基于即时定位建图与三维语义分割的语义建图系统的制作方法
本发明涉及计算机视觉技术领域,特别是涉及基于即时定位建图与三维语义分割的语义建图系统。
背景技术:
服务型机器人一般由三个模块构成:人机交互、环境感知、运动控制。机器人感知周围环境,需要一套稳定、性能强大的传感器系统来充当“眼睛”,同时需要相应的算法和强有力的处理单元读懂物体。其中视觉传感器是不可或缺的一部分,相较于激光雷达、毫米波雷达,摄像头的分辨率更高,能获取足够的环境细节,如描述物体的外观和形状、读取标识等。尽管全球定位系统(globalpositioningsystem,gps)有助于定位过程,但是由于高大树木、建筑、隧道等造成的干扰会使得gps定位不可靠。
即时定位与建图(simultaneouslocalizationandmapping,slam)是指载有特定传感器的主体在没有先验信息的情况下,通过运动估计自身的轨迹,并建立周围环境的地图。其广泛应用于机器人,无人机,自动驾驶,增强现实,虚拟现实等应用中。slam可以划分为激光slam和视觉slam两类。由于起步早,激光slam在理论技术和工程应用上都较为成熟。然而高昂的成本、庞大的体积以及缺少语义信息使其在一些特定的应用场景中受限。根据相机类型,可将视觉slam分为三种:单目、双目以及深度slam。类似于激光雷达,深度相机可以通过采集点云来直接计算到障碍物的距离。深度相机结构简单,易于安装操作,而且成本低、使用场景广泛。
大部分的slam方案都是特征点或像素级别,为了完成一个特定的任务,或者与周围环境进行有意义的互动,机器人需要获取语义信息。slam系统应该能够选择有用信息,剔除无效信息。随着深度学习的发展,许多成熟的目标检测和语义分割的方法为精确的语义建图提供了条件。语义地图有利于提高机器人的自主性和鲁棒性,完成更复杂的任务,从路径规划转化为任务规划。
三维图像中的目标感知技术越来越成熟,三维理解的需求也越来越紧迫。由于点云的不规则性,大多数研究者会将点转化为规则的体素或者图像集合,利用深度网络进行预测。这样的转换不可避免地会导致数据量增大,空间点之间的相互关系被削弱。2017年提出的pointnet是第一个可以直接处理原始三维点云的深度神经网络。
现有大部分语义建图系统采用的是稠密建图,对二维图像进行语义感知,并将二维信息映射到三维环境模型中。首先稠密建图会导致系统性能下降,连续帧间存在信息冗余,有效利用帧间信息可以提高系统效率。对二维图像进行语义感知,无法充分利用空间信息,对于小物体和遮挡等情况较敏感。将二维信息映射到三维模型中,并利用条件随机场等方法对结果做修正。相比于直接对三维点云进行语义感知,这样的做法一定程度上降低了效率、削弱了系统性能。
技术实现要素:
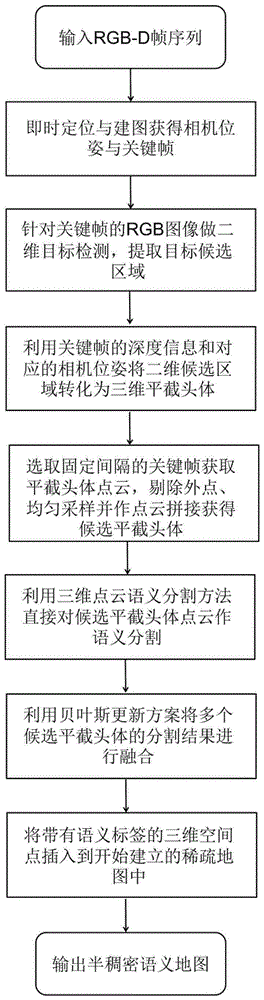
针对现有技术中存在的问题与不足,本发明提供基于即时定位建图与三维语义分割的语义建图系统,使用基于特征点的稀疏建图系统提取关键帧和相机位姿。针对关键帧,先利用成熟的二维目标检测方法提取感兴趣区域,再利用帧间信息即相机位姿,以及空间信息即图像深度,获取候选平截头体。利用点云语义分割方法对平截头体进行分割,设计一种贝叶斯更新方案将不同帧的分割结果进行融合。本发明旨在充分利用帧间信息和空间信息以提高系统性能,为达此目的,本发明提供基于即时定位建图与三维语义分割的语义建图系统,其计算处理步骤如下,利用稀疏建图技术与点云语义分割,建立包含感兴趣目标的半稠密语义地图,方法包括如下步骤:
(1)先对输入的图像帧序列进行即时定位与地图构建,获取关键帧与相机位姿。利用成熟的二维目标检测技术以及点云拼接,获得候选平截头体;
(2)再利用三维点云语义分割方法,对候选平截头体进行分割,利用贝叶斯更新方案,将多个候选平截头体的分割结果进行融合,将带有语义标签的空间点插入到稀疏地图中得到最终的半稠密语义地图。
作为本发明进一步改进,所述步骤(1)中先对输入视频帧序列进行即时定位与建图,再获取平截头体建议,具体步骤为:
步骤2.1:假设在时刻k,相机的位置为xk,相机输入数据为uk,xk=f(xk-1,uk,wk),wk为噪声,将其称为运动方程,在xk位置上观测到路标点yj,产生一系列观测数据zk,j,可以用观测方程来描述:zk,j=h(yj,xk,vk,j),其中vk,j为观测噪声,这两个方程描述了最基本的slam问题:已知运动测量的读数u,以及传感器读数z,估计定位问题x和建图问题y;
在提取匹配特征点后,可以直接使用pnp估计相机的运动,采用epnp计算初始位姿,核心思想是用4个控制点来表示空间点,然后构建重投影误差问题:
将估计的位姿作为初始值,采用相应方法可以求解,最后为解决累计漂移的问题,构造全局光束平差代价函数:
进行全局优化以解决累计漂移的问题;
步骤2.2:在获取到相机位姿和关键帧之后,利用二维目标检测方法ssd产生包围框、标签和置信度,本系统只考虑感兴趣目标,提取包围框内的rgb数据和深度信息。若包围框参数为(x,y,x1,y1),包围框内像素的横坐标范围为[floor(rows*x),ceil(rows*x1)],纵坐标范围为[floor(cols*y),ceil(cols*y1)],其中floor为向下取整函数,ceil为向上取整,(rows,cols)为图像的尺寸,对于第i个像素irefi=[rrefi,crefi]t,深度为drefi,相机坐标为:
步骤2.3:slam优化得到的位姿是旋转四元数的形式,一个四元数拥有一个实部和三个虚部:q=q0+q1i+q2j+q3k,其中i,j,k满足:
对应的旋转矩阵为:
变换矩阵
作为本发明进一步改进,所述步骤(2)中获取候选平截头体,并对候选平截头体进行语义分割,具体步骤为:
步骤3.1:挑选具有固定间隔的关键帧以产生平截头体建议,给定间隔σ和序列长度s,第k个平截头体来自于第
步骤3.2:直接对三维点云进行语义分割,基于点云语义分割网络,其对于输入遮挡和小物体具有较强的鲁棒性,首先对候选平截头体进行预处理,先进行随机采样至2048个点,转化为h5文件,再送入点云语义分割网络中,网络的的关键在于使用最大池化作为对称函数,对于点pwi=[xwi,ywi,zwi]t,i∈{1,...,n},目标分类网络输出l个候选类别上的l个置信度,语义分割网络对于n个点和m个语义种类上的n×m个置信度。
作为本发明进一步改进,所述步骤(2)中利用贝叶斯更新方案对不同分割结果进行融合,设计方法为:
对于参考候选平截头体prefw,
给定一个点prefwi和其对应的前向投影点集
本发明基于即时定位建图与三维语义分割的语义建图系统,有益效果如下;
本发明提供的基于即时定位建图与三维语义分割的语义建图方案可以高效准确地将输入视频帧序列转化为半稠密语义地图。本发明建立稀疏地图,并且只对关键帧进行处理,提高了语义建图系统的效率。充分利用空间信息和帧间信息,提高了系统性能,尤其对于遮挡和小物体等有较强的鲁棒性。本发明适用于很多场景,稀疏定位建图系统可以建立室内或室外场景的地图,基于深度学习的二维目标检测技术和三维点云语义分割方法只需要有效的训练便可以检测海量物体。
附图说明
图1为本发明基于slam和三维语义分割的语义建图系统流程图;
图2为本发明利用slam获得关键帧和相机位姿的流程图;
图3为本发明point-net的网络架构图;
图4为本发明利用orb-slam获取的稀疏地图,包含相机位姿以及关键帧;
图5为本发明关键的中间结果图,依次为:(1)二维目标检测产生目标候选区域和类别置信度;(2)提取平截头体中的点云;(3)挑选固定间隔的关键帧产生的平截头体点云,进行均匀采样并拼接;(4)最终产生的包含感兴趣目标的语义地图;
图6为本发明最终获取的半稠密语义地图示例。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述:
本发明提供基于即时定位建图与三维语义分割的语义建图系统,使用基于特征点的稀疏建图系统提取关键帧和相机位姿。针对关键帧,先利用成熟的二维目标检测方法提取感兴趣区域,再利用帧间信息即相机位姿,以及空间信息即图像深度,获取候选平截头体。利用点云语义分割方法对平截头体进行分割,设计一种贝叶斯更新方案将不同帧的分割结果进行融合。本发明旨在充分利用帧间信息和空间信息以提高系统性能。
下面基于ubuntu16.04和nvidiageforcegtx1080,借助于tensorfiowobjectdetectionapi、opencv、pointcloudlibrary等工具,在tum数据集rgbd_dataset_freiburg1_plant上为例,结合附图对本发明基于即时定位建图与三维语义分割的语义建图方案的具体实施方式作进一步详细说明。
步骤1:基于即时定位与建图获取稀疏地图、关键帧以及相机位姿,如图4所示。在特征点提取匹配阶段,fast检测过程为:
1.在图像中选取像素p,亮度为ip,设置阈值t;
2.以像素p为中心,选择半径为3的圆上的16个像素点;
3.如果圆上有连续的n个点的亮度大于ip+t或小于ip-t,那么像素p可被认为是特征点。
灰度质心法的步骤包括:
1.定义图像块b的矩为:mpq=∑x,y∈bxpyqi(x,y),p,q∈{0,1};
2.图像块的质心为:
3.连接图像块的几何中心o和质心c,得到方向向量
在局部ba中,重投影误差关于相机位姿李代数的一阶变化关系推导为:
重投影误差关于空间点的倒数推导为:
步骤2:基于关键帧和二维目标检测获得平截头体建议。首先利用ssd检测出目标的候选区域,得到包围框的参数(x,y,x1,y1),因此包围框内像素的横坐标范围为[floor(rows*x),ceil(rows*x1)],纵坐标范围为[floor(cols*y),ceil(cols*y1)],其中floor为向下取整函数,ceil为向上取整,(rows,cols)为图像的尺寸。假设上一步slam估计得到的该关键帧的位姿信息为(t1,t2,t3,q1,q2,q3,q0),构造旋转矩阵:
平移向量为t=[t1,t2,t3]t,因此转换矩阵为
根据关系pw=twcpc可以获得包围框内像素对应的空间点的世界坐标,利用pcl库构造平截头体内的点云,至此获得每个关键帧的平截头体建议。
步骤3:获取候选平截头体并进行语义分割。挑选具有固定间隔的关键帧产生的平截头体建议,给定间隔σ=15和序列长度s=195,第k个平截头体来自于第{15n+k,n∈{0,1,...12}}个关键帧,k∈{1,...,15},剔除深度大于0.7米的外点。先对每个候选平截头体进行均匀采样,然后进行点云拼接。对得到的拼接点云进行随机采样至2048个,将平截头体旋转到中心视角,使其中心轴与图像平面正交。在送入point-net之前,将点云的xyz坐标值减去中心点的值获得局部坐标。将二维检测器检测出的语义类别编码为一个独热类别向量,并将其拼接到中间点云特征中。
步骤4:基于贝叶斯方案将多帧结果进行融合。对于参考候选平截头体prefw中的点prefwi,
给定平截头体中的一个点prefwi和其对应的前向投影点集
其中
步骤5:将最终带有语义标签的点云插入到之前建立的稀疏地图中,以建立带有感兴趣目标的半稠密语义地图,如图6所示。在总的195帧关键帧中,针对植物这一类别,ssd在63帧中存在漏检情况。在获得点云分割结果之后,将带有语义标签的点反向投影到二维图像中,平均准确度为90.2%。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!