一种集成浅层语义预判模态的深度学习文本分类方法与流程
本发明涉及深度学习与文本分类领域,特别是涉及一种集成浅层语义预判模态的深度学习文本分类方法。
背景技术:
文本分类指对大量的非结构化文本语料按照给定的分类体系进行类别归属预测的过程。随着深度学习技术的突破,以卷积神经网络为代表的深度学习模型在文本分类上取得不错的效果。但总体而言,在准确性和可靠性上还远未能达到实用水平,这是由深度学习的先验知识缺失所造成的。因为大数据驱动的深度学习模型只会发现数据集中统计意义上的结论,难以有效利用先验知识。将先验知识融入到深度学习模型是一种解决深度学习瓶颈的思路。浅层语义是一种有效的常识知识提取和表达方式,因此研究集成浅层语义预判模态的深度学习文本分类方法具有重要的理论价值和研究意义。
技术实现要素:
本发明提供了一种集成浅层语义预判模态的深度学习文本分类方法sdg-cnn(semanticdecisionguideconvolutionalneuralnetwork),其克服传统深度学习模型在模型优化过程中缺乏背景知识和语义信息,信息模态单一的缺陷。
本发明解决其技术问题所采用的技术方案是:
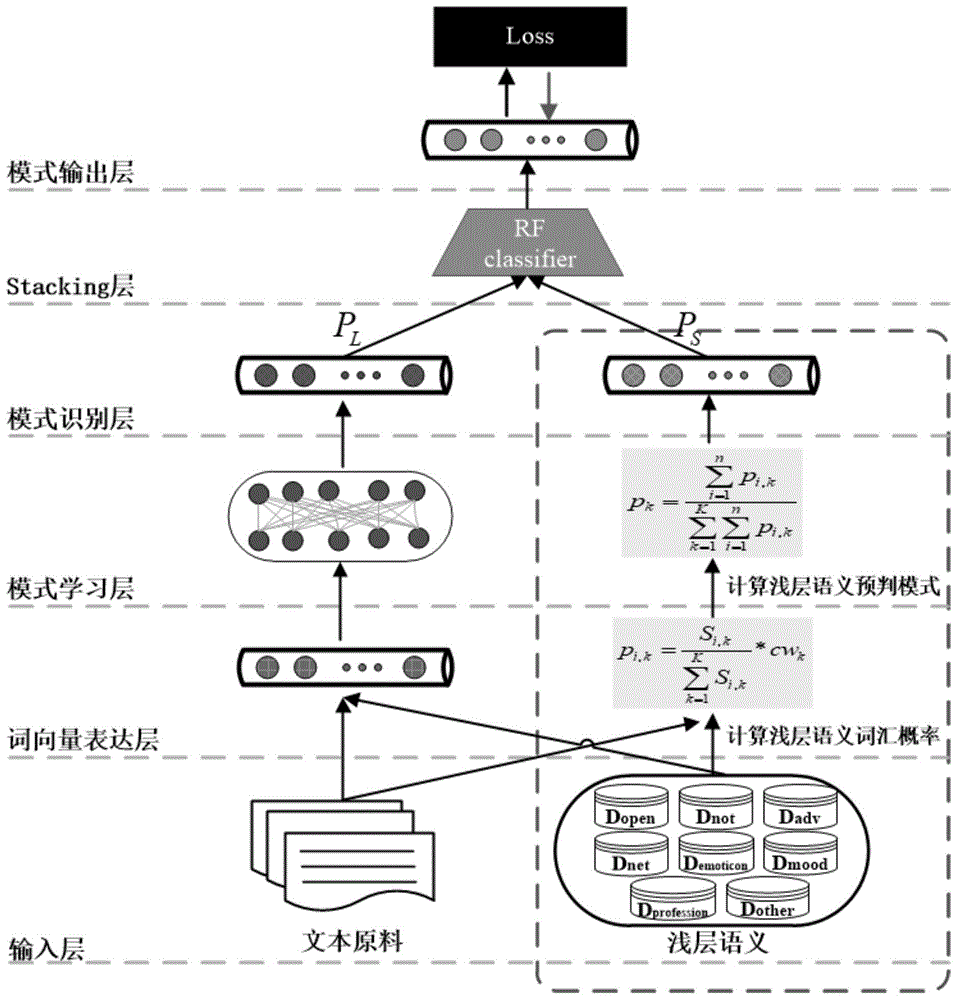
一种集成浅层语义预判模态的深度学习文本分类方法,包括以下步骤:
s1:输入文本语料,采用结巴分词工具对语料进行分词。
s2:计算浅层语义预判模式sdg,如下:
s21:从以下八个方面来挖掘行业词汇从而构建浅层语义词典:(1)开源词典dopen;(2)否定副词词典dnot;(3)程度副词词典dadv;(4)网络词典dnet;(5)符号词典demoticon;(6)语气词词典dmood;(7)领域词典dprofession;(8)其他包括手工构建的词典dother;
s22:利用训练语料计算出每个浅层语义词汇属于每个类别的概率,形成浅层语义词汇概率表;
s23:基于步骤s21中得到的浅层语义词典,提取每条语料中的浅层语义词汇;
s24:基于步骤s22得到的浅层语义词汇概率表和步骤s23得到的每条语料中的浅层语义词汇,利用求和归一化的方式计算出这条语料的预判概率,即形成浅层语义预判模式(sdg);
s3:集成浅层语义预判模态的cnn分类模型构建,如下:
s31:准备有监督文本学习样本集d=[文本语料x、文本类别y],其中每一个样本由一条文本语料x及其对应的标签y所形成;
s32:初始化cnn网络;
s33:选取学习样本集d的任一样本(x,),将其语料x送入cnn进行前向传播计算,得到其模式输出ρcnn;
s34:基于步骤s2提出的浅层语义预判模式计算方法,计算出语料x对应的浅层语义预判模式输出ρsdg;
s35:将ρcnn和ρsdg进行相加并归一化作为形成决策模式,进而输出针对语料x的预测结果y′;
s36:根据语料x的真实标签y和预测结果y′的差距来指导cnn模型的参数优化;
s37:基于步骤s36中已经训练好的cnn网络,将一条被测语料x送入cnn进行前向传播计算,得到其预测类别y′。
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
本发明提出的浅层语义预判模态能利用先验知识计算每条文本语料属于每个类别的概率分布情况,从而实现对深度学习模式训练的纠偏,进而达到将先验知识融入深度学习指导模型训练的目的,使模型构建更贴近人类的思考方式。
附图说明
图1为本发明的集成浅层语义预判模态的深度学习文本分类方法的示意图;
图2为本发明的集成浅层语义预判模态的深度学习文本分类方法示意图;
图3为mr数据集sdg-cnn模型precision指标对比效果图;
图4为mr数据集sdg-cnn模型accuracy指标对比效果图;
图5为mr数据集sdg-cnn模型f1-score指标对比效果图;
图6为sst-1数据集sdg-cnn模型precision指标对比效果图;
图7为sst-1数据集sdg-cnn模型accuracy指标对比效果图;
图8为sst-1数据集sdg-cnn模型f1-score指标对比效果图;
图9为sst-2数据集sdg-cnn模型precision指标对比效果图;
图10为sst-2数据集sdg-cnn模型accuracy指标对比效果图;
图11为sst-2数据集sdg-cnn模型f1-score指标对比效果图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
参见图1和图2所示,本发明的一种集成浅层语义预判模态的深度学习文本分类方法,包括以下步骤:(1)浅层语义预判模式计算;(2)集成浅层语义预判模态的cnn模型构建。
以情感分类为例,选择3个情感数据集进行实验,以期用语料的多样性验证本发明sdg-cnn的有效性。数据集的相关统计信息如表1所示。
表1三个数据集相关统计信息
其中,mr:电影评论数据,每一句代表一个电影评论,包括“积极”和“消极”2个类别;sst-1:斯坦福情绪树库,提供划分好的train/dev/test,包含verypositive,positive,neutral,negative,verynegative共5个类别;sst-2:与sst-1相同,但去掉了“neural”类别,并归并为二分类数据集,即包含positive和negative共2个类别。
本发明具体步骤如下:
步骤一:浅层语义预判模式计算
在文本语料构建阶段,本发明采用包含互联网50000条“积极”和“消极”二分类的imdb影评数据集和本文实验的3个情感数据集共82,130条语料作为文本训练语料。
在浅层语义词典生成阶段,经调研发现可以从8个不同的方面构建情感分析领域的词汇资源,即意味着情感分类的浅层语义词汇可以来源于8个不同的方面:
1)开源词典:国外的有sentiwordnet和inquirei,国内有知网hownet词典和同义词词林、大连理工大学和台湾大学等高校提供的情感词汇库;
2)否定副词词典:否定副词是用于否定后面词语的副词,常见否定词如“不”、“没有”、“没”、“无”、“非”等;
3)程度副词词典:如知网提供的程度副词分为6个等级,分别为极其、很、较、稍、欠、超;
4)网络词典:网络新词即多在网络上流行的非正式语言,多由谐音、错别字改成,也有象形字词,在情感分析领域应用越来越广泛。如“新手”不叫新手叫“菜鸟”,“这样子”不叫这样子叫“酱紫”。百度引擎和搜狐引擎集合了现在广为流行的网络用语,有较好的网络新词覆盖率;
5)符号词典:随着表情符号的流行,人们越来越趋向于用表情符号表达自己的观点,加入符号表情分析可大大提高情感分析效率;
6)语气词词典:语气词在中文表达中经常流露出情感倾向,如“哎呀”,“啊”,“哇塞”等。百度百科提供了76个语气词的词典,还可继续进行扩展;
7)领域词典:情感分类相关的词典,主要指的是情感类别体系,如知网的hownet情感词典分为正面情感词,正面评价词,负面情感词,负面评价词;
8)其他:对于前面七个方面未涉及的词典,可以通过自己构建的方式获得适合某个特定任务的词汇资源。
根据以上领域词汇的获取方法,本发明收集了二分类情感词典dopen(15907个单词或短语)和1-6个等级的程度副词词典dadv(共170个单词或短语),还包括手工整理的310个常用于否定后面词语的转折词dother。以这3种来源方式的词典为基础,构建大小为3900条的浅层语义词汇词典。
表2情感领域浅层语义词典
在浅层语义预判模式生成阶段,利用文本语料计算出浅层语义词典中每个浅层语义词汇属于每个类别的概率,形成浅层语义词汇概率表。针对一条目标语料,提取出该条语料中的浅层语义词汇,利用求和归一化的方式计算出这条语料的预判概率,即形成浅层语义预判模式(sdg)。
步骤二:集成浅层语义预判模态的cnn模型构建
首先将文本语料进行分词和词向量表达,其中词向量分别出训练50维和300维的词向量。词嵌入向量的生成方法是google开源的词向量训练工具,同时也采用google用十多亿个新闻单词用word2vec预训练的300维新闻语料词向量googlenews-vecctors-negative300.bin进行对比实验。这意味着词嵌入向量有50维和300维两种情况。其中,50维是本文自己训练的,而300维大部分采用google预训练的300维词向量,对于语料中出现过而google预训练300维新闻词向量中没有出现的词或短语,则采用自建语料库预训练的300维词向量代替。因word2vec模型参数对词向量表示效果和分类模型性能起着决定性作用,故需合理设置word2vec每个参数值表3所示。
表3word2vec模型参数
本发明采用卷积神经网络cnn为基础模型来构建情感分类研究模型,模型参数和架构如表3所示。在将文本语料输入cnn模型时,需要将其转化成一个矩阵样本,比如转化为一个90*50的矩阵数据,其表示该文本语料包含90个词语,每个词语的向量维度是50维。而由于原始数据中不同文本语料长度不同,如果选择最短的文本作为统一长度可能会将重要信息截取掉,选择最长的文本长度会使得其它短的文本添加过多无用消息(填充0)并且增加模型训练难度。其中关于文本长度的选择,本发明取每个数据集的平均长度,分别是20,18,19。并进一步对文本的填充方式和截取方式进行深入研究,以填充方式和截取方式的组合来展示算法有效性的验证。其中,pre指对文本进行头部截取或头部填充,post指对文本进行尾部截取或尾部填充;pre_post指对长文本进行头部截取,对短文本进行尾部填充。
表3cnn模型参数
对于词嵌入向量各个元素的值,本发明采用了固定权重和动态权重的两种方式,前者标记为static,指在训练过程中词向量的值不进行更新变化,即无权重方式,后者标记为dynamic,指词向量权重参与优化过程,在模型训练时会进行动态更新。
接下来初始化cnn网络,然后选取学习样本集d的任一样本(x,y),将其语料x送入cnn进行前向传播计算,得到其模式输出ρcnn,接着根据上一步骤提出的浅层语义预判模式计算方法,计算出语料x对应的浅层语义预判模式输出ρsdg,然后将将ρcnn和ρsdg进行相加并归一化作为形成决策模式,进而输出针对语料x的预测结果y′。接着根据语料x的真实标签y和预测结果y′的差距来指导cnn模型的参数优化。
下面采用precision、accuracy和f1-score3个指标来评价sdg-cnn文本分类模型的性能。图3至图11是sdg-cnn算法在mr数据集、sst-1数据集、sst-2数据集共3个数据集的对比实验结果图。
本发明以浅层语义词汇为基础,通过计算浅层语义词汇概率来构建浅层语义预判模式,最后通过与神经网络进行双模态融合学习的方式指导模型训练。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
- 还没有人留言评论。精彩留言会获得点赞!