目标值之间的损失ls,ln和lr。为了权衡三个损失的学习,本发明采用三个平衡参数对三个损失进行汇总得到l=αsls+αnln+αrlr。本发明中还包含了其它重要参数以提供篇章分析的最佳性能,下面对本发明的系统设置和系统参数的取值情况作详细介绍。本发明使用了在人民日报数据集上预训练的300维的词向量,其余模型参数均使用随机初始化方法赋初始值。我们在划分好的的开发集上对模型进行调参,对超参数的设置如表1所示。
表1系统设置(模型超参说明)
性能说明
为了测试本发明的性能,我们选择使用cdtb语料来测试该解析器。cdtb是中文篇章分析中具有代表性的语料,它采用rst风格标注了各个段落的树结构、核性关系和修辞关系。该语料库共包含500篇文档,共2336个段落,每个段落被标注为一棵单独的篇章树。cdtb标注的篇章修辞关系主要被分为并列、解说、因果和转折这4个大类,每个大类内部又被细分为若干小类,共计17个小类。为了较为准确地反映本发明的性能,我们对数据集进行均匀划分,如表2所示。下表3是本发明在cdtb语料库上的测试结果。实验结果表明,本发明和现有的最好的中文篇章分析方法(yanyanjia,yansongfeng,yeyuan,lvchao,chongdeshi,anddongyanzhao.2018.improveddiscourseparsingwithtwo-stepneuraltransition-basedmodel.acmtransactionsonasianandlow-resourcelanguageinformationprocessing,17(2):1-21.和chengsunandfangkong.2018.atransition-basedframeworkforchinesediscoursestructureparsing.journalofchineseinformationprocessing,32(12):26-34)相比性能更好。对比发现,本发明在span,nuclearity和relation三个指标上和jia等人的工作相比有较大幅度的性能提升。本发明和sun等人的方法在span上的性能一致,但是我们的发明在核性关系和修辞关系预测上有较大优势。值得一提的是,本发明首次实现了对篇章的批量解析。综上所述,本发明一方面提升了中文篇章解析器的性能,同时也实现了篇章分析的并行处理,对篇章分析工作的研究进展有较大的推动作用。
表2cdtb数据集划分
表3中文篇章性能比较
为了更具体地阐述系统的实施情况,我们给出了本发明在上述系统设置和超参数下最终实施得到的篇章解析器在解码图1中实例的每一步对应各个分割点的权重分布情况,如图6所示。其中,实线框选中了每一步选择分割点时可选的分割点位置,分割点选择过程采用了从左到右的处理顺序,优先对当前分割点的左边区域进一步分析其分割点情况。
针对图6所示的分割点选择过程,本发明最终将图1中实例构建成一棵完整的篇章修辞结构树,如图7所示。各个节点标注了孩子节点之间的核性关系和修辞关系,整个树结构自顶向下的分布情况和图6中每一步的概率分布情况保持一致,图中标红部分为模型预测错误部分。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!