一种本体和句法依存结合的微博情感分析法的制作方法
本发明属于文本情感分析技术领域,特别涉及一种本体和句法依存结合的微博情感分析法。
技术背景
随着移动互联网的普及,微博作为社交平台,在拥有大量用户的基础上,已经成为新闻热点事件最快的消息来源。由于用户的粘度高,微博包含了海量的网民日常信息,其中包括对于各产品的使用评价。而因为一些原因,产品自身网店的评价数据不够客观,反之因为微博的日常性,用户评价更客观,更具有挖掘价值。因此对于企业来说,从微博中获取用户对产品的评价并加以情感分析,是企业决策必备的信息基础。
微博数据以文本数据为主,对于文本数据的情感倾向分析是近几年研究的热点,主要分为机器学习和本体分析两种方式。基于机器学习的方法中分类器多基于人工构建,在针对大型数据集时建模过程过于复杂和冗长,且人工操作较难。为了解决上述问题,本体的构建方法被提出。本体是一种形式化的,对于共享概念体系的明确而又详细的说明,它能够从语义层面上描述概念。上述基于本体的情感分析在本体初始构建之后,均不会更新本体,在实现过程中对初始构建的准确性要求过高,事实证明本体的维度会随数据的扩充而增大。
技术实现要素:
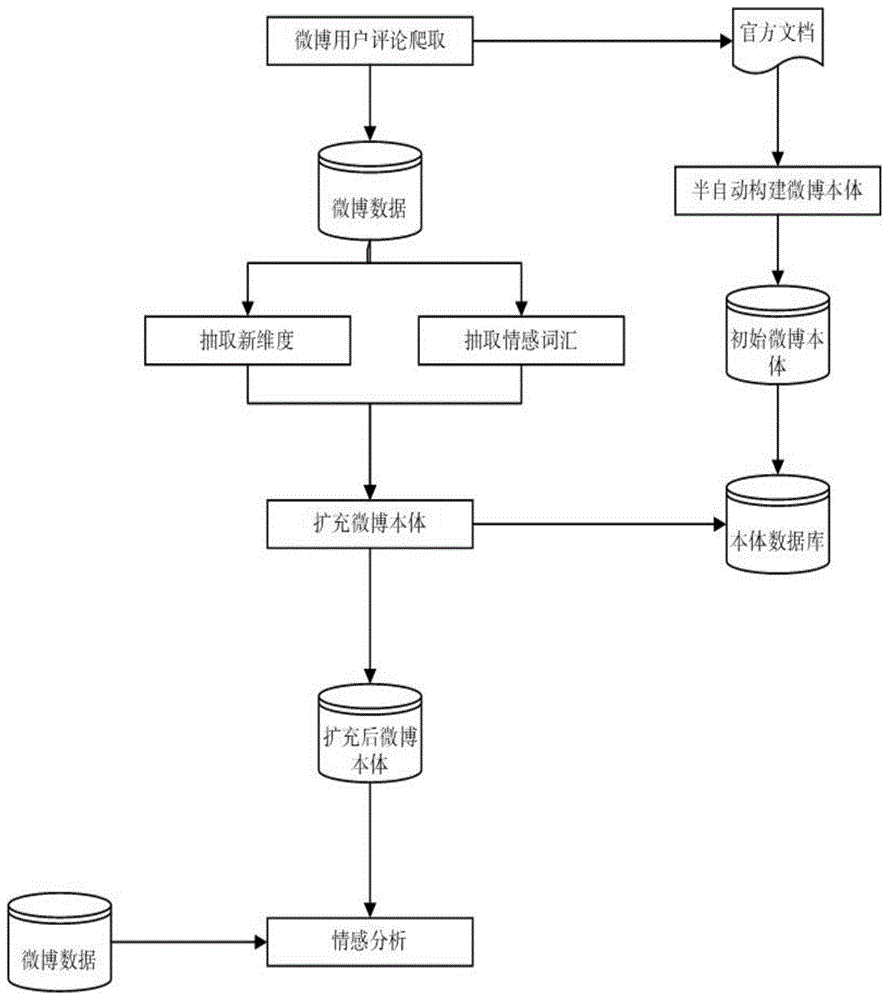
本发明提出了一种本体和句法依存相结合的微博情感分析方法,目的是更准确地从微博中获取相关情感信息。对于微博信息半自动构建其初始本体,然后依照相关的文本数据,利用句法依存分析原理从产品维度、情感词汇两个方面自动化更新和优化本体,从而得到成熟本体。再借用成熟本体,利用本发明提出的新情感权值计算方法,衡量文本数据的情感权值和倾向性,从而准确地实现情感分析。
本发明的技术方案如下:
一种本体和句法依存结合的微博情感分析法,包括以下步骤:
步骤(1):半自动构建主题相关的本体,并将本体持久化到数据库;
步骤(2):利用句法依存关系对本体从本体维度和情感词汇两个方面进行扩充和更新;
步骤(3):利用本体对微博信息进行情感权值计算,确定情感倾向。
进一步的,所述的步骤(1)具体为:
步骤(1.1):通过protégé软件采用七步法传统构建方法构建本体:明确构建本体所属领域范畴;考虑复用本体的可能性;陈列领域重要术语;定义类及其等级体系;定义类的属性;定义属性的分面;创建实例;
步骤(1.2):使用jena包将本体转换成数据库,从语义层面提取数据,并将其转化为模型数据的获取来源是数据库或文件。
进一步的,步骤(1.2)中的转换的过程如下:
①安装好必要的软件并配置好开发环境eclipse+mysqlserver5.5-win32+jena2.6.4+protege5.1.0+mysql-connector-java-5.1.35(mysql的jdbc);
②用protege5.1.0构建好产品本体,并主动生成owl本体文件;
③利用mysql创建一个数据库;
④打开eclipse,新建一个java工程;
⑤新建工程的同时,分别导入jena包和mysql的jdbc;
⑥在工程目录下新建一个java类,名字为military_ontology.java;
⑦在military_ontology.java中开始编写代码并运行;
⑧成功将本体转换为数据库;
使用jena将初始本体转换成功后会生成7张表,jena_g1t1_stmt是存储本体内容的表。
进一步的,所述的步骤(2)具体为:
步骤(2.1):通过句法依存分析技术对产品本体的本体维度进行扩展:句子中存在述语动词作为支配其它成分的中心,而述语动词本身不受其它成分支配,受支配成分以某种依存关系从属于支配者,存语法结构是以依存关系作为主要元素,即词对二元关系组,在二元关系中,支配者称为核心词,从属者称为依存词,使用stanfordparser句法依存分析器进行句法分析:
stanfordparser对于句法关系以类型化依赖关系来进行扩展选择,在扩展维度时关注包含关键词的两个关系式,即nn和assmod,nn表示的是名词组合形式,assmod表示关联修饰,基于两个名词短语的依赖关系;对于新获得的下属维度,将发现好的关系存入本体数据库步骤如下:首先设置新维度类型为class,然后将其列为对应父维度的子类;
步骤(2.2):对于情感词汇的扩充方式如下:利用stanfordparser,在句法依赖分析的基础上,扩充情感词汇关注另外两个关系式,即amod和nsubj,amod表示形容词修饰语,即常见的名词前形容词,nsubj表示名词性主语,用于表示主语和宾语之间的联系;情感词汇属于实例,插入本体数据库的步骤如下:首先设置其类型为namedindividual,然后依照描述类别将其列为该类别的情感词汇,最后将其情感权值插入数据库,情感权值从情感词典中获得。
进一步的,所述的步骤(3)具体为:
对每句话情感权值采用的计算公式是:
其中n是一句话包含的情感词数,prii指的是否定词权值,在计算情感权值时如果单词i是否定词修饰的词,则需乘上否定词的权值,一般为负数,如果否定词的权值词典中不包含,则默认为-1;valuei指的是单词本身的情感权值,来源于情感权值词典;
dimeni表示第i个词语所在维度的权值,其计算公式如下:
dimeni=perclass_i*perwords_i
其中perclass_i指的是第i个词语所在维度的下属类在整体类中占的数量比例,perwords_i指的是第i个词语所在维度的情感评估词数在整体评估词中占的数量比例;
在查询维度类和情感词时使用本体自带的sparql查询语言,使用jena包的接口从已经转成数据库的本体中利用sparql语句提取出和类、实例相关的数据;
tii是指词语的tf*idf权值,其计算公式如下:
tfij是指单词的tf值,用来表示某个词在当前文档中出现的比例,其中分子表示单词ti在文档j中出现的次数,分母表示文档j所有单词数之和;idfij是单词idf值,称为逆向文件频率,指的是文件总数目除以包含关键词的文件数目,再取对数得到的结果,其中分子表示文件总数,分母表示包含单词ti的文件数目之和,为了保证分母永正,分母部分加1;
利用本体自带的sparql查询语句,对于每一句语句直接进行词匹配,以找到其在本体中的维度和情感类别及权值,再运用上述公式即可算出情感权值。
附图说明
图1是本体和句法依存相结合微博情感分析流程图。
图2是鸿茅药酒本体部分展示图。
图3是本发明所计算情感指数与svm和朴素贝叶斯分类器分类效果对比图。
具体实施方式
为使本领域的技术人员更好地理解本发明的技术方案,下面对本发明提供的一种本体和句法依存结合的微博情感分析法进行详细描述。以下实施例仅用于说明本发明而非用于限制本发明的范围。
实施例
一种本体和句法依存相结合的微博情感分析方法,包括以下步骤:
1、微博数据的前期处理
对于爬取的微博数据需要进行前期处理,主要包括:
(1)统一中英文标点符号,统一全角和半角符号;
(2)将表情符号直接转换为对应的中文;
(3)去除“回复:”“回复天气好:”“回复@天气好:”等关于回复的冗余信息;
(4)去除特殊符号『|〔|〕|$|丨|「|」|△|▲|▼|▍|■等;
(5)去掉除了,。!等表分割句子的其他标点符号;
(6)利用结巴分词进行词汇分割;
(7)去除停用词。
2、初始本体的创建和持久化
(1)本体的半自动创建
本发明在构建时采用七步法传统构建方法。七步法相对其他方法步骤清晰,逻辑简洁,易于操作。七步法由斯坦福大学医学院开发,是一种比较通用的本体构建方法。其七个步骤分别是:明确构建本体所属领域范畴;考虑复用本体的可能性;陈列领域重要术语;定义类及其等级体系;定义类的属性;定义属性的分面;创建实例。
本发明使用工具protégé(stanforduniversity,1999)半自动构建本体。protégé软件是斯坦福大学医学院生物信息研究中心开发的本体构建工具。其基于java语言编写,属于开放源代码软件。protégé为用户屏蔽了具体的本体描述语言,用户不需具体学习本体的编写语言,只需利用软件提供的快捷方式来描述即可。
(2)本体的持久化
对于半自动构建的本体,需要在数据处理过程中不断扩充和修改本体,因此必须要将本体持久化,变的容易处理,本发明使用jena包(hplabs,2009)将本体转换成数据库。jena是一个java开源框架,主要用于从语义层面提取数据,并将其转化为模型。而数据的获取来源可以是数据库或文件等。如果想在语义模型内查询数据,jena也提供了查询语言,即sparql。
本发明使用jena包将本体转换成数据库。转换的过程如下:
①安装好必要的软件并配置好开发环境eclipse+mysqlserver5.5-win32+jena2.6.4+protege5.1.0+mysql-connector-java-5.1.35(mysql的jdbc);
②用protege5.1.0构建好产品本体,并主动生成owl本体文件;
③利用mysql创建一个数据库;
④打开eclipse,新建一个java工程;
⑤新建工程的同时,分别导入jena包和mysql的jdbc;
⑥在工程目录下新建一个java类,名字为military_ontology.java;
⑦在military_ontology.java中开始编写代码并运行;
⑧成功将本体转换为数据库。
使用jena将初始本体转换成功后会生成7张表,本体信息存储在jena_g1t0_reif表中,其他的表无需关注。
3、基于句法依存关系的本体扩展
本发明使用基于中文句法的依赖关系实现产品本体自动扩展。主要关注点是用户评论中的句法,利用句法关系去发现产品本身或产品某一维度的对应描述词或下级属性。因为应用对象是产品本体,在自动扩展时只需关注产品和产品维度的评价指标,无需考虑不相关词汇。本体的自动扩展主要包括两个方面。
(1)扩展本体各维度
对于产品本体的本体维度进行扩展。由于在初始建立本体时不能完全保证全面,所以需要随着数据的处理逐渐扩展本体。扩展本体维度主要用到的技术是句法依存分析。
句法依存由法国语言学家tesiniere于1959年提出。方法的核心思想是:句子中存在述语动词作为支配其它成分的中心,而述语动词本身不受其它成分支配,受支配成分以某种依存关系从属于支配者。依存语法结构是以依存关系作为主要元素,即词对二元关系组。在二元关系中,支配者称为核心词,从属者称为依存词。依存关系就反映了核心词和依存词之间的语义依赖关系。
本发明使用stanfordparser(stanforduniv-ersity,2002)进行句法分析。stanfordparser是由斯坦福大学自然语言处理小组开发的句法分析器,是一个高度优化的概率上下文无关文法和词汇化依存分析器,原理来自于概率统计。目前有开源的java实现软件包可使用,支持英文、中文、德文在内多国语言。
stanfordparser对于句法关系以句法分析树和类型化依赖关系等多种方式输出,本发明选用类型化依赖关系来进行扩展选择。软件提供的依赖关系有多种,本发明在扩展维度时主要关注包含关键词的两个关系式,即nn和assmod。nn表示的是名词组合形式,比如当获取到一组nn关系式为“广告成本”,则可获知“成本”是“广告”的下属维度;assmod表示关联修饰,主要是基于两个名词短语的依赖关系,比如当获取到一组assmod关系式为“药酒广告”,则可获知“广告”是“药酒”的下属维度。
对于新获得的下属维度,将发现好的关系存入本体数据库步骤如下:首先设置新维度类型为class,然后将其列为对应父维度的子类。表1展示了新的维度扩展插入到数据库需要增加的条目。
表1新维度扩展插入到数据库
(2)扩充情感词汇
在本体初始构建的时候会加入普遍情感词汇,然而在分析具体产品时,针对不同维度需要不同的维度情感词汇,这些词语大多要从实际数据中获取,在前期准备中比较难收集较全面。
扩充情感词汇的方式是与上一节相同,利用stanfordparser。在句法依赖分析的基础上,扩充情感词汇更加关注另外两个关系式,即amod和nsubj。amod表示形容词修饰语,即常见的名词前形容词,比如amod关系式为“虚假广告”,则可获知“虚假”是“广告”的情感词汇;nsubj表示名词性主语,主要用于表示主语和宾语之间的联系,比如nsubj关系式为“声明无耻”,则可获知“无耻”是“声明”的情感词汇。
情感词汇属于实例,插入本体数据库的步骤如下:首先设置其类型为namedindividual,然后依照描述类别将其列为该类别的情感词汇,最后将其情感权值插入数据库,情感权值从情感词典中获得。表2展示了新的维度情感词汇插入到数据库需要增加的条目。
表2维度情感词汇插入到数据库
4、情感权值计算
本体扩展更新完成之后,需要对数据进行情感分析。传统的情感分析多是情感权值直接相加,此方法误差太大。为了避免这种情况,本发明利用基于本体维度的情感权值分析方法。该方法在计算情感权值时将情感词在本体中的维度指标考虑进去,能够更全面的反应情感词的作用。
在情感计算之前,进行了前期准备,主要是多种字典的引入。包括:情感权值词典、否定词词典和同义词词典。情感权值词典选用清华大学中文系情感词典,其包含的是词语自身的情感权值。否定词词典选用江苏科技大学使用的否定词典,否定词典的作用是为了将权值取反,如果词语前面存在否定词,那后面的词权值应当翻转过来。同义词词典选用哈工大社会计算与信息检索研究中心同义词词林,是为扩充本体而用,每个词语的同义词可以作为同类维度扩充进本体中,这样在查找或者判断维度时就更准确;其次,当情感字典中不包含某个词的权值时,可以利用该词的所有同义词权值,取其平均值作为该词的情感权值。
对每句话情感权值采用的计算公式是:
其中n是一句话包含的情感词数,dimeni表示第i个词语所在维度的权值,其计算公式如下:
dimeni=perclass_i*perwords_i
其中perclass_i指的是第i个词语所在维度的下属类在整体类中占的数量比例,perwords_i指的是第i个词语所在维度的情感评估词数在整体评估词中占的数量比例。
在查询维度类和情感词时只需使用本体自带的sparql查询语言即可,jena包提供了接口,可以从已经转成数据库的本体中利用sparql语句提取出和类、实例相关的数据。
tii是指词语的tf*idf权值,其计算公式如下:
tfij是指单词的tf值,用来表示某个词在当前文档中出现的比例,其中分子表示单词ti在文档j中出现的次数,分母表示文档j所有单词数之和;idfij是单词idf值,称为逆向文件频率,指的是文件总数目除以包含关键词的文件数目,再取对数得到的结果,其中分子表示文件总数,分母表示包含单词ti的文件数目之和。为了保证分母永正,分母部分加1。
prii指的是否定词权值,在计算情感权值时如果单词i是否定词修饰的词,则需乘上否定词的权值,一般为负数,如果否定词的权值词典中不包含,则默认为-1。valuei指的是单词本身的情感权值,来源于情感权值词典。
利用本体自带的sparql查询语句,对于每一句语句可以直接进行词匹配,以找到其在本体中的维度和情感类别及权值,再运用上述公式即可算出情感权值。
采用从微博爬采取关于鸿茅药酒的真实中文评论,具体步骤如下所示:
1.利用爬虫爬取鸿茅药酒相关微博,进行前期处理、利用结巴分词进行分词,然后去掉停用词。
2.依照消费者评价指标、鸿茅药酒官方文档以及微博评论等内容构建鸿茅药酒本体。图2是构建的鸿茅药酒本体部分图示。
3.利用protégé构建好初始本体后,使用jena包将本体转换到数据库。
4.本体转换到数据库完成后,进行本体扩展。本体扩展按照方法从本体维度、情感词汇另两个方面进行。
5.从微博数据中挑选代表性微博进行人工情感标准,最终得到1000条正面评价和1000条负面评价。
6.然后本发明的公式对挑选出的微博进行情感权值的评定,确定其情感极性。
7.利用传统的svm分类器和朴素贝叶斯分类器同样对微博情感进行标注,利用准确率、召回率和f值进行评定比较。图3展示了本发明使用方法与传统机器学习方法svm和朴素贝叶斯的对比情况,其中横轴代表实验的不同方法,纵轴代表数值。通过比对发现,本发明可以更精确更细致地分析出产品微博情感倾向。
本实施例提供了一种面向中文微博的,基于情感本体和句法依存相结合的情感分析方法。具体包括以下步骤:对于要分析的主题利用爬虫进行微博信息采集,采集之后进行数据清洗和降维,然后利用主题相关的微博信息和官方文档进行半自动构建初始本体,然后利用微博数据,从产品维度和情感词汇两个方面自动化更新本体,从而得到成熟本体。再借用本体携带的信息计算微博信息的情感权值,从而达到分析微博数据的情感倾向性的目的。最后使用精准率、召回率和f值作为评价标准,与传统机器学习分类算法进行比较,本发明在中文微博数据集上具有可行性和优越性。
上面结合实施例对本发明的实例作了详细说明,但是本发明并不限于上述实例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出的各种变化,也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!