一种HDFS存储小文件的方法及装置与流程
本发明涉及大数据文件处理领域,具体地说是一种hdfs存储小文件的方法及装置。
背景技术:
随着数据的增长,数据处理得到结果需要更长的时间。而这些数据中又包含大量的小文件,这种文件的size小于hdfs上block的大小,这样会给hadoop的性能带来严重问题。
首先,在hdfs中,任何block、文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有10000000个小文件,每个文件占用一个block,则namenode大约需要3g空间。如果存储1亿个文件,则namenode需要30g空间。这样namenode内存容量严重制约了集群的扩展。
其次,namenode中的主内存大小限制了可以存储到hdfs中的文件的数量。此外,访问大量小文件速度远远小于访问几个大文件。hdfs最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
经对现有技术的文献检索发现,肖玉泽等在《小型微型计算机系统》(2015年第10期)上发表了题为“hdfs下海量小文件高效存储与索引方法”的期刊,文中提出了一种基于多维列索引的小文件管理方案,支持文件的并发上传、下载及删除操作,并在多个查询维度上提供文件的自由检索。该方法虽然可以提高一定的效率,但对于内存方面的消耗依然很大,且没有综合考虑企业的成本问题。
在本专利中,我们将重点讨论在hdfs中处理小文件的有效方法,以提高其性能。
技术实现要素:
本发明的技术任务是针对现有技术的不足,提供一种hdfs存储小文件的方法及装置。
本发明解决其技术问题所采用的技术方案是:
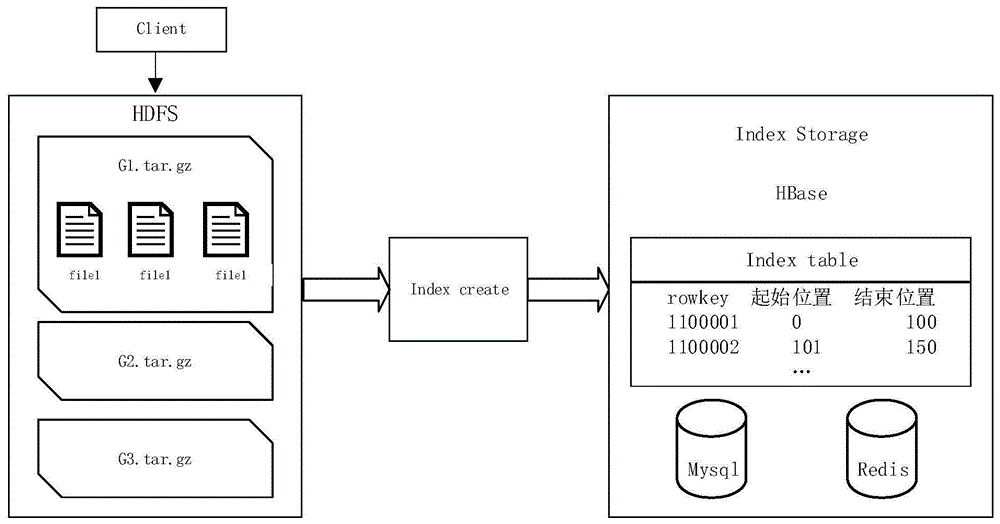
1、本发明提供一种hdfs存储小文件的方法,该方法通过“打包-构建索引-上传”的方式,来访问hdfs中的小文件,具体步骤如下:
i.文件保存:
1)将小文件上传至一个中转平台,文件以日期目录存储,每个文件都上传至当天日期的目录下;
2)编写脚本,设置定时任务,将当天之前创建的目录打包成tar.gz包,每天的文件只会产生一个目录,所以只会生成一个tar.gz包,将tar.gz包上传至hdfs;
3)编写gz解析程序,获取tar.gz包中文件的偏移量和长度;
4)获取文件的偏移量和长度后,设计hbaserowkey,将文件名和gz路径存放到rowkey中;
ii.文件查询获取:
5)根据文件的日期和文件名,先计算出hbaserowkey,再到hbase中获取该文件的偏移量和长度;
6)通过偏移量和长度调用hdfs去读取文件。
可选地,步骤2)具体包括如下步骤:
2.1)编写一个shell脚本,用于将指定目录下的文件夹打包成tar.gz包,命令为tar–zcvf20190101xxxx.tar.gz20190101;
2.2)在linux服务器上,通过crontab命令设计定时规则,定时执行shell脚本,shell脚本打包的是前一天的文件目录。
可选地,步骤3)具体包括如下步骤:
通过fseek()来计算文件的偏移量,函数设置文件指针stream的位置;
如果执行成功,stream将指向以fromwhere(偏移起始位置:文件头0(seek_set),当前位置1(seek_cur),文件尾2(seek_end))为基准,偏移offset(指针偏移量)个字节的位置;
如果执行失败(比如offset超过文件自身大小),则不改变stream指向的位置。
可选地,步骤6)中通过hdfs的api去读取文件的偏移量和长度。
可选地,步骤5)中到hbase中获取文件的偏移量和长度后,通过给hbaserowkey加盐存储,使其随机分布在hbasse中,避免热点现象。
可选地,步骤5)中加盐存储是指给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同;分配的前缀种类数量与想使用数据分散到不同的region的数量一致;加盐之后的rowkey就会根据随机生成的前缀分散到各个region上。
可选地,rowkey在设计时,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
2、本发明另提供一种hdfs存储小文件的装置,包括:
客户端,用于接收小文件,并将小文件上传至指定目录下;
hdfs,用于将指定目录下的文件夹打包成tar.gz包;
index构建模块,用于获取tar.gz包中文件的偏移量和长度,并根据该偏移量和长度构建对应的索引;
index存储模块,用于存储对应的索引。
可选地,index存储模块使用hbase分布式数据库、redis内存数据库、mysql关系型数据库结合的方式存取对应的索引。
本发明的一种hdfs存储小文件的方法及装置,与现有技术相比所产生的有益效果是:
针对现有hdfs在存储大量小文件并对其进行分析时,性能会受到影响。对于太多的小文件,映射器的数量会增加,而大量的文件会导致内存使用增加的问题,本专利通过打包构建索引的方式,提高了访问hdfs中的小文件的效率,节省了资源消耗。具体地:
该操作首先是依赖编写程序并设置定时任务,将文件按天归类打包;
其次设计有hbaserowkey,查询是也是通过hbaserowkey获取文件的偏移量和长度;通过偏移量和长度即可调用hdfs的api去读取文件。
附图说明
附图1是本发明的结构模块图。
具体实施方式
下面结合附图1,对本发明的一种hdfs存储小文件的方法及装置作以下详细说明。
结合附图1,本发明另提供一种hdfs存储小文件的装置,包括:
客户端,用于接收小文件,并将小文件上传至指定目录下;
hdfs,用于将指定目录下的文件夹打包成tar.gz包;
index构建模块,用于获取tar.gz包中文件的偏移量和长度,并根据该偏移量和长度构建对应的索引;
index存储模块,使用hbase分布式数据库、redis内存数据库、mysql关系型数据库结合的方式存取对应的索引。
本发明提供一种hdfs存储小文件的方法,该方法通过“打包-构建索引-上传”的方式,来访问hdfs中的小文件,具体步骤如下:
i.文件保存:
1)将小文件上传至一个中转平台,文件以日期目录存储,每个文件都上传至当天日期的目录下。
2)编写脚本,设置定时任务,将当天之前创建的目录打包成gz包(每天的文件只会产生一个目录,所以只会生成一个压缩包),将压缩包上传至hdfs。
定时策略:
编写一个shell脚本,用于将指定目录下的文件夹打包成tar.gz包,命令为tar–zcvf20190101xxxx.tar.gz20190101。在linux服务器上,通过crontab命令设计定时规则,可设计每天凌晨一点执行shell脚本,shell脚本打包的是前一天的文件目录。
3)编写gz解析程序,获取压缩包中文件的偏移量和长度。通过fseek()来计算文件的偏移量,函数设置文件指针stream的位置。如果执行成功,stream将指向以fromwhere(偏移起始位置:文件头0(seek_set),当前位置1(seek_cur),文件尾2(seek_end))为基准,偏移offset(指针偏移量)个字节的位置。如果执行失败(比如offset超过文件自身大小),则不改变stream指向的位置。
参考代码:
#include<stdio.h>
longfilesize(file*stream);
intmain(void)
{
file*stream;
stream=fopen("myfile.txt","w+b");
fprintf(stream,"thisisatest");
printf("filesizeofmyfile.txtis%ldbytes\n",filesize(stream));
fclose(stream);
return0;
}
longfilesize(file*stream)
{
longcurpos,length;
curpos=ftell(stream);
fseek(stream,0l,seek_end);
length=ftell(stream);
fseek(stream,curpos,seek_set);
returnlength;
}
4)获取文件的偏移量和长度后,设计hbaserowkey,将文件名和gz路径存放到rowkey中,并通过给hbaserowkey加盐等技术手段,使其随机分布在hbasse中,避免热点现象。hbase中存储的是文件的偏移量和长度,这样hbase中就保存了文件的元数据信息。
rowkey散列原则:
我们需要设计规则,使得数据不会集中出现在一个regionserver上,这样会降低查询效率。我们可以通过加盐的方式来避免散列现象,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上。
rowkey唯一原则:
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
ii.文件查询获取:
1)根据文件的日期和文件名,先计算出hbaserowkey,再到hbase中获取该文件的偏移量和长度。
2)通过偏移量和长度调用hdfs的api去读取文件。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
除说明书所述的技术特征外,均为本专业技术人员的已知技术。
- 还没有人留言评论。精彩留言会获得点赞!