一种基于并发任务的项目查重方法及系统与流程
本发明涉及项目立项过程中判断申报材料是否重复或与其他项目相似的计算方法技术领域,具体为一种基于并发任务的项目查重方法及系统。
背景技术:
在项目、成果和奖励申报的过程中通常需要填写大量的文字申报材料,这些材料会存在重复上报、抄袭他人成果等问题,造成人力、物力的浪费。以往的检验文字重复工作都是采用人工阅读的方式进行,由于日积月累的项目信息越来越多,对审核的工作要求越来越高,相关人员需要大量的阅读项目信息,并且拥有超强的记忆能力才能掌握这项工作技能,而且比对工作量大、效率低,使得人工检验工作越来越困难,很难在审核过程中排除重复上报、抄袭他人成果等问题。目前网上虽然有相关的检测系统,然而得到的查重结果都是五花八门,良莠不齐,不仅查重效率慢,收费还很高,有时候即使花钱也得不到有效的结果。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提供了一种基于并发任务的项目查重方法及系统,具有减少硬盘频繁读写访问、充分利用系统资源等优点,解决了检验工作越来越困难,很难在审核过程中排除重复上报、抄袭他人成果等问题。
(二)技术方案
为实现上述目的,本发明提供如下技术方案:一种基于并发任务的项目查重方法及系统,包括以下步骤:
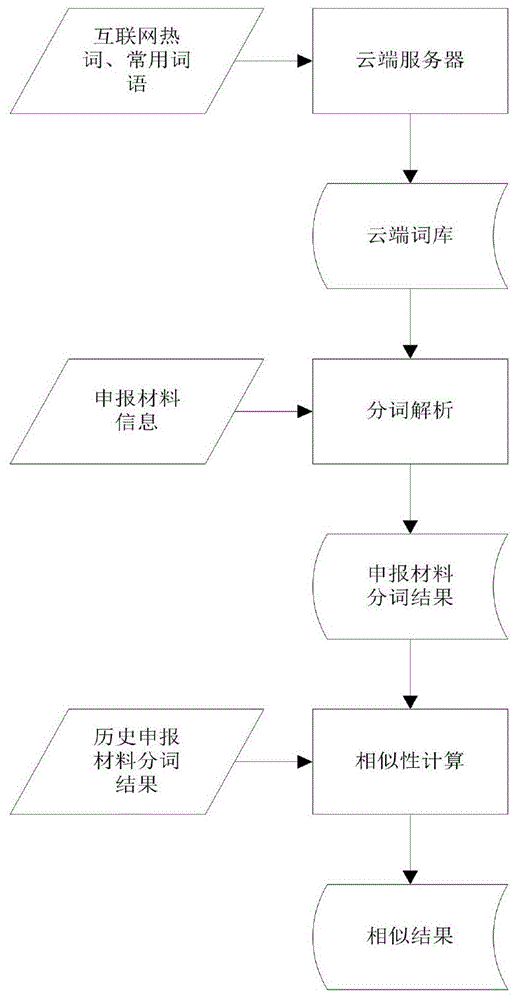
步骤一、通过分布式方式处理,借用量子物理中的“电子云”(electroncloud)技术,利用电子云的既然性、弥漫性、同时性等特性,收集互联网上的常用词语和热度,传输至云端服务器进行动态解析,将解析的词语按照热度排列保存为云端词库。
步骤二、开启并发多线程任务,通过处理器的详细信息,cpu的使用率,内存使用率并结合并发参数(default=2),计算可开启的并发线程数量num_threads,保留核心线程以保证系统的正常运行,对于后续步骤中出现大批量数据计算时系统都将自动采用并发多线程任务,充分利用系统资源,发挥cpu最大频率,以提高查重效率。
步骤三、将当前查重的申报材料拆分为段落集合,其中cur_sen是申报材料的段落集合;sen_1,sen_2,…,sen_n是拆分的段落。通过正向匹配法并结合云端词库,将每个段落解析为具有语义分词的集合,其中cur_sen_i_f是正向匹配法的段落分词集合;word_1,word_2,…,word_n是将段落拆分的分词;i=1,2,…,n是段落的索引index。通过词库中的热度计算匹配加权得分,其中cur_fscore为正向匹配法段落的加权总分数;sum{hot(word_i)^2}是通过hot函数计算分词的加权分数,然后通过sum函数计算合计数;i=1,2,…,n是分词的索引index。对于词库中不存在的词语则设置匹配加权得分为0。通过逆向匹配法并结合云端词库,将每个段落解析为具有语义分词的集合,其中cur_sen_i_r是逆向匹配法的段落分词集合;word_1,word_2,…,word_n是将段落拆分的分词;i=1,2,…,n是段落的索引index。通过词库中的热度计算匹配加权得分,其中cur_rscore为逆向匹配法段落的加权总分数;sum{hot(word_i)^2}是通过hot函数计算分词的加权分数,然后通过sum函数计算合计数;i=1,2,…,n是分词的索引index。对于词库中不存在的词语则设置匹配加权得分为0。最后取分词得分最大或分值相同时取前者的分词方案。max_score=max{cur_fscore,cur_rscore},循环计算直到所有段落计算完毕,将分词集合保存到数据库中为今后重复利用。同理,历史项目中的申报材料如果分词结果为空时,也采用步骤三的方法对申报材料进行解析,计算最佳分词方案并存储到数据库中。
步骤四、通过统计分词算法将当前查重项目分词因子和历史项目的分词因子标记索引求出集合,统计词频并排除高频率的“单字词”(如“的”、“地”、“了”等)。其中cur_word_index是待查重项目的分词词频集合;
w_id_1,w_id_2,…,w_in_n是分词因子索引;num_1,num_2,…,num_n是分词的词频。其中his_word_index是历史项目的分词词频集合;w_id_1,w_id_2,…,w_in_n是分词因子索引;num_1,num_2,…,num_n是分词的词频。通过哈希表的map接口计算当前查重项目的词频向量c0=[num_1,num_2,…,num_n]和历史项目的词频向量c1=[num_1,num_2,…,num_n],将词频向量结果构建并集,其中index为每个分词因子的索引号;通过余弦相似性算法cosinesimilar返回当前查重项目和历史项目的相似值,相似值越接近于1则相似度越高。
优选的,步骤一中“电子云”(electroncloud)与云端服务器通过以太网连接。
优选的,步骤二中cpu的核心数大于等于二。
优选的,步骤三其max_score是最大分值;max{cur_fscore,cur_rscore}是通过max返回最大值。
优选的,步骤四中c0为当前查重项目的词频向量;c1为历史项目的词频向量。
(三)有益效果
与现有技术相比,本发明提供了一种基于并发任务的项目查重方法及系统,具备以下有益效果:
1、该种基于并发任务的项目查重方法及系统,依托互联网技术将互联网热词、常用词语进行动态解析,形成云端词库。通过文字匹配法对申报材料中的文字信息与云端词库进行匹配,将申报材料切分为具有语义的分词因子,通过加权计算取得最佳分词方案,统计词频并排除高频率的“单字词”。将当前查重项目的分词子集和历史项目的分词子集通过余弦相似性算法cosinesimilar返回当前查重项目和历史项目的相似值。在大数据计算时,利用大容量高速内存,合理使用内存管理,减少硬盘频繁读写访问,开启并发多线程任务,充分利用系统资源,发挥cpu最大频率,以提高查重效率。
2、该种基于并发任务的项目查重方法及系统,充分利用了系统资源实现了高效率的查重功能,除此之外,通过云端技术收集的热词和常用词语为文字匹配法提供了有力支撑,提高了申报材料的分词准确性,同时其扩展性强,支持选取多篇文章同时查重。
附图说明
图1为本发明流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:步骤一、通过分布式方式处理,借用量子物理中的“电子云”(electroncloud)技术,利用电子云的既然性、弥漫性、同时性等特性,收集互联网上的常用词语和热度,传输至云端服务器进行动态解析,将解析的词语按照热度排列保存为云端词库。
步骤二、开启并发多线程任务,通过处理器的详细信息,cpu的使用率,内存使用率并结合并发参数(default=2),计算可开启的并发线程数量num_threads,保留核心线程以保证系统的正常运行,对于后续步骤中出现大批量数据计算时系统都将自动采用并发多线程任务,充分利用系统资源,发挥cpu最大频率,以提高查重效率。
步骤三、将当前查重的申报材料拆分为段落集合,其中cur_sen是申报材料的段落集合;sen_1,sen_2,…,sen_n是拆分的段落。通过正向匹配法并结合云端词库,将每个段落解析为具有语义分词的集合,其中cur_sen_i_f是正向匹配法的段落分词集合;word_1,word_2,…,word_n是将段落拆分的分词;i=1,2,…,n是段落的索引index。通过词库中的热度计算匹配加权得分,其中cur_fscore为正向匹配法段落的加权总分数;sum{hot(word_i)^2}是通过hot函数计算分词的加权分数,然后通过sum函数计算合计数;i=1,2,…,n是分词的索引index。对于词库中不存在的词语则设置匹配加权得分为0。通过逆向匹配法并结合云端词库,将每个段落解析为具有语义分词的集合,其中cur_sen_i_r是逆向匹配法的段落分词集合;word_1,word_2,…,word_n是将段落拆分的分词;i=1,2,…,n是段落的索引index。通过词库中的热度计算匹配加权得分,其中cur_rscore为逆向匹配法段落的加权总分数;sum{hot(word_i)^2}是通过hot函数计算分词的加权分数,然后通过sum函数计算合计数;i=1,2,…,n是分词的索引index。对于词库中不存在的词语则设置匹配加权得分为0。最后取分词得分最大或分值相同时取前者的分词方案。max_score=max{cur_fscore,cur_rscore},循环计算直到所有段落计算完毕,将分词集合保存到数据库中为今后重复利用。同理,历史项目中的申报材料如果分词结果为空时,也采用步骤三的方法对申报材料进行解析,计算最佳分词方案并存储到数据库中。
步骤四、通过统计分词算法将当前查重项目分词因子和历史项目的分词因子标记索引求出集合,统计词频并排除高频率的“单字词”(如“的”、“地”、“了”等)。其中cur_word_index是待查重项目的分词词频集合;
w_id_1,w_id_2,…,w_in_n是分词因子索引;num_1,num_2,…,num_n是分词的词频。其中his_word_index是历史项目的分词词频集合;w_id_1,w_id_2,…,w_in_n是分词因子索引;num_1,num_2,…,num_n是分词的词频。通过哈希表的map接口计算当前查重项目的词频向量c0=[num_1,num_2,…,num_n]和历史项目的词频向量c1=[num_1,num_2,…,num_n],将词频向量结果构建并集,其中index为每个分词因子的索引号;通过余弦相似性算法cosinesimilar返回当前查重项目和历史项目的相似值,相似值越接近于1则相似度越高。
进一步改进地,步骤一中“电子云”(electroncloud)与云端服务器通过以太网连接。
进一步改进地,步骤二中cpu的核心数大于等于二。
进一步改进地,步骤三其max_score是最大分值;max{cur_fscore,cur_rscore}是通过max返回最大值。
进一步改进地,步骤四中c0为当前查重项目的词频向量;c1为历史项目的词频向量。
该文中出现的电器元件均与外界的主控器及220v市电电连接,并且主控器可为计算机等起到控制的常规已知设备。
综上所述,该种基于并发任务的项目查重方法及系统,依托互联网技术将互联网热词、常用词语进行动态解析,形成云端词库。通过文字匹配法对申报材料中的文字信息与云端词库进行匹配,将申报材料切分为具有语义的分词因子,通过加权计算取得最佳分词方案,统计词频并排除高频率的“单字词”。将当前查重项目的分词子集和历史项目的分词子集通过余弦相似性算法cosinesimilar返回当前查重项目和历史项目的相似值。在大数据计算时,利用大容量高速内存,合理使用内存管理,减少硬盘频繁读写访问,开启并发多线程任务,充分利用系统资源,发挥cpu最大频率,以提高查重效率。充分利用了系统资源实现了高效率的查重功能,除此之外,通过云端技术收集的热词和常用词语为文字匹配法提供了有力支撑,提高了申报材料的分词准确性,同时其扩展性强,支持选取多篇文章同时查重。。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!