一种基于自步约束机制的可监督图像分类方法与流程
本发明涉及的图像分类识别技术领域,尤其涉及一种基于自步约束机制的可监督图像分类方法。
背景技术:
对包含大量对象类别的自然图像进行分类是模式识别中最具挑战性的问题之一,主流解决方案包括小波关联向量机(wrvm)、全局和局部显著性特征编码和词包模型(bow),以往的图像分类算法一直专注于获取图像特征的可视化表示,而忽略了特定类的信息,为发现一种更适合数据表示的方法,大量的方案已被开发来解决这个问题,最近在这些已开发的模型中,带有监督的稀疏表示分类技术因其强大的图像建模能力引起了许多人的兴趣,许多研究表明,这种基于稀疏表示的分类(src)算法在计算机视觉研究中的表现非常出色,然而,当面对包含噪声和巨大类内变化的复杂样本时,监督字典学习机制将不再适用,此外,从复杂的训练样本中学习一本有鉴别力和代表性的词典也仍是一个挑战。
技术实现要素:
本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
鉴于上述现有基于自步约束机制的可监督图像分类方法存在的问题,提出了本发明基于自步约束机制的可监督图像分类方法,其所解决的是如何基于自步约束机制的可监督图像分类问题。
因此,本发明目的是提供一种基于自步约束机制的可监督图像分类方法,其通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行不断训练,可构成具体自步约束的图像分类方案,便于利用更多的判别信息,且对样本噪声具有鲁棒性,从而可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
为解决上述技术问题,本发明提供如下技术方案:通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行训练,此过程可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
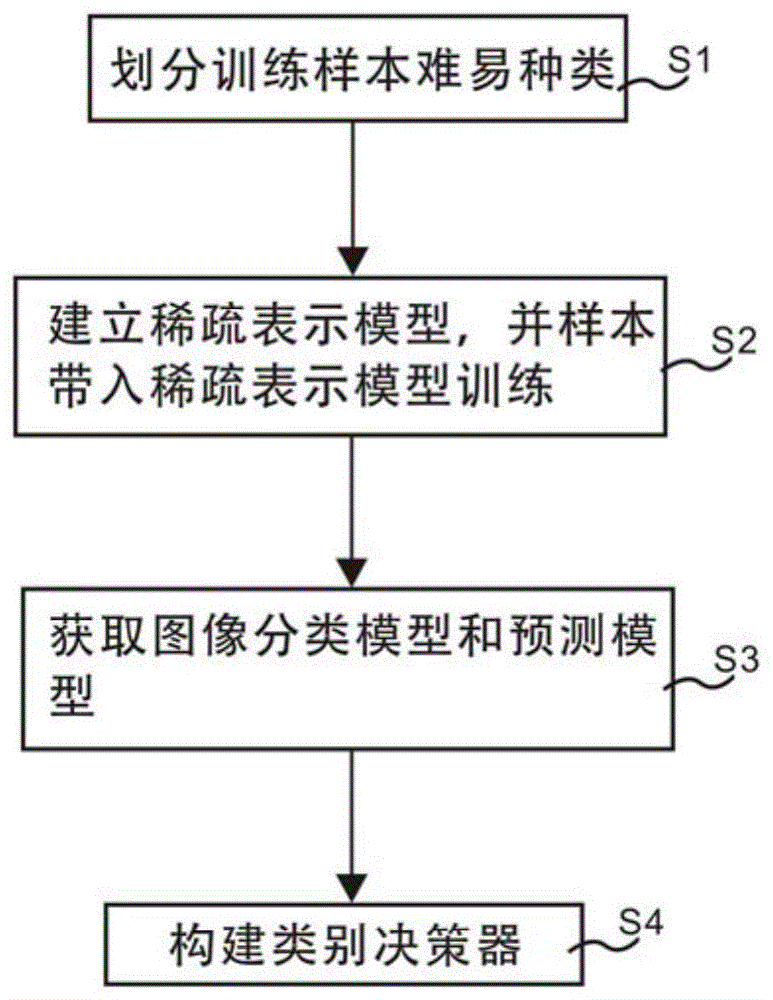
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:一种基于自步约束机制的可监督图像分类方法,包括,划分训练样本难易种类;建立稀疏表示模型,并样本带入稀疏表示模型训练;获取图像分类模型和预测模型;以及,构建类别决策器;其中,所述训练样本难易种类包括训练易样本和训练难样本。
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述划分训练样本难易种类采用自步约束矩阵划分。
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述自步约束矩阵v为:
其中,ai,j表示一个属于第i类的第j个训练样本,i=1,...,k,j=1,...,ni,k是类的总数,y表示测试样本,λ为参数,v(ii)=1表示训练易样本,v(ii)=0表示训练难样本。
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述稀疏表示模型为与自步约束正则化相关的模型。
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述稀疏表示模型定义为:
其中,学习词典中的类标签表示为d=[d1,d2,...,dk],其中di是与类i关联的子集,ai表示输入的样本数据,a=[a1,a2,...,ai],ai=[ai1,ai2,...,ain],xi是d中ai的子矩阵,
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述获取图像分类模型和预测模型的步骤包括:
训练训练易样本;
更新x;
获取稀疏代码x、系数代码d和自步约束的加权系数α;
确定图像分类模型和预测模型。
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述更新x的步骤包括:固定字典d和α,公式(2)进一步重写为:
即,
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述获取稀疏代码x、系数代码d和自步约束的加权系数α的步骤包括:更新d=[d1,d2,......,dk],z和α固定时获得,即公式(2)为:
其中,
即公式(4)为:
其中,
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述确定预测模型ei采用如下公式:
其中,
作为本发明所述基于自步约束机制的可监督图像分类方法的一种优选方案,其中:所述类别决策器采用如下公式:
identity(y)=argmini{ei}。
本发明的有益效果:本发明通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行不断训练,可构成具体自步约束的图像分类方案,便于利用更多的判别信息,且对样本噪声具有鲁棒性,从而可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
图1为本发明基于自步约束机制的可监督图像分类方法第一个实施例的整体结构示意图。
图2为本发明基于自步约束机制的可监督图像分类方法第二个实施例所述的获取图像分类模型和预测模型步骤示意图。
图3为本发明基于自步约束机制的可监督图像分类方法第三个实施例的验证流程示例图。
图4为本发明基于自步约束机制的可监督图像分类方法第四个实施例的caltech-101数据库的示例图。
图5为本发明基于自步约束机制的可监督图像分类方法第四个实施例的在caltech-101数据集上验证结果示意图。
图6为本发明基于自步约束机制的可监督图像分类方法第四个实施例的voc2012数据库的示例图。
图7为本发明基于自步约束机制的可监督图像分类方法四第个实施例的在voc2012数据库上验证结果示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
再其次,本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
实施例1
参照图1,提供了一种基于自步约束机制的可监督图像分类方法的整体结构示意图,如图1,一种基于自步约束机制的可监督图像分类方法包括s1:划分训练样本难易种类;s2:建立稀疏表示模型,并样本带入稀疏表示模型训练;s3:获取图像分类模型和预测模型;以及,s4:构建类别决策器;其中,训练样本难易种类包括训练易样本和训练难样本。
具体的,本发明主体结构包括s1:划分训练样本难易种类,操作人划分数据库图像,将其区分为训练样本和测试样本,在此对训练样本进行难易度划分,其中,训练样本难易种类区分为训练易样本和训练难样本;s2:建立稀疏表示模型,需说明的是,稀疏表示模型是与自步约束正则化相关的模型,依次将判别后的训练易样本和训练难样本带入稀疏表示模型内进行训练,需要强调的是,在训练的过程中是先“易”后“难”的训练过程,即先将训练易样本带入稀疏表示模型内进行训练后,再将训练难样本带入稀疏表示模型内进行训练的过程;s3:获取图像分类模型和预测模型,经过s2可求取稀疏表示模型内的未知系数(即稀疏代码x、系数代码d和自步约束的加权系数α);s4:构建类别决策器,根据s3得到的预测模型构建类别决策器,本发明通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行不断训练,可构成具体自步约束的图像分类方案,便于利用更多的判别信息,且对样本噪声具有鲁棒性,从而可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
进一步的,划分训练样本难易种类采用自步约束矩阵划分,其自步约束矩阵v为:
其中,ai,j表示一个属于第i类的第j个训练样本,i=1,...,k,j=1,...,ni,k是类的总数,y表示测试样本,λ为参数,参数λ代表自步约束学习中提前确定好的阈值;需说明的是,当v(ii)=1时,表示训练易样本,当v(ii)=0时表示训练难样本,其将不参与稀疏表示的过程。
进一步的,稀疏表示模型为与自步约束正则化相关的模型,需说明的是稀疏表示模型定义为:
其中,学习词典中的类标签表示为d=[d1,d2,...,dk],其中di是与类i关联的子集,ai表示输入的样本数据,a=[a1,a2,...,ai],ai=[ai1,ai2,...,ain],xi是d中ai的子矩阵,
实施例2
参照图2,该实施例不同于第一个实施例的是:获取图像分类模型和预测模型的步骤包括:s41:训练训练易样本;s42:更新x;s43:获取稀疏代码x、系数代码d和自步约束的加权系数α;s44:确定图像分类模型和预测模型。具体的,参见图1,其主体结构包括s1:划分训练样本难易种类,操作人划分数据库图像,将其区分为训练样本和测试样本,在此对训练样本进行难易度划分,其中,训练样本难易种类区分为训练易样本和训练难样本;s2:建立稀疏表示模型,需说明的是,稀疏表示模型是与自步约束正则化相关的模型,依次将判别后的训练易样本和训练难样本带入稀疏表示模型内进行训练,需要强调的是,在训练的过程中是先“易”后“难”的训练过程,即先将训练易样本带入稀疏表示模型内进行训练后,再将训练难样本带入稀疏表示模型内进行训练的过程;s3:获取图像分类模型和预测模型,经过s2可求取稀疏表示模型内的未知系数(即稀疏代码x、系数代码d和自步约束的加权系数α);s4:构建类别决策器,根据s3得到的预测模型构建类别决策器,本发明通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行不断训练,可构成具体自步约束的图像分类方案,便于利用更多的判别信息,且对样本噪声具有鲁棒性,从而可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
进一步的,划分训练样本难易种类采用自步约束矩阵划分,其自步约束矩阵v为:
其中,ai,j表示一个属于第i类的第j个训练样本,i=1,...,k,j=1,...,ni,k是类的总数,y表示测试样本,λ为参数,参数λ代表自步约束学习中提前确定好的阈值;需说明的是,当v(ii)=1时,表示训练易样本,当v(ii)=0时表示训练难样本,其将不参与稀疏表示的过程。
进一步的,稀疏表示模型为与自步约束正则化相关的模型,需说明的是稀疏表示模型定义为:
其中,学习词典中的类标签表示为d=[d1,d2,...,dk],其中di是与类i关联的子集,ai表示输入的样本数据,a=[a1,a2,...,ai],ai=[ai1,ai2,...,ain],xi是d中ai的子矩阵,
s42:更新x;具体的,固定字典d和α,将公式(2)看作一个稀疏编码问题来解x=[x1,x2,......,xk],即稀疏表示模型公式(2)可进一步重写为:
即,
获取稀疏代码xi的算法,具体的,输入用i类训练子集ai,其中,d表示字典,参数ρ,τ>0,初始化:
当达到最大迭代次数时:
这里的
其soft(u,τ/ρ)定义为:soft(u,τ/ρ)=0,如果||uj|≤τ/ρ,将uj-sign(uj)τ/ρ赋予soft(u,τ/ρ),否则,结束循环,输出:
s43:获取稀疏代码x、系数代码d和自步约束的加权系数α,具体的,更新d=[d1,d2,......,dk],当x和α保持常量时,公式(2)为:
其中,
即公式(4)为:
其中,
获取系数代码di的算法:
输入:用i类训练子集ai;初始词典di;系数xi。
令zi=[z1;z2;...;zpi],di=[d1,d2,...,dpi],其中zj是行向量,dj是列向量。
forj=1topido
foralldl,l≠jandupdatedj.
lety=λi-∑l≠jdlzl
theminimizationofeq.(5)becomes:
thenwecangetthesolution
endfor
输出:更新所有的di,即更新了整个字典d。
其中,通过以下算法求学习自步约束学习的加权系数α:
初始化:di;测试样本y;λ,ε和μ>1
更新系数α:
while不收敛do
基于(2)式解wi,vi
最优化:
返回:计算实际输出:
更新系数:λ=μλ
达到最大迭代次数
输出:endwhile
其中,对于α的确定:一旦字典d和x固定,代入上述求解过程,便可以得到α的值。
s44:确定图像分类模型和预测模型,具体的,图像分类模型即是将获取稀疏代码x、系数代码d和自步约束的加权系数α带入公式(2)获取的公式,公式如下:
而确定预测模型ei采用如下公式:
其中,令
s4:构建类别决策器,具体的,类别决策器的构建与类别决策器ei有关,其类别决策器采用如下公式:
identity(y)=argmini{ei}。
实施例3
参照图4,该实施例不同于以上实施例的是:本实施例涉及植物图像分类识别技术领域,具体为基于自步约束机制的可监督植物图像分类方法。具体的,参见图1,其主体结构包括s1:划分训练样本难易种类,操作人划分数据库图像,将其区分为训练样本和测试样本,在此对训练样本进行难易度划分,其中,训练样本难易种类区分为训练易样本和训练难样本;s2:建立稀疏表示模型,需说明的是,稀疏表示模型是与自步约束正则化相关的模型,依次将判别后的训练易样本和训练难样本带入稀疏表示模型内进行训练,需要强调的是,在训练的过程中是先“易”后“难”的训练过程,即先将训练易样本带入稀疏表示模型内进行训练后,再将训练难样本带入稀疏表示模型内进行训练的过程;s3:获取图像分类模型和预测模型,经过s2可求取稀疏表示模型内的未知系数(即稀疏代码x、系数代码d和自步约束的加权系数α);s4:构建类别决策器,根据s3得到的预测模型构建类别决策器,本发明通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行不断训练,可构成具体自步约束的图像分类方案,便于利用更多的判别信息,且对样本噪声具有鲁棒性,从而可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
进一步的,划分训练样本难易种类采用自步约束矩阵划分,其自步约束矩阵v为:
其中,ai,j表示一个属于第i类的第j个训练样本,i=1,...,k,j=1,...,ni,k是类的总数,y表示测试样本,λ为参数,参数λ代表自步约束学习中提前确定好的阈值;需说明的是,当v(ii)=1时,表示训练易样本,当v(ii)=0时表示训练难样本,其将不参与稀疏表示的过程。
进一步的,稀疏表示模型为与自步约束正则化相关的模型,需说明的是稀疏表示模型定义为:
其中,学习词典中的类标签表示为d=[d1,d2,...,dk],其中di是与类i关联的子集,ai表示输入的样本数据,a=[a1,a2,...,ai],ai=[ai1,ai2,...,ain],xi是d中ai的子矩阵,
s42:更新x;具体的,固定字典d和α,将公式(2)看作一个稀疏编码问题来解x=[x1,x2,......,xk],即稀疏表示模型公式(2)可进一步重写为:
即,
获取稀疏代码xi的算法,具体的,输入用i类训练子集ai,其中,d表示字典,参数ρ,τ>0,初始化:
当达到最大迭代次数时:
这里的
其soft(u,τ/ρ)定义为:soft(u,τ/ρ)=0,如果||uj|≤τ/ρ,将uj-sign(uj)τ/ρ赋予soft(u,τ/ρ),否则,结束循环,输出:
s43:获取稀疏代码x、系数代码d和自步约束的加权系数α,具体的,更新d=[d1,d2,......,dk],当x和α保持常量时,公式(2)为:
其中,
即公式(4)为:
其中,
获取系数代码di的算法:
输入:用i类训练子集ai;初始词典di;系数xi。
令zi=[z1;z2;...;zpi],di=[d1,d2,...,dpi],其中zj是行向量,dj是列向量。
forj=1topido
foralldl,l≠jandupdatedj.
lety=λi-∑l≠jdlzl
theminimizationofeq.(5)becomes:
thenwecangetthesolution
endfor
输出:更新所有的di,即更新了整个字典d。
其中,通过以下算法求学习自步约束学习的加权系数α:
初始化:di;测试样本y;λ,ε和μ>1
更新系数α:
while不收敛do
基于(2)式解wi,vi
最优化:
返回:计算实际输出:
更新系数:λ=μλ
达到最大迭代次数
输出:endwhile
其中,对于α的确定:一旦字典d和x固定,代入上述求解过程,便可以得到α的值。
s44:确定图像分类模型和预测模型,具体的,图像分类模型即是将获取稀疏代码x、系数代码d和自步约束的加权系数α带入公式(2)获取的公式,公式如下:
而确定预测模型ei采用如下公式:
其中,令
s4:构建类别决策器,具体的,类别决策器的构建与类别决策器ei有关,其类别决策器采用如下公式:
identity(y)=argmini{ei}。
植物学家上山拍摄300张植物图片,需说明的是,该300张植物图片包括50种植物及其植物的不同角度图片,植物学家可以很明确知道该50种植物的名称,将随机选取拍摄200张植物图片作为训练样本,植物学家采集到的训练样本带入本发明方法和其它方法构建的模型中进行验证。
具体操作流程如下:
第一步,植物学家打开识图链接/app,需说明的是,其识图链接/app包括本方法和其它方法构建的链接/app,且链接/app在具体处理功能的电子器件上打开,其电子器件包括电脑、平板、手机等设备;
第二步,植物学家上传、粘贴网址、或直接将图片拖拽至链接/app界面;
第三步,链接/app界面接收图片,捕获输入图片的图像特征a,然后带入本方法获取的类别决策器公式内;
第四步,根据类别决策器检索到相同/相似图片,并显示于电子器件的界面上。
依次对本方法和其它方法(如稀疏分类(src)方法、支持向量机(svm)方法、标签一致ksvd(lcsvd)方法,费舍尔判别准则(fddl)方法和多模自步学习(mmspl)方法)进行验证,相应的结果如表1所示。
表格1:验证样本对比(准确率:%)
实施例4
参照图5~7,该实施例不同于以上实施例的是:本实施例为操作流程及其测试对比过程。具体的,参见图1,其主体结构包括s1:划分训练样本难易种类,操作人划分数据库图像,将其区分为训练样本和测试样本,在此对训练样本进行难易度划分,其中,训练样本难易种类区分为训练易样本和训练难样本;s2:建立稀疏表示模型,需说明的是,稀疏表示模型是与自步约束正则化相关的模型,依次将判别后的训练易样本和训练难样本带入稀疏表示模型内进行训练,需要强调的是,在训练的过程中是先“易”后“难”的训练过程,即先将训练易样本带入稀疏表示模型内进行训练后,再将训练难样本带入稀疏表示模型内进行训练的过程;s3:获取图像分类模型和预测模型,经过s2可求取稀疏表示模型内的未知系数(即稀疏代码x、系数代码d和自步约束的加权系数α);s4:构建类别决策器,根据s3得到的预测模型构建类别决策器,本发明通过自步约束矩阵对训练样本进行划分,将训练易样本和难样本依次带入定义的稀疏表示模型中进行不断训练,可构成具体自步约束的图像分类方案,便于利用更多的判别信息,且对样本噪声具有鲁棒性,从而可解决当面对包含噪声和巨大类内变化的复杂样本时监督字典学习机制将不再适用的问题,提高了图像识别效果。
进一步的,划分训练样本难易种类采用自步约束矩阵划分,其自步约束矩阵v为:
其中,ai,j表示一个属于第i类的第j个训练样本,i=1,...,k,j=1,...,ni,k是类的总数,y表示测试样本,λ为参数,参数λ代表自步约束学习中提前确定好的阈值;需说明的是,当v(ii)=1时,表示训练易样本,当v(ii)=0时表示训练难样本,其将不参与稀疏表示的过程。
进一步的,稀疏表示模型为与自步约束正则化相关的模型,需说明的是稀疏表示模型定义为:
其中,学习词典中的类标签表示为d=[d1,d2,...,dk],其中di是与类i关联的子集,ai表示输入的样本数据,a=[a1,a2,...,ai],ai=[ai1,ai2,...,ain],即a表示图像特征数据,用一个矩阵来表示,xi是d中ai的子矩阵,
s42:更新x;具体的,固定字典d和α,将公式(2)看作一个稀疏编码问题来解x=[x1,x2,......,xk],即稀疏表示模型公式(2)可进一步重写为:
即,
获取稀疏代码xi的算法,具体的,输入用i类训练子集ai,其中,d表示字典,参数ρ,τ>0,初始化:
当达到最大迭代次数时:
这里的
其soft(u,τ/ρ)定义为:soft(u,τ/ρ)=0,如果||uj|≤τ/ρ,将uj-sign(uj)τ/ρ赋予soft(u,τ/ρ),否则,结束循环,输出:
s43:获取稀疏代码x、系数代码d和自步约束的加权系数α,具体的,更新d=[d1,d2,......,dk],当x和α保持常量时,公式(2)为:
其中,
即公式(4)为:
其中,
获取系数代码di的算法:
输入:用i类训练子集ai;初始词典di;系数xi。
令zi=[z1;z2;...;zpi],di=[d1,d2,...,dpi],其中zj是行向量,dj是列向量。
forj=1topido
foralldl,l≠jandupdatedj.
lety=λi-∑l≠jdlzl
theminimizationofeq.(5)becomes:
thenwecangetthesolution
endfor
输出:更新所有的di,即更新了整个字典d。
其中,通过以下算法求学习自步约束学习的加权系数α:
初始化:di;测试样本y;λ,ε和μ>1
更新系数α:
while不收敛do
基于(2)式解wi,vi
最优化:
返回:计算实际输出:
更新系数:λ=μλ
达到最大迭代次数
输出:endwhile
其中,对于α的确定:一旦字典d和x固定,代入上述求解过程,便可以得到α的值。
s44:确定图像分类模型和预测模型,具体的,图像分类模型即是将获取稀疏代码x、系数代码d和自步约束的加权系数α带入公式(2)获取的公式,公式如下:
而确定预测模型ei采用如下公式:
其中,令
s4:构建类别决策器,具体的,类别决策器的构建与类别决策器ei有关,其类别决策器采用如下公式:
identity(y)=argmini{ei}。
参考图5~7,本实施例列举了在caltech-101和voc2012数据集上验证通过基于自步约束机制的可监督图像分类方法建立的模型测试对比实验,具体如下:在建立稀疏表示模型基础上,在字典的学习阶段设置了一些参数:λ1=0.005,λ2=0.01,ξ1=0.01,ξ2=0.02,ξ3=0.01,λ=1600,μ=1.1,最大迭代次数为15,而在分类阶段,一些参数设置如下:β1=0.05,β2=0.005,di中i设为训练样本的数量,需说明的是,λ1,λ2,ξ1,ξ2,ξ3,β1和β2的数值是根据训练经验得到,数值的大小与特征和字典的维度有关。
在caltech-101的实验过程如下,需说明的是,caltech-101数据集包含101个类别对象,每个类别由40到800张图像组成,图像样本由fei-feili采集的,图像的分辨率约为300×200像素,为了证明构建的基于自步约束学习的方案和监督下特定类稀疏模型分类器的优越性,与其他方法进行了比较,如:稀疏分类(src)方法、支持向量机(svm)方法、标签一致ksvd(lcsvd)方法,费舍尔判别准则(fddl)方法和多模自步学习(mmspl)方法,相应的结果如表2所示。
表格2:在caltech-101数据集上的算法对比(准确率:%)
通过以上实验可以看出,支持向量机(svm)方法的精度高于src,因为原始src只随机选择训练样本作为字典,并可能丢弃最优词典;lcksvd的性能优于fddl,表明在整个字典中表示查询示例比在应用程序中的每个特定类的子字典上表示查询示例更有效;fddl和lcksvd的性能比我方提出的方法差,意味自步约束正则化可以有效地提取样本中的局部信息;另外,mmspl的结果也归因于自定进度的学习,其结果与我方结果接近,但它忽略了稀疏约束项,且稀疏约束项对提高分类精度具有重要作用,即该数据集的结果表明,我方提出的模型通过纳入自步约束的学习方案是非常有效的。
在voc2012实验
在新的数据集(voc2012)上验证了我方提出的方法,并将其与其他先进的方法进行比较,包括多模自步学习(mmpsl)、多级自步方案、src、fddl和卷积网络模型,对比平均准确率如表3所示。
表格3:在voc2012数据集上的算法对比(平均准确率)
有由上表可知,在voc2012数据集的总体平均精度(map)约为83.3%,对于大多数类别,我方提出的方法所获得的分类精度都在80%以上,我方构建的模型在大多数类别中的性能优于其他具有类似自定进度学习的模型。
重要的是,应注意,在多个不同示例性实施方案中示出的本申请的构造和布置仅是例示性的。尽管在此公开内容中仅详细描述了几个实施方案,但参阅此公开内容的人员应容易理解,在实质上不偏离该申请中所描述的主题的新颖教导和优点的前提下,许多改型是可能的(例如,各种元件的尺寸、尺度、结构、形状和比例、以及参数值(例如,温度、压力等)、安装布置、材料的使用、颜色、定向的变化等)。例如,示出为整体成形的元件可以由多个部分或元件构成,元件的位置可被倒置或以其它方式改变,并且分立元件的性质或数目或位置可被更改或改变。因此,所有这样的改型旨在被包含在本发明的范围内。可以根据替代的实施方案改变或重新排序任何过程或方法步骤的次序或顺序。在权利要求中,任何“装置加功能”的条款都旨在覆盖在本文中所描述的执行所述功能的结构,且不仅是结构等同而且还是等同结构。在不背离本发明的范围的前提下,可以在示例性实施方案的设计、运行状况和布置中做出其他替换、改型、改变和省略。因此,本发明不限制于特定的实施方案,而是扩展至仍落在所附的权利要求书的范围内的多种改型。
此外,为了提供示例性实施方案的简练描述,可以不描述实际实施方案的所有特征(即,与当前考虑的执行本发明的最佳模式不相关的那些特征,或于实现本发明不相关的那些特征)。
应理解的是,在任何实际实施方式的开发过程中,如在任何工程或设计项目中,可做出大量的具体实施方式决定。这样的开发努力可能是复杂的且耗时的,但对于那些得益于此公开内容的普通技术人员来说,不需要过多实验,所述开发努力将是一个设计、制造和生产的常规工作。
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!