基于深度相机的场景识别方法与流程
本发明属于移动机器人和计算机视觉技术,具体涉及一种基于深度相机的场景识别方法。
背景技术:
场景识别是移动机器人和计算机视觉领域中的重要技术,在许多实际应用中扮演着重要的角色。例如,在智能机器人领域的基于视觉的同时定位与建图技术(v-slam)中,当机器人运动到某个位置(场景)时,根据视觉传感器在该位置采集到的图像,场景识别(又称回环检测)能够帮助v-slam系统识别出移动机器人是否曾经到达过该位置。正确的场景识别结果能够帮助v-slam系统减少视觉里程计的累计误差,并且建立一致性的环境地图。
根据对场景(图像)的表征方式,场景识别方法可以分为两类:基于人工设计特点的方法和基于深度学习的方法。近几年,随着计算机视觉技术和深度学习理论的快速发展,越来越多的研究人员开始将深度学习技术运用到场景识别技术中。相较于传统的基于人工设计特征点的场景识别方法,基于深度学习的方法充分利用了深度神经网络——尤其是卷积神经网络强大的图像表征能力,通过卷积神经网络提取的图像特征具有更好的辨识性以及对环境的变化有更高的鲁棒性,从而使得该类场景识别方法能够取得更高的场景识别精度,并且应用于更复杂的环境中。
当前,移动机器人都配备多种传感器,其中就包括深度相机,深度相机不仅能够获得环境的彩色图像(即rgb)信息,还能够采集环境的深度信息,得到深度图像。然而,目前的场景识别方法——无论是基于特征点法,还是基于深度学习方法,几乎都仅使用彩色图像信息,使得现有方法都具有一定的缺陷,即在彩色图像信息丢失或者不完整的情况下,例如,光线很弱或者摄像头被遮挡等,仅依靠彩色图像的场景识别方法不能够正常工作。
技术实现要素:
本发明的目的在于提供一种基于深度相机的场景识别方法。
实现本发明目的的技术解决方案为:一种基于深度相机的场景识别方法,具体步骤如下:
步骤1、对深度图像进行预处理;
步骤2、将彩色图像和经过预处理的深度图像输入双路神经网络得到卷积层的输出,根据卷积层输出分别构建彩色图像和深度图像的特征向量,其中,所述双路神经网络由两个全卷积神经网络构成,所述全卷积神经网络为去除了最后的全连接层的卷积神经网络;
步骤3、将彩色图像特征和深度图像特征输入到训练好的特征融合神经网络进行融合,获得权重系数;
步骤4、根据步骤2中得到的特征向量和步骤3中的权重系数,计算待识别场景和数据库中的场景之间的相似度;
步骤5、将待识别场景和数据库中的场景之间的相似度与预先设定的阈值τ进行比较,如果相似度大于阈值τ,则判定二者为同一个场景。
本发明与现有技术相比,其显著优点为:1)本发明通过融合深度图像信息,能够在环境光照条件弱的情况下进行识别,提高了场景识别的可靠性,且场景识别精度高;2)本发明构建的深度神经网络结构能够同时处理彩色图像和深度图像,同时,所设计的特征融合网络具有样本自适应能力,训练后的特征融合网络能够根据输入信息自动调整特征两种特征的权重系数,具有更高的鲁棒性。
下面结合附图对本发明做进一步详细描述。
附图说明
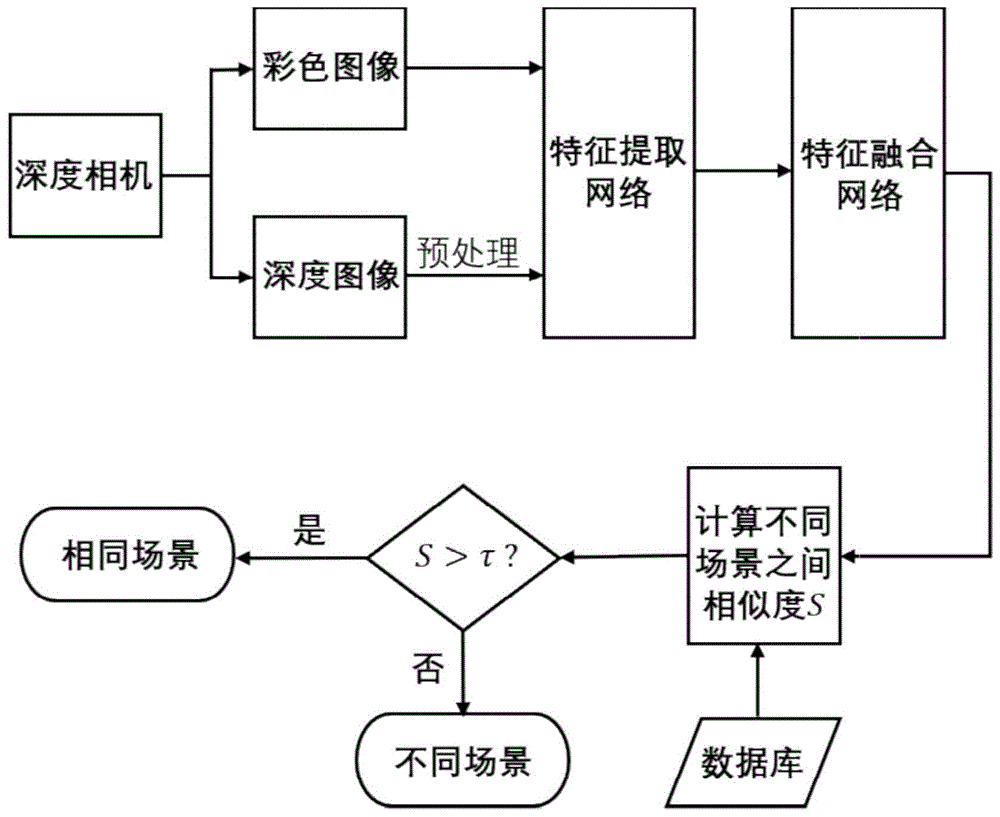
图1是本发明的流程图。
图2是本发明中的双路神经网络和特征融合神经网络的结构示意图。
图3是深度图像预处理示意图。
图4是在深度神经网络训练阶段所使用的网络结构示意图。
图5是在tum数据集上的triplet样本示意图。
具体实施方式
如图1所示,一种基于深度相机的场景识别方法,具体步骤为:
步骤1、对深度相机采集到的深度图像进行预处理。深度相机采集到的彩色图像和深度图像是不完全同步的,因此需要根据彩色图像和深度图像的时间戳进行对准,以获得成对的彩色-深度图像,一个彩色-深度图像对代表了一个场景。同时,深度相机采集到的深度图像为单通道,其像素值的大小代表了环境中的物体到相机的距离信息。本发明中将使用卷积神经网络提取深度图像特征,单通道的深度图像不能直接输入给神经网络,因此需要对深度图像重新编码,在某些实施例中,通过hha编码,将单通道的深度图像转化为三通道的图像,用于特征提取。如图3所示为一个原始深度图像经过重新编码的例子,单通道的深度图像经过编码被转换为3通道的图像,转换后的深度图像可以输入给双路神经网络进行特征提取。
步骤2、彩色图像和深度图像特征提取。本步骤中构建了一个特征提取网络,该结构由两路卷积神经网络构成,如图2左侧所示,分别用于彩色图像ir和深度图像id的特征提取,其中上角标r和d分别表示rgb彩色图像和depth深度图像。具体地,使用两个vgg-16网络模型作为特征提取器,卷积神经网络采用全卷积模型,即舍掉原有卷积神经网路最后的全连接层,基于最后一层卷积层的输出得到图像的特征向量。
将待检索场景记为pi对应的彩色图像
步骤3、彩色图像特征和深度图像特征融合。本步骤中构建了一种特征融合网络,如图2右侧部分所示,特征融合网络的输入为步骤2中得到的图像特征向量,输出为权重系数,代表了每种特征的重要程度,这个特征系数是输入特征向量的函数,并且通过特征融合网络预测得到;因此,经过训练,该网络能够根据输入信息自动调整不同样例的权重值,具体地,特征融合网络可由如下数学式表达:
其中,m表示特征的种类索引,即彩色图像特征(r)或深度图像特征(d),m=2表示特征种类的数量;vm和
进一步的实施例中,特征融合网络结构由两路神经网络组成,每一路包含两层全连接层,最后通过softmax层连接。其中第一层全连接层的大小为512×512,第二层全连接层的大小为512×1。
步骤4、根据步骤2中得到的特征向量和步骤3中的权重系数,计算待识别场景和数据库中的场景之间的相似度,相似度的计算方法如下:
根据步骤2中得到的特征向量和步骤3中得到的权重系数,待检索场景pq和数据库中场景pi之间的相似度根据以下公式得出:
sqi=1-dqi
其中,i=1,2,3,...,n,n为数据库中场景的个数;dqi为两个场景是之间的距离,具体为:
其中,wm为权重系数,
其中,||·||2表示向量的2-范数运算符。
步骤5、将待识别场景和数据库中的场景之间的相似度与预先设定的阈值τ进行比较,如果相似度大于阈值τ,则判定二者为同一个场景。
本发明中构建的双路神经网络和特征融合神经网络,在用于场景识别之前,首先需要在训练数据集上进行训练,本发明提供一种基于triplet损失函数的端到端的训练方法。在训练阶段,用于计算triplet损失的网络结构如图4所示。首先在训练数据集上生成triplet样本,一个triplet样本包含3个场景,6张图像,3张彩色图像和3张深度图像,即待检索场景
l=max(dqp-dqn+c,0)
其中,dqp和dqn分别为场景pq与正相关场景pp和相关场景pn之间的距离,距离的计算方法如步骤4中所示。
triplet训练样本的对于神经网络的训练非常重要,triplet样本的质量会直接影响训练效果。以tumrgb-d数据集中的fr2_pioneer_slam集合为例说明本发明中生成triplet的方法。fr2_pioneer_slam数据集提供了每个场景所对应的相机的地理位置和姿态真值。给定场景pq,根据所给真值,计算任意场景之间的距离t和相机角度差a,其中,角度差a取三个方向角度差的最大值。如果某个场景满足:t<0.3m且a<15°,则该场景被认为是正相关场景;如果某个场景满足:t>1.0m且a>80°,则该场景被认为是负相关场景。
- 还没有人留言评论。精彩留言会获得点赞!