一种基于继承映射的跨模态迁移哈希检索方法与流程
本发明涉及跨模态检索方法,更具体地说,涉及一种基于继承映射的跨模态迁移哈希检索方法。
背景技术:
近年来,大数据背景下的跨模态检索技术越来越受到人们的关注,其检索效率和精度不论是在学术界还是工业界都存在极大的挑战。而哈希技术旨在将高维的原始数据特征映射成低维的二进制码,这不仅能很好地降低计算机的运算和存储开销,也大大提升检索效率。但是,想要用低维的二进制码实现高性能的检索结果仍然是一个非常大的挑战。因此,本发明主要针对图像-文本两种不同模态数据之间的检索提出了一种高效的跨模态哈希检索方法。
由于不同模态数据存在于不同维度的特征空间,因此跨模态检索方法的核心思想就是如何桥接不同模态之间的间隔。近年来,也有许多基于哈希技术的扩模态检索方法被提出,根据有无使用有标记数据大致可分为两类,一类是无监督学习方法,另一类是有监督的学习方法。无监督哈希通常不使用语义标记。例如,cmfh(collectivematrixfactorizationhashing)方法首先通过协同矩阵分解的方法对所有模态数据学习统一的哈希码矩阵,然后将学到的哈希码矩阵用于学习特别模态的哈希方程;lssh(latentsemanticsparsehashing)方法运用稀疏编码和矩阵分解的方式来探索图片的显性结构及文本的隐性概念,因此可以在子空间内保持原始特征的相关性。但是,由于高层语义信息的缺失,无监督的方法往往达不到较好的检索效果。
而有监督哈希通常通过探索高层语义信息以求达到更好的检索效果。例如,scm(semanticcorrelationmaximization)方法将语义标记无缝地整合到哈希码学习的过程中;dch(discriminantcross-modalhashing)方法将学习到的哈希码当作一种表征,然后和类标记共同学习一个线性的分类器;fdch(fastdiscretecross-modalhashing)方法提出使用回归的方法将标记回归到相应的哈希码,同时还引入漂移项来调节回归过程从而提高所学哈希码的质量。本发明也主要关注有监督的学习方法,因为有监督的学习有效地利用了标记信息来加强语意保持从而达到更好的检索效果。大多数有监督的学习方法通常包含两种保持原始特征分布的思想。一种是通过构建局部图模型来保持模态内的近邻关系,但是这种方法通常忽略了不同模态之间的相关性;另一种思想是通过语义标记构建亲属矩阵来保持异构数据之间的相关性,但是它丢弃了原始特征固有的分布特性。因此都无法达到令人满意的检索效果。
技术实现要素:
为克服上述现有技术的不足,本发明提供了一种基于继承映射的跨模态迁移哈希检索方法。所述方法提出使用线性跨模态迁移实现异构数据之间信息的相互嵌入,同时起到从原始特征分布的层面关联异构数据的作用。除此之外,该方法强调跨模态迁移的系数矩阵和原始空间到哈希空间的映射矩阵保持一致。这种方式可以使学习到的哈希码直接有效的继承原始特征的分布特性及异构相关性,从而促进检索效果。
本发明采用的技术方案如下:
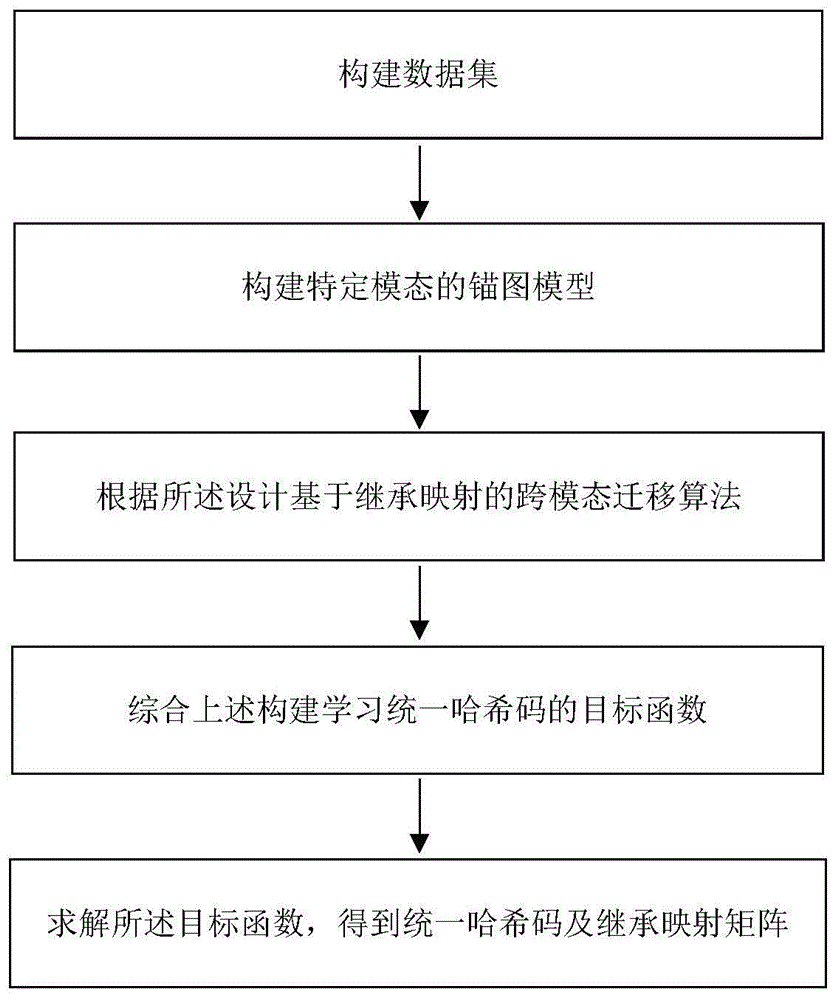
一种基于继承映射的跨模态迁移哈希检索方法,其特征在于,包括以下步骤:
步骤1:给定数据集
步骤2:构建锚图模型来保持数据模态内的结构近邻关系,具体方法为:将任一模态训练样本当作图模型中的节点,构建节点与锚点之间的权重关系为:
其中,m为模态索引,即m=(1,2)分别对应图像和文本,σ是带宽参数,rmj表示锚点且j∈(1,c),根据锚图计算理论,其拉普拉斯矩阵为
其中
步骤3:基于继承映射的跨模态迁移学习,即:
其中,
同时,为了继承原始特征的潜在信息,该对映射矩阵同样用于原始特征空间到哈希空间的映射,即:
b∈{-1,1}k×n表示统一的哈希码矩阵;
步骤4:结合所述步骤2和步骤3构建学习统一哈希码的目标函数;
步骤5:求解所述目标函数,得到统一哈希码及继承映射矩阵。
更具体地,计算虚拟类中心作为步骤2中的锚点,rmj=[rmj(1),rmj(2),...,rmj(dm)]且
其中,xm(j)表示第m模态中第j类的所有样本,kj表示第j类样本的个数,d表示样本特征的第d个维度。
更具体地,步骤4中所述的目标函数为:
s.t.b∈{-1,1}k×n
其中,第五项是正则化项,λm和γ表示超参且都大于0。
更具体地,所述目标函数求解方法为:
1)首先将目标函数等价改写为:
s.t.b∈{-1,1}k×n
2)更新q,u1,u2:通固定其他三个变量,对其余一个变量求偏导并
令其等于0可得:
q=(yyt+γi)-1ybt
3)更新b:固定其它变量,目标函数可化简为:
且上式可重写为:
s.t.b∈{-1,1}k×n
既然||b||2是个常数,因此上式可被化简为:
其中
因此统一的哈希码矩阵为:
对于新的样本可以同过学习到的继承映射矩阵直接将原始特征编码成哈希码,编码方法定义为:
本发明具有以下有益效果:
1、跨模态迁移学习能够有效地嵌入异构信息来保持不同模态数据之间的相关关系。同时,本发明也通过继承映射思想将跨模态迁移学习与离散映射无缝结合,能够有效地地继承原始特征的分布及相关关系。
2、本发明结合了跨模态迁移学习、语义回归、离散映射及基于锚图的结构约束。这不仅有效地继承了原始特征的相关性、语义分布特性及固有结构特征;也使得整个算法是线性复杂度,从而确保了在大规模数据检索中的高效性。
附图说明
图1为本发明一种基于继承映射的跨模态迁移哈希检索方法的流程框图。
具体实施方式
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
下面以示例的方式具体说明本发明的方法,该方法包括以下步骤:
第一阶段:数据集处理
本发明在mirflickr-25k和nus-wide两个数据集上进行实验评测。
mirflickr-25k数据集包含25,000个样例,每一个样例包含一个图片-文本对,并且总共给定24个标签,每一个样例至少包含标签。在实验室中,我们选择了至少有20个标签标注20,015个样例进行实验。其中,文本模态被表示为1386维的bow向量;而对于图像模态,我们使用在imagenet数据集上预训练的vgg模型对每个图片样本提取4096维的cnn特征。实验中,我们随机取2,000样例作为查询,其余作为被检索的数据库。为了减少计算成本,我们从数据库中取5,000个样例用于训练。
nus-wide数据集包含269,648个样例。实验中,本发明选取样例最多的10个类进行实验,共包含186,577个图像-文本对。对于每一个样例,文本模态被表示成1,000维的bow向量;同样地,我们对图像模态模型对每个图片样本提取4096维的cnn特征。在此数据集上,我们随机采样2,000各样例作为查询,其余的作为数据库。同样地,随机从数据库中取5,000个数据点用于训练。
第二阶段:模型学习
步骤1:给定数据集
步骤2:构建锚图模型来保持数据模态内的结构近邻关系。具体方法为:将所述任一模态训练样本当作图模型中的节点,然后构建节点与锚点之间的权重关系,可公式化为:
其中,m为模态索引,即m=(1,2)分别对应图像和文本,σ是带宽参数。rmj是一个dm维的向量,表示锚点且j∈(1,c)。
进一步地,对于锚点的选择,本发明提出虚拟类中心的方法,这能有效地避免传统的聚类算法造成的计算冗余。详细地,可将虚拟类中心表示为rmj=[rmj(1),rmj(2),...,rmj(dm)]且:
其中,xm(j)表示第m模态中第j类的所有样本,kj表示第j类样本的个数,d表示样本特征的第d个维度。根据锚图计算理论,其拉普拉斯矩阵
其中
步骤3:基于继承映射的跨模态迁移学习。首先,为了使异构信息能够相互嵌入且加强异构模态间的相关性,本发明定义了一种线性跨模态迁移学习方法,即:
其中,
其次,本阶段的目标是为每一个样例学习紧凑的二进制码bi∈{-1,1}k,b∈{-1,1}k×n表示统一的哈希码矩阵。为了继承原始特征的潜在信息,该对映射矩阵同样用于原始特征空间到哈希空间的映射,即:
除此之外,对于高层语义信息的探索,本发明采用了一种高效稳定的线性回归方法,即:
其中q∈rc×k为语义空间到哈希空间的映射矩阵。
步骤4:综合步骤2和步骤3所述构建学习统一哈希码的目标函数:
s.t.b∈{-1,1}k×n
其中,第五项是正则化项,λm和γ表示超参(且都大于0)。
步骤5:求解步骤4所述目标函数。综上所述,目标函数可被改写为:
s.t.b∈{-1,1}k×n
1)更新q,u1,u2:通固定其他三个变量,对其余一个变量求偏导并令其等于0可得:
q=(yyt+γi)-1ybt
1)更新b:固定其它变量,目标函数可化简为:
且上式可重写为:
s.t.b∈{-1,1}k×n
既然||b||2是个常数,因此上式可被化简为:
其中
因此统一的哈希码矩阵为:
最终,通过迭代求解方法得到最优的哈希码矩阵b,及继承映射矩阵u1,u2。进一步地,对于新的样本可以同过学习到的继承映射矩阵直接将原始特征编码成哈希码。具体地可将其编码方法定义为:
算法实现过程如下:
输入:图像特征矩阵x1,文本特征矩阵x2及标记矩阵y;超参数:λ1,λ2,γ
初始化:1.根据上述步骤2构建锚图模型
2.随机初始化继承映射矩阵u1、u2及语义映射矩阵q
循环执行下列语句
1.根据上述步骤5.1)更新继承映射矩阵u1、u2及语义映射矩阵q;
2.根据上述步骤5.2)更新哈希码矩阵b;
直至收敛
输出:继承映射矩阵u1、u2及哈希码矩阵b
在两个数据集上进行实验,并对比了当前比较流行的其他6种方法(cmfh,lssh,scm,dch,fdch)。从表1和表2可以看出:本实施例提供的方法在不同数据集上都表现出优于其他方法的检索性能。
表1
表2
上述虽然结合附图对本申请的具体实施方式进行了描述,但并非对本申请保护范围的限制,所属领域技术人员应该明白,在本申请的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本申请的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!