一种从三维点云中提取二次曲面的方法与流程
本发明涉及计算机视觉技术研究领域,更特别地,涉及一种从三维点云中提取二次曲面的方法。
背景技术:
随着计算机技术的发展和三维数据获取技术的不断进步,通过计算机视觉来处理三维几何数据成为现代制造业和工业的重要的技术之一。在基于三维数据的计算机视觉技术中,点云是其主流的表达形式,它有获取方便、数据结构简单、表达灵活的特点,适用于大小型规模的三维模型或三维场景的描述。
在制造业和工业生产领域,其产品大多为基于cad软件设计的人造物体,含有大量的标准平面或二次曲面,尤以圆柱面、圆锥面、球面和平面居多,它们往往是后续处理(如质量监测、姿态识别、逆向工程等)的重要研究对象。而实际上,这些处理过程一般都在生产流水线上完成,对实时性有很高的要求,因此研究如何从三维点云数据中快速准确地提取二次曲面将具有重大的意义。
近来,二次曲面的提取方法被相继提出,其中较为主流的包括最小二乘拟合、ransac(randomsampleconsensus,随机采样一致性)、霍夫变换、遗传算法、张量投票法和区域生长法(rabbanit,vandenheuvelf,vosselmanng.segmentationofpointcloudsusingsmoothnessconstraint[j].internationalarchivesofphotogrammetry,remotesensingandspatialinformationsciences,2006,36(5):248-253.)等。最小二乘拟合法是最为典型和成熟的数据拟合方法,其计算较为简单,易于实现,但对噪声非常敏感,对初值的要求较高,而且容易出现不收敛的情况,特别是拟合圆柱面和圆锥面时需要采用非线性方法,大大提高计算复杂度。基于ransac的二次曲面提取技术是近年来研究的热点,它在较多噪声的情况下依然能非常精准地提取出曲面,但由于其算法需要多次迭代,导致效率往往较为低下,难以满足实时性要求,而且容易出现过拟合的现象。霍夫变换是识别几何形状的基本方法之一,它基于参数空间投票的方法,有抗噪声能力强、结果为全局最优的特点,但对于多维的参数空间,其时间复杂度则呈指数型增长,因此一般只用于平面的分割。而遗传算法和张量投票法虽然有一定的抗噪声能力,但其算法都较为复杂,其中遗传算法的变异算子和交叉算子难以选择,张量投票法不能提取指定曲面类型,因此实用度均不高。区域生长法最初主要应用于二维图像处理,它首先从数据中选取一个种子点,然后通过判定种子点与邻域点的关系来确定是否把邻域点纳入增长集合,只要初始种子点选取恰当,制定有效的生长法则,它能快速准确地完成指定区域分割。该原理被推广到点云数据中,进行二次曲面的提取。但目前基于区域生长的方法在生长点选取和生长法则制定方面都没有很好的解决办法,因此区域生长在三维点云数据的应用多在于平面的提取或平滑区域的分割上,或采用最小二乘与区域生长结合的方法进行二次曲面提取,但这样的效率会大大降低。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种从三维点云中提取二次曲面的方法,该方法基于区域生长原理,具有效率高,且提取结果准确的优点。
本发明的目的通过以下的技术方案实现:一种从三维点云中提取二次曲面的方法,包括步骤:
(1)从三维点云数据提取每个点的k领域点集,并计算每个点的法线,利用每个点的k邻域点集拟合每个点对应的二次曲面并计算其对应的二次曲面参数标准差;
(2)按二次曲面参数标准差从小到大的顺序排列点集;
(3)从排序后的点集中依序取出每个点,当取出点对应的二次曲面参数标准小于设置的阈值且未被标记为已生长点时,视为初始种子点;
(4)从初始种子点开始进行区域生长,并以当前区域的序号对属于该二次曲面的生长点进行标记,同时对该二次曲面参数进行动态拟合,直到一个二次曲面生长完毕;重复步骤(3)、(4),直到二次曲面参数标准差大于阈值,执行步骤(5);
(5)按点云中的标记序号提取对应二次曲面。
优选的,步骤(1)中,在获取三维点云数据后先进行降噪、降采样、截断等预处理,以提高曲面提取的效果和速度。
优选的,步骤(1)中,采用最小二乘平面拟合的方法估计每个点的法线。
优选的,步骤(1)中,所述k邻域点集指在欧氏距离上离该点最近的k个点集,采用kd-tree的数据结构进行每个点的k近邻查询,并保存每个点的k邻域点集在点云中的索引。
优选的,步骤(1)中,根据所提取的二次曲面类型,计算每个点的k邻域点集的标准差,包括:
(a)圆柱面:①以当前点为参考点pr,取k邻域点集中在欧氏距离上离参考点pr最远的5个点p1,p2,…,p5为计算点,其对应法线分别为nr和n1,n2,…,n5,ni代表了空间中的一条直线,;②分别计算nr与n1,n2,…,n5的公垂线,记为l1,l2,…,l5,定义平均公垂线为:
(b)圆锥面:①以当前点为参考点pr,取k邻域点集中在欧氏距离上离参考点pr最远的3个点p1,p2,p3为计算点,其对应法线分别为nr和n1,n2,n3;②计算顶点坐标:papex=[(p1·n1)(n2×n3)+(p1·n1)(n2×n3)+(p1·n1)(n2×n3)]/[n1·(n2×n3)],计算前先把ni单位化;③令p′1,p′2,p′3分别为射线
(c)球面:①以当前点为参考点pr,取k邻域点集中在欧氏距离上离参考点pr最远的5个点p1,p2,…,p5为计算点,其对应法线分别为nr和n1,n2,…,n5;②分别计算nr与n1,n2,…,n5的交点,记为c1,c2,…,c5,定义平均交点为:
(d)平面:①分别计算当前点法线nr与k邻域点集中所有点的法线n1,n2,…,nk的夹角,记为θ1,θ2,…,θk,定义平面的k邻域点集的标准差为:
更进一步的,在步骤(1)计算每个点的标准差的同时,对于圆柱面,储存每个点所对应的平均公垂线;对于圆锥面,储存每个点所对应的轴线,包括顶点和轴向量;对于球面,储存每个点所对应的平均交点。因其用于后面的曲面参数动态拟合。
优选的,所述步骤(4)中,从一个初始种子点进行区域生长并动态拟合曲面参数的具体步骤包括:
(4-1)用初始种子点so初始化种子点队列qs,并用so计算初始曲面参数;
(4-2)从qs中取出队头,记为当前种子点sc,并取出sc的k邻域点集{pi,i≤k};
(4-3)对于每一个k邻域点pi,判断pi是否满足生长法则,若满足,则利用pi拟合特定曲面参数,并用当前的区域的序号rj对pi进行标记,表示该点属于区域j,即假设当前正在进行第j个区域的生长;
(4-4)在pi满足生长法则的前提下,判断pi的标准差σi是否小于所设定的种子点标准差阈值τσ,若是,则判定pi满足种子点要求,把pi加入种子点队列qs的队尾,并利用pi拟合曲面参数;重复步骤(4-3)、(4-4),直到k个邻域点{pi,i≤k}全部处理完毕;
(4-5)判断qs是否已空,是则结束算法,并储存拟合的曲面参数;否则回到步骤(4-2)。
更进一步的,步骤(4-1)中,采用队列数据结构储存种子点集,因其具有先进后出的特点。
更进一步的,步骤(4)中,对于不同曲面类型,初始曲面参数计算方法、是否满足生长法则的判断依据以及曲面参数的拟合方法均不同,具体步骤包括:
(a)圆柱面:a)计算初始曲面参数:采用初始种子点so对应的平均公垂线作为该圆柱面的初始轴线lo,so到lo的距离作为初始半径ro;b)生长法则判定及动态拟合曲面参数:计算当前点p离当前拟合轴线lc的距离d,设当前拟合半径为rc,若|rc-d|≤τe,则判定该点为生长点(区域内点),并利用该点重新拟合(修正)半径,定义修正后的半径为:rc+1=(ncrc+d)/(nc+1),其中nc为当前区域内点的个数,若点p同时还满足种子点要求,则利用该点重新拟合(修正)轴线,定义修正后的轴线为:lc+1=(nslc+l)/(ns+1),其中ns为当前种子点的个数,l为点p对应的平均公垂线;若|rc-d|>τe,则判定点p为区域外点,不作任何处理;
(b)圆锥面:a)计算初始曲面参数:采用初始种子点so对应的轴线作为该圆锥面的初始轴线lo(lo={顶点po(x0,y0,z0),轴向量vo(v1,v2,v3)}),计算so的法线no与lo的夹角αo,则初始张角为:θo=π-2αo;b)生长法则判定及动态拟合曲面参数:计算当前点p法线nc与当前拟合轴线lc的夹角αc,其对应张角则为θ=π-2αc,设当前拟合张角为θc,若|θc-θ|≤τe,则判定该点为生长点(区域内点),并利用该点重新拟合(修正)张角,定义修正后的张角为:θc+1=(ncθc+θ)/(nc+1),若点p同时还满足种子点要求,则利用该点重新拟合(修正)轴线,定义修正后的轴线为:lc+1=(nslc+l)/(ns+1),其中l为点p对应的轴线;若|θc-θ|>τe,则判定点p为区域外点,不作任何处理;
(c)球面:a)计算初始曲面参数:采用初始种子点so对应的平均交点作为该球面的初始球心co,so到co的距离作为初始半径ro;b)生长法则判定及动态拟合曲面参数:计算当前点p离当前拟合球心cc的距离d,设当前拟合半径为rc,若|rc-d|≤τe,则判定该点为生长点(区域内点),并利用该点重新拟合(修正)半径,定义修正后的半径为:rc+1=(ncrc+d)/(nc+1),若点p同时还满足种子点要求,则利用该点重新拟合(修正)球心,定义修正后的球心为:cc+1=(nscc+c)/(ns+1),其中c为点p对应的平均交点;若|rc-d|>τe,则判定点p为区域外点,不作任何处理;
(d)平面:a)计算初始曲面参数:采用初始种子点so的法线作为该平面的法线no;b)生长法则判定及动态拟合曲面参数:计算当前点p法线nc与no的夹角θ,若θ≤τe,则判定该点为生长点(区域内点);若θ>τe,则判定点p为区域外点,不做任何处理。应该注意到,平面参数不需要动态修正,so的法线即为该平面的法线。
优选的,所述步骤(5)中,通过步骤(4)的区域生长,点云数据中属于曲面区域的点已经被标记好对应的区域序号,轮询每个点,把属于同一区域序号的点提取出来,即得到各个曲面点云数据,而且其序号跟保存的曲面参数一一对应。
更进一步的,通过设置曲面(区域)聚类点数范围,来限定所提取的曲面的点云个数,对于点云数太少的(可能是欠分割的对象)或者点云数太多的(可能是过分割的对象)进行选择性剔除,从而提高提取效果。
优选的,初始种子点和新种子点的选取依据是其标准差的大小,优先选取标准差小的点作为种子点。
与现有技术相比,本发明的有益效果是:本发明利用了区域生长算法高效的特点,同时克服了其初始种子点和生长法则的选取问题,从而提供了一种快速准确的二次曲面提取方法,并且在提取过程中对曲面参数进行了动态拟合和优化。另外,由于算法的巧妙设计,令其可以运用多线程技术或gpu技术进行明显的速度优化。该方法能应用于制造业和工业生产领域,在生产流水线上对产品进行实时的处理和分析。
附图说明
图1是本实施例从三维点云中提取二次曲面的方法的流程图。
图2是本实施例方法中通过区域生长完成一次曲面提取的算法流程图。
图3(a)是一个包含圆柱面、圆锥面、球面和平面的点云模型示意图。
图3(b)是对图3(a)所示点云进行降采样后的结果图。
图4是图3(b)所示点云模型的法线示意图。
图5是图3(b)所示k邻域点集示意图。
图6是生长点标记的示意图。
图7是通过本方法从点云模型中提取的圆柱面的示意图。
图8是通过本方法从点云模型中提取的圆锥面的示意图。
图9是通过本方法从点云模型中提取的球面的示意图。
图10是通过本方法从点云模型中提取的平面的示意图。
具体实施方式
为了更好地理解和实施,下面结合附图与实施例对本发明作进一步说明,本发明的实施方式包括但不限于下列实施例。
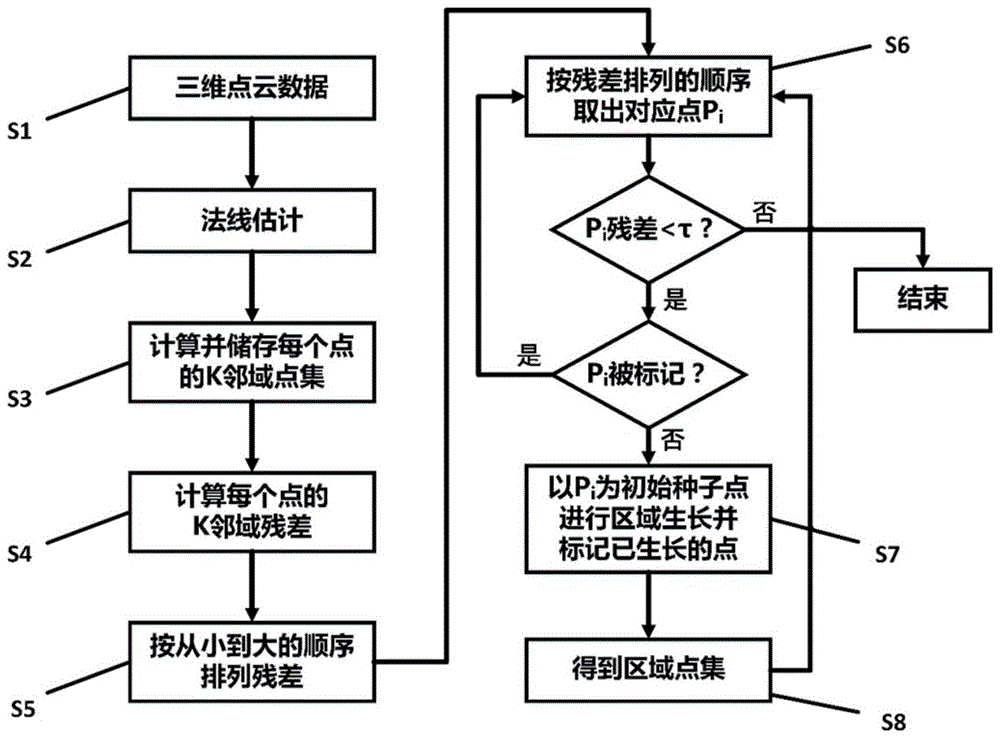
请参阅图1,其为本发明从三维点云中提取二次曲面的方法的流程图,主要包括8个步骤:
s1:获取三维点云数据;
s2:估计每个点的法线;
s3:计算并储存每个点的k邻域点集;
s4:利用每个点的k邻域点集拟合每个点对应的二次曲面并计算其对应的二次曲面参数标准差;
s5:按二次曲面参数标准差从小到大的顺序排列点集;
s6:从排序后的点集中依序取出每个点,当取出点对应的二次曲面参数标准小于设置的阈值且未被标记为已生长点时,视为初始种子点;
s7:从初始种子点开始进行区域生长,并以当前区域的序号对属于该二次曲面(区域)的生长点进行标记,同时对该二次曲面参数进行动态拟合,直到一个二次曲面生长完毕;重复s6、s7,直到二次曲面参数标准差大于阈值,执行s8;
s8:按点云中的标记序号提取对应曲面。
在算法开始阶段,需要设置的主要参数包括:(a)提取的曲面类型、(b)曲面参数范围、(c)种子点标准差阈值τσ,以及(d)生长误差阈值τe,可选地,可设置的参数还包括:(e)k邻域搜索范围(默认为30个点)、(f)曲面(区域)聚类点数范围、(g)种子点极差de(默认为标准差阈值的10倍)。一般地,曲面类型包括:(a)圆柱面、(b)圆锥面、(c)球面以及(d)平面,其相关特征参数及所需要设置范围的参数请参考表1。
表1不同曲面对应的参数
为了更好地阐述本发明的优点,本实施例采用一个同时具有圆柱面、圆锥面、球面和平面的模型作为实施例模型,如图3(a)所示,对方法中的各个步骤详述如下。
s1:获取三维点云数据。其点云原始数据(100000个点)的示意图如图3(a)所示。为了提高曲面提取的速度和效果,优选地对原始点云数据进行预处理,一般可选的预处理包括:降噪、降采样、截断等,本例只作降采样处理,对原始点云数据进行降采样后(13710个点)的结果如图3(b)所示。
s2:估计点云模型中每个点的法线。法线估计的方法有很多,具体实施方法不属于本发明的范畴,不展开讨论,优选地采用最小二乘平面拟合的方法估计法线,因其有速度快、稳定性高的特点。本实施例中对点云模型的法线估计的结果如图4所示。
s3:计算并储存每个点的k邻域点集。用于描述离散点云拓扑关系的数据结构有很多,主流的包括:oc-tree、kd-tree、r-tree、cell-tree等,优选地采用kd-tree的数据结构描述点云的邻域关系,因其对于区间和近邻搜索十分高效准确。通过kd-tree结构,可很容易计算到每个点在欧氏距离上离其最近的k个点。k值的选取与曲面点云面积有关,太小容易出现欠分割,太大容易出现过分割,一般与法线估计的支持半径相适应,本实施例中选取k=30,图5示意了一个点的100个邻域点。保存每个点所对应的邻域点集,将其用于后续的计算。
以下给出把所有不同类型的曲面依次提取出来并拟合出对应曲面参数的详细步骤。
(a)圆柱面的提取:
s4:计算每个点的k邻域点集的标准差。对点云数据中的每个点作以下处理:①记该点为pr,取pr的k邻域点集中在欧氏距离上离pr最远的5个点p1,p2,…,p5为计算点,其对应法线分别为nr和n1,n2,…,n5,应该注意ni表示空间中的一条直线(由点pi和其法线方向向量组成,下同);②分别计算nr与n1,n2,…,n5的公垂线,即同时垂直于nr和ni并过nr和ni的直线(用点向式表示),记为l1,l2,…,l5,定义平均公垂线为:
s5:按从小到大的顺序排列标准差,并对齐对应点。优选地,用一个容器储存排列后的标准差和对应点,越靠前的点表示其标准差越小;
s6:从上述容器中按顺序取出点pi,当点pi的标准差σi≤τσ(τσ为种子点标准差阈值)时,判断pi是否已经被标记为已生长的区域点,若是,则取出下一个点pi+1并重复本步骤,否则跳到步骤s7;直到检测到σi>τσ时,跳到步骤s8;
s7:由步骤s6可知pi满足种子点条件且为未生长点,则以pi作为初始种子点so,进行区域生长,其步骤包括:
s7-1:用初始种子点so初始化种子点队列qs,优选地采用队列的数据结构储存种子点集,因其具有先进后出的特点;
s7-2:采用so对应的平均公垂线作为该圆柱面的初始轴线lo,计算so到lo的距离作为初始半径ro,得到初始曲面参数;
s7-3、s7-4:从qs中取出队头,记为当前种子点sc(第一次即为so),并取出sc的k邻域点集{pki,i≤30};
s7-5:对于每一个邻域点pki,计算pki离当前拟合轴线lc的距离d,设当前拟合半径为rc,若|rc-d|≤τe,则判定该点为生长点(区域内点),并利用该点重新拟合(修正)半径,定义修正后的半径为:rc+1=(ncrc+d)/(nc+1),其中nc为当前区域内点(不算点pki,下同)的个数,并用当前的区域的序号rj对pki进行标记,表示该点属于区域j(假设当前正在进行第j个区域的生长),图6示意了生长点的标记过程。本实施例中的模型只有一个圆柱面,理论上属于圆柱面的点将会被标记为“1”;若|rc-d|>τe,则判定点pki为区域外点,不作任何处理;
s7-6:在pki满足生长法则的前提下,判断pki的标准差σki是否小于所设定的种子点标准差阈值τσ,若是,则判定pki满足种子点要求,把pki加入种子点队列qs的队尾,并利用该点重新拟合(修正)轴线,定义修正后的轴线为:lc+1=(nslc+l)/(ns+1),其中ns为当前种子点的个数(下同),l为点pki对应的平均公垂线;重复步骤s7-5、s7-6,直到k个邻域点{pki,i≤30}全部处理完毕;
s7-7:判断qs是否已空,是则结束算法,表示一个圆柱面生长完毕,并储存拟合的曲面参数lc和rc;否则回到s7-3;
当一个圆柱面生长完毕,跳回步骤s6,重复该过程,直到满足跳到步骤s8的条件,本实施例中的模型只有一个圆柱面,因此该过程理论上只执行了一次。
s8:按点云中的标记序号提取对应圆柱面。通过前面区域生长步骤,点云数据中属于圆柱面的点已经被标记为对应的区域序号(本实施例中为“1”),轮询每个点,把序号为“1”的点提取出来,即得到圆柱面点云数据,而且其序号跟保存的曲面参数对应。优选地,可以通过设置曲面(区域)聚类点数范围,来限定所提取的曲面的点云个数,估计本实施例的模型中圆柱面的点云数,设置点数范围为1000到5000,从而剔除了可能错误的分割点云。图7示意了本实施例模型通过本方法分割出来的圆柱面点云以及其轴线和半径的拟合结果。
(b)圆锥面的提取:
s4:计算每个点的k邻域点集的标准差。对点云数据中的每个点作以下处理:①以当前点为参考点pr,取k邻域点集中在欧氏距离上离参考点pr最远的3个点p1,p2,p3为计算点,其对应法线分别为nr和n1,n2,n3;②计算顶点坐标:papex=[(p1·n1)(n2×n3)+(p1·n1)(n2×n3)+(p1·n1)(n2×n3)]/[n1·(n2×n3)],应该注意计算前先把ni单位化;③令p′1,p′2,p′3分别为射线
s5:按从小到大的顺序排列标准差,并对齐对应点。优选地,用一个容器储存排列后的标准差和对应点,越靠前的点表示其标准差越小;
s6:从上述容器中按顺序取出点pi,当点pi的标准差σi≤τσ(τσ为种子点标准差阈值)时,判断pi是否已经被标记为已生长的区域点,若是,则取出下一个点pi+1并重复本步骤,否则跳到步骤s7;直到检测到σi>τσ时,跳到步骤s8;
s7:由步骤s6可知pi满足种子点条件且为未生长点,则以pi作为初始种子点so,进行区域生长,其步骤包括:
s7-1:用初始种子点so初始化种子点队列qs,优选地采用队列的数据结构储存种子点集,因其具有先进后出的特点;
s7-2:采用so对应的轴线作为该圆锥面的初始轴线lo(lo={顶点po(x0,y0,z0),轴向量vo(v1,v2,v3)}),计算so的法线no与lo的夹角αo,则初始张角为:θo=π-2αo,得到初始曲面参数;
s7-3、s7-4:从qs中取出队头,记为当前种子点sc(第一次即为so),并取出sc的k邻域点集{pki,i≤30};
s7-5:对于每一个邻域点pki,计算pki法线nc与当前拟合轴线lc的夹角αc,其对应张角则为θ=π-2αc,设当前拟合张角为θc,若|θc-θ|≤τe,则判定该点为生长点(区域内点),并利用该点重新拟合(修正)张角,定义修正后的张角为:θc+1=(ncθc+θ)/(nc+1),并用当前的区域的序号rj对pki进行标记,表示该点属于区域j,本实施例中的模型只有一个圆锥面,理论上属于圆锥面的点将会被标记为“1”;若|θc-θ|>τe,则判定点pki为区域外点,不作任何处理:
s7-6:在pki满足生长法则的前提下,判断pki的标准差σki是否小于所设定的种子点标准差阈值τσ,若是,则判定pki满足种子点要求,把pki加入种子点队列qs的队尾,并利用该点重新拟合(修正)轴线,定义修正后的轴线为:lc+1=(nslc+l)/(ns+1),l为点pki对应的轴线;重复步骤s7-5、s7-6,直到k个邻域点{pki,i≤30}全部处理完毕;
s7-7:判断qs是否已空,是则结束算法,表示一个圆锥面生长完毕,并储存拟合的曲面参数lc和θc;否则回到步骤s7-3;
当一个圆锥面生长完毕,跳回步骤s6,重复该过程,直到满足跳到步骤s8的条件,本实施例中的模型只有一个圆锥面,因此该过程理论上只执行了一次;
s8:按点云中的标记序号提取对应圆锥面。通过前面区域生长步骤,点云数据中属于圆锥面的点已经被标记为对应的区域序号(本实施例中为“1”),轮询每个点,把序号为“1”的点提取出来,即得到圆锥面点云数据,而且其序号跟保存的曲面参数对应。优选地,可以通过设置曲面(区域)聚类点数范围,来限定所提取的曲面的点云个数,估计本实施例的模型中圆柱面的点云数,设置点数范围为1000到5000,从而剔除了可能错误的分割点云。图7示意了本实施例模型通过本方法分割出来的圆锥面点云以及其轴线和张角的拟合结果。
(c)球面的提取:
s4:计算每个点的k邻域点集的标准差。对点云数据中的每个点作以下处理:①以当前点为参考点pr,取k邻域点集中在欧氏距离上离参考点pr最远的5个点p1,p2,…,p5为计算点,其对应法线分别为nr和n1,n2,…,n5;②分别计算nr与n1,n2,…,n5的交点,即离nr和ni距离最近的点,记为c1,c2,…,c5,定义平均交点为:
s5:按从小到大的顺序排列标准差,并对齐对应点。优选地,用一个容器储存排列后的标准差和对应点,越靠前的点表示其标准差越小;
s6:从上述容器中按顺序取出点pi,当点pi的标准差σi≤τσ(τσ为种子点标准差阈值)时,判断pi是否已经被标记为已生长的区域点,若是,则取出下一个点pi+1并重复本步骤,否则跳到步骤s7;直到检测到σi>τσ时,跳到步骤s8;
s7:由步骤s6可知pi满足种子点条件且为未生长点,则以pi作为初始种子点so,进行区域生长,其步骤包括:
s7-1:用初始种子点so初始化种子点队列qs,优选地采用队列的数据结构储存种子点集,因其具有先进后出的特点;
s7-2:采用so对应的平均交点作为该球面的初始球心co,so到co的距离作为初始半径ro,得到初始曲面参数;
s7-3、s7-4:从qs中取出队头,记为当前种子点sc(第一次即为so),并取出sc的k邻域点集{pki,i≤30};
s7-5:对于每一个邻域点pki,计算pki离当前拟合球心cc的距离d,设当前拟合半径为rc,若|rc-d|≤τe,则判定该点为生长点(区域内点),并利用该点重新拟合(修正)半径,定义修正后的半径为:rc+1=(ncrc+d)/(nc+1),并用当前的区域的序号rj对pki进行标记,表示该点属于区域j(假设当前正在进行第j个区域的生长),本实施例中的模型只有一个球面,理论上属于球面的点将会被标记为“1”;若|rc-d|>τe,则判定点pki为区域外点,不作任何处理;
s7-6:在pki满足生长法则的前提下,判断pki的标准差σki是否小于所设定的种子点标准差阈值τσ,若是,则判定pki满足种子点要求,把pki加入种子点队列qs的队尾,并利用该点重新拟合(修正)球心,定义修正后的球心为:cc+1=(nscc+c)/(ns+1),其中c为点p对应的平均交点;重复步骤s7-5、s7-6,直到k个邻域点{pki,i≤30}全部处理完毕;
s7-7:判断qs是否已空,是则结束算法,表示一个球面生长完毕,并储存拟合的曲面参数cc和rc;否则回到步骤s7-3;
当一个球面生长完毕,跳回步骤s6,重复该过程,直到满足跳到步骤s8的条件,本实施例中的模型只有一个球面,因此该过程理论上只执行了一次;
s8:按点云中的标记序号提取对应球面。通过前面区域生长步骤,点云数据中属于球面的点已经被标记为对应的区域序号(本实施例中为“1”),轮询每个点,把序号为“1”的点提取出来,即得到球面点云数据,而且其序号跟保存的曲面参数对应。优选地,可以通过设置曲面(区域)聚类点数范围,来限定所提取的曲面的点云个数,估计本实施例的模型中球面的点云数,设置点数范围为1000到5000,从而剔除了可能错误的分割点云。图7示意了本实施例模型通过本方法分割出来的球面点云以及其球心和半径的拟合结果。
(d)平面的提取:
s4:计算每个点的k邻域点集的标准差。对点云数据中的每个点作以下处理:分别计算当前点法线nr与k邻域点集中所有点的法线n1,n2,…,n30的夹角,记为θ1,θ2,…,θ30,定义平面的k邻域点集的标准差为:
s5:按从小到大的顺序排列标准差,并对齐对应点。优选地,用一个容器储存排列后的标准差和对应点,越靠前的点表示其标准差越小;
s6:从上述容器中按顺序取出点pi,当点pi的标准差σi≤τσ(τσ为种子点标准差阈值)时,判断pi是否已经被标记为已生长的区域点,若是,则取出下一个点pi+1并重复本步骤,否则跳到步骤s7;直到检测到σi>τσ时,跳到步骤s8;
s7:由步骤s6可知pi满足种子点条件且为未生长点,则以pi作为初始种子点so,进行区域生长,其步骤包括:
s7-1:用初始种子点so初始化种子点队列qs,优选地采用队列的数据结构储存种子点集,因其具有先进后出的特点;
a)计算初始曲面参数:采用so的法线作为该平面的法线no;b)生长法则判定及动态拟合曲面参数:计算当前点p法线nc与no的夹角θ,若θ≤τe,则判定该点为生长点(区域内点);若θ>τe,则判定点p为区域外点,不做任何处理;应该注意到,平面参数不需要动态修正,so的法线即为该平面的法线;
s7-2:采用so的法线作为该平面的法线no;
s7-3、s7-4:从qs中取出队头,记为当前种子点sc(第一次即为so),并取出sc的k邻域点集{pki,i≤30};
s7-5:对于每一个邻域点pki,计算pki法线nc与no的夹角θ,若θ≤τe,则判定该点为生长点(区域内点),应该注意到,平面参数不需要动态修正,so的法线即为该平面的法线,同时,用当前的区域的序号rj对pki进行标记,表示该点属于区域j(假设当前正在进行第j个区域的生长),本实施例中的模型只有一个平面,理论上属于平面的点将会被标记为“1”;若θ>τe,则判定点pki为区域外点,不作任何处理;
s7-6:在pki满足生长法则的前提下,判断pki的标准差σki是否小于所设定的种子点标准差阈值τσ,若是,则判定pki满足种子点要求,把pki加入种子点队列qs的队尾;重复步骤s7-5、s7-6,直到k个邻域点{pki,i≤30}全部处理完毕;
s7-7:判断qs是否已空,是则结束算法,表示一个平面生长完毕,并储存拟合的曲面参数no;否则回到步骤s7-3;
当一个平面生长完毕,跳回步骤s6,重复该过程,直到满足跳到步骤s8的条件,本实施例中的模型只有一个平面,因此该过程理论上只执行了一次;
s8:按点云中的标记序号提取对应平面。通过前面区域生长步骤,点云数据中属于平面的点已经被标记为对应的区域序号(本实施例中为“1”),轮询每个点,把序号为“1”的点提取出来,即得到平面点云数据,而且其序号跟保存的曲面参数对应。优选地,可以通过设置曲面(区域)聚类点数范围,来限定所提取的曲面的点云个数,估计本实施例的模型中平面的点云数,设置点数范围为500到3000,从而剔除了可能错误的分割点云。图10示意了本实施例模型通过本方法分割出来的平面点云以及其法线的拟合结果。
应该注意到,本方法中大部分运算集中在k邻域点集的计算以及其标准差的计算中,且每个点的运算相互独立,因而该过程可以并行化处理,即利用多线程技术或者gpu技术可以同时对多个点的k邻域点集和标准差进行并行计算,从而令效率提高数倍到数十倍以上。
本领域技术人员可通过各种手段实施本发明描述的技术。举例来说,这些技术可实施在硬件、固件、软件或其组合中。对于硬件实施方案,处理模块可实施在一个或一个以上专用集成电路(asic)、数字信号处理器(dsp)、可编程逻辑装置(pld)、现场可编辑逻辑门阵列(fpga)、处理器、控制器、微控制器、电子装置、其他经设计以执行本发明所描述的功能的电子单元或其组合内。
对于固件和/或软件实施方案,可用执行本文描述的功能的模块(例如,过程、步骤、流程等)来实施所述技术。固件和/或软件代码可存储在存储器中并由处理器执行。存储器可实施在处理器内或处理器外部。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储在一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
本发明并不局限于上述实施方式,如果对本发明的各种改动或变形不脱离本发明的精神和范围,倘若这些改动和变形属于本发明的权利要求和等同技术范围之内,则本发明也意图包含这些改动和变形。
- 还没有人留言评论。精彩留言会获得点赞!