一种数据分布式自增编码方法、系统、设备及介质与流程
本发明涉及大数据技术领域,具体涉及一种数据分布式自增编码方法、系统、设备及介质。
背景技术:
随着计算机存储能力的提升和复杂算法的发展,近年来网络数据量成指数级增长,科学数据处理、商业智能数据分析等具有海量数据需求的应用变得越来越普遍,主流的大数据处理技术通过hive和分布式进行数据处理,数据自增编码是其中重要的一个环节。现有技术中,数据自增编码通过编写udf函数等方式实现,需要依赖java开发,开发成本较大,效率较低,随着大数据处理需求的与日俱增,传统数据自增编码的弊端逐渐突出,所以急需一种有助于降低开发难度,提高开发效率的数据自增编码技术。
技术实现要素:
针对上述问题,本发明提供一种数据分布式自编码方法、系统、设备及介质,无需编写udf函数,通过sql实现hive中的数据自增,从而达到给某个已知名称字段编码的目的。
本发明具体为:
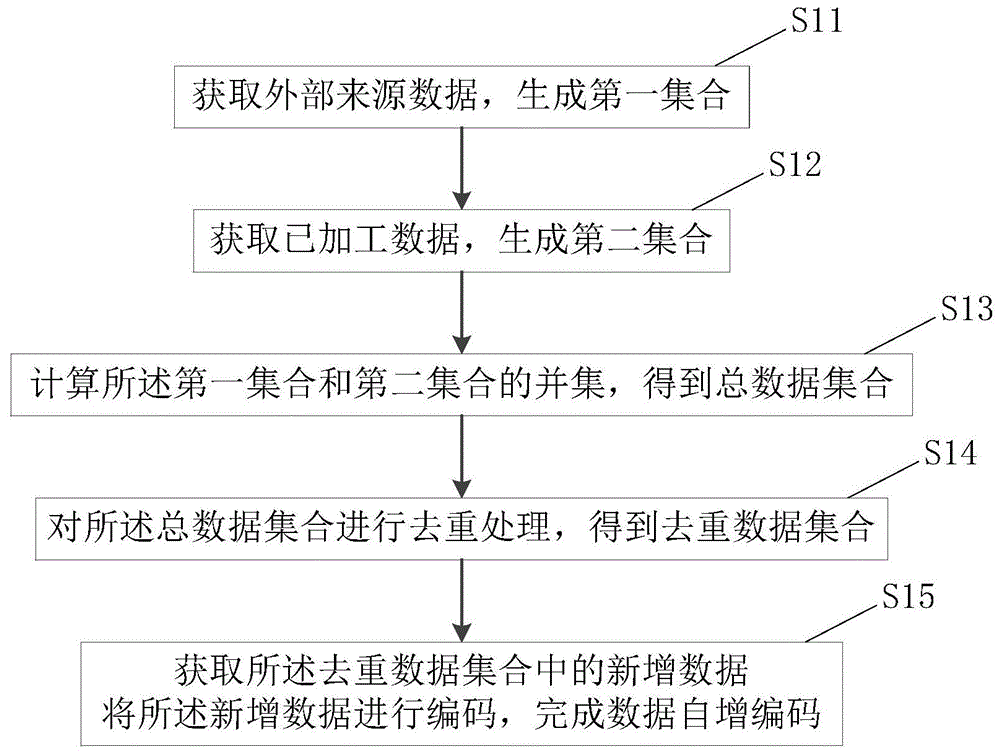
一种数据分布式自增编码方法,包括:
获取外部来源数据,生成第一集合;
获取已加工数据,生成第二集合;
计算所述第一集合和第二集合的并集,得到总数据集合;
对所述总数据集合进行去重处理,得到去重数据集合;
获取所述去重数据集合中的新增数据,将所述新增数据进行编码,完成数据自增编码。
进一步地,所述获取外部来源数据,生成第一集合,具体包括:
获取外部来源数据,构造编码字段和第一字段,得到第一集合;
所述获取已加工数据,生成第二集合,具体包括:
获取紧前已加工好的数据,创造第二字段,得到第二集合;所述第二字段的默认值取所述编码字段的值。
进一步地,对所述总数据集合进行去重处理,得到去重数据集合,具体包括:
按照需要编码的字段对所述总数据集合中的数据进行分组;
按照所述编码字段对所述总数据集合中的数据进行排序;
按预设规定在排序后的数据中取出相应数据,组成去重数据集合。
进一步地,获取所述去重数据集合中的新增数据,将所述新增数据进行编码,完成数据自增编码,具体包括:
按照所述第二字段对所述去重数据集合中的数据进行排序,并在排序后的数据中查找符合预设条件的数据,得到所述新增数据,根据所述编码字段对所述新增数据进行编码,得到新的编码字段的值,完成数据自增编码;该过程实现了新增数据的自编码,同时不会对已编码数据造成影响,已编码的内容编号保持不变。
上述方法无需编写udf函数,通过sql实现hive数据自增编码。
一种数据分布式自增编码系统,包括:
外部来源数据处理模块,用于获取外部来源数据,生成第一集合;
已加工数据处理模块,用于获取已加工数据,生成第二集合;
数据合并模块,用于计算所述第一集合和第二集合的并集,得到总数据集合;
数据去重模块,用于对所述总数据集合进行去重处理,得到去重数据集合;
数据自增编码模块,用于获取所述去重数据集合中的新增数据,将所述新增数据进行编码,完成数据自增编码。
进一步地,所述外部来源数据处理模块,具体用于:
获取外部来源数据,构造编码字段和第一字段,得到第一集合;
所述已加工数据处理模块,具体用于:
获取紧前已加工好的数据,创造第二字段,得到第二集合;所述第二字段的默认值取所述编码字段的值。
进一步地,所述数据去重模块,具体用于:
按照需要编码的字段对所述总数据集合中的数据进行分组;
按照所述编码字段对所述总数据集合中的数据进行排序;
按预设规定在排序后的数据中取出相应数据,组成去重数据集合。
进一步地,所述数据自增编码模块,具体用于:
按照所述第二字段对所述去重数据集合中的数据进行排序,并在排序后的数据中查找符合预设条件的数据,得到所述新增数据,根据所述编码字段对所述新增数据进行编码,得到新的编码字段的值,完成数据自增编码;该过程实现了新增数据的自编码,同时不会对已编码数据造成影响,已编码的内容编号保持不变。
上述系统无需编写udf函数,通过sql实现hive数据自增编码。
一种电子设备,包括:壳体、处理器、存储器、电路板和电源电路,其中,电路板安置在壳体围成的空间内部,处理器和存储器设置在电路板上;电源电路,用于为上述电子设备的各个电路或器件供电;存储器用于存储可执行程序代码;处理器通过读取存储器中存储的可执行程序代码来运行与可执行程序代码对应的程序,用于执行前述数据分布式自增编码方法。
一种计算机可读存储介质,存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现前述数据分布式自增编码方法。
本发明的有益效果体现在:
本发明无需编写udf函数,通过sql实现hive的数据自编码,从而达到给某个已知名称字段进行数据编码的目的,有效降低开发成本,提高开发效率。本发明不同于传统简单的应用排序来对数据进行一次性编码,可对新增的记录内容实现自编码,且已编码的内容编号保持不变。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1为本发明实施例一种数据分布式自增编码方法流程图;
图2为本发明实施例一种数据分布式自增编码系统结构图;
图3为本发明实施例一种电子设备结构示意图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
如图1所示,为本发明一种数据分布式自增编码方法实施例,包括:
s11:获取外部来源数据,生成第一集合;
s12:获取已加工数据,生成第二集合;
s13:计算所述第一集合和第二集合的并集,得到总数据集合;
s14:对所述总数据集合进行去重处理,得到去重数据集合;
s15:获取所述去重数据集合中的新增数据,将所述新增数据进行编码,完成数据自增编码。
优选地,所述获取外部来源数据,生成第一集合,具体包括:
获取外部来源数据,构造编码字段和第一字段,得到第一集合;例如,构造一个编码字段(c_id),默认值为0,再构造一个字段(c_id2),默认值为空(null);
所述获取已加工数据,生成第二集合,具体包括:
获取紧前已加工好的数据,创造第二字段,得到第二集合;所述第二字段的默认值取所述编码字段的值;例如,获取上一次已经加工好的数据,构造一个字段(c_id2),默认值取编码字段(c_id)的值。
优选地,对所述总数据集合进行去重处理,得到去重数据集合,具体包括:
按照需要编码的字段对所述总数据集合中的数据进行分组;
按照所述编码字段对所述总数据集合中的数据进行排序;
按预设规定在排序后的数据中取出相应数据,组成去重数据集合;
例如,对所述总数据集合中的数据按需要编码的字段(c_n)进行分组,再按照编码字段(c_id)进行降序排序,排序后取序号为1的记录,这一步主要是去重保持唯一,若在所述第一集合和第二集合中存在相同的需要编码的字段(c_n),取所述第二集合中的数据,确保相同记录每次编码的唯一性。
优选地,获取所述去重数据集合中的新增数据,将所述新增数据进行编码,完成数据自增编码,具体包括:
按照所述第二字段对所述去重数据集合中的数据进行排序,并在排序后的数据中查找符合预设条件的数据,得到所述新增数据,根据所述编码字段对所述新增数据进行编码,得到新的编码字段的值,完成数据自增编码;例如,对所述去重数据集合中的数据按照构造的字段(c_id2)进行降序排列,得到序号rn2,降序排列后空值会排在后面,然后判断构造的字段(c_id2)是否为空,不为空则取字段(c_id2)的值,为空则取序号rn2作为编码得到新的编码字段(c_id)的值;该过程实现了新增数据的自编码,同时不会对已编码数据造成影响,已编码的内容编号保持不变。
上述方法无需编写udf函数,通过sql实现hive数据自增编码。
如图2所示,为本发明一种数据分布式自增编码系统实施例,包括:
外部来源数据处理模块21,用于获取外部来源数据,生成第一集合;
已加工数据处理模块22,用于获取已加工数据,生成第二集合;
数据合并模块23,用于计算所述第一集合和第二集合的并集,得到总数据集合;
数据去重模块24,用于对所述总数据集合进行去重处理,得到去重数据集合;
数据自增编码模块25,用于获取所述去重数据集合中的新增数据,将所述新增数据进行编码,完成数据自增编码。
优选地,所述外部来源数据处理模块21,具体用于:
获取外部来源数据,构造编码字段和第一字段,得到第一集合;例如,构造一个编码字段(c_id),默认值为0,再构造一个字段(c_id2),默认值为空(null)
所述已加工数据处理模块22,具体用于:
获取紧前已加工好的数据,创造第二字段,得到第二集合;所述第二字段的默认值取所述编码字段的值;例如,获取上一次已经加工好的数据,构造一个字段(c_id2),默认值取编码字段(c_id)的值。
有短笛,所述数据去重模块24,具体用于:
按照需要编码的字段对所述总数据集合中的数据进行分组;
按照所述编码字段对所述总数据集合中的数据进行排序;
按预设规定在排序后的数据中取出相应数据,组成去重数据集合;
例如,对所述总数据集合中的数据按需要编码的字段(c_n)进行分组,再按照编码字段(c_id)进行降序排序,排序后取序号为1的记录,这一步主要是去重保持唯一,若在所述第一集合和第二集合中存在相同的需要编码的字段(c_n),取所述第二集合中的数据,确保相同记录每次编码的唯一性。
优选地,所述数据自增编码模块25,具体用于:
按照所述第二字段对所述去重数据集合中的数据进行排序,并在排序后的数据中查找符合预设条件的数据,得到所述新增数据,根据所述编码字段对所述新增数据进行编码,得到新的编码字段的值,完成数据自增编码;例如,对所述去重数据集合中的数据按照构造的字段(c_id2)进行降序排列,得到序号rn2,降序排列后空值会排在后面,然后判断构造的字段(c_id2)是否为空,不为空则取字段(c_id2)的值,为空则取序号rn2作为编码得到新的编码字段(c_id)的值;该过程实现了新增数据的自编码,同时不会对已编码数据造成影响,已编码的内容编号保持不变。
上述系统无需编写udf函数,通过sql实现hive数据自增编码。
本发明实施例还提供一种电子设备,如图3所示,可以实现本发明图1所示实施例的流程,如图3所示,上述电子设备可以包括:壳体31、处理器32、存储器33、电路板34和电源电路35,其中,电路板34安置在壳体31围成的空间内部,处理器32和存储器33设置在电路板34上;电源电路35,用于为上述电子设备的各个电路或器件供电;存储器33用于存储可执行程序代码;处理器32通过读取存储器33中存储的可执行程序代码来运行与可执行程序代码对应的程序,用于执行前述数据分布式自增编码方法。
处理器32对上述步骤的具体执行过程以及处理器32通过运行可执行程序代码来进一步执行的步骤,可以参见本发明图1所示实施例的描述,在此不再赘述。
该电子设备以多种形式存在,包括但不限于:
(1)服务器:提供计算服务的设备,服务器的构成包括处理器、硬盘、内存、系统总线等,服务器和通用的计算机架构类似,但是由于需要提供高可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高;
(2)其他具有数据交互功能的电子设备。
本发明的实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现前述数据分布式自增编码方法。
本发明无需编写udf函数,通过sql实现hive的数据自编码,从而达到给某个已知名称字段进行数据编码的目的,有效降低开发成本,提高开发效率。本发明不同于传统简单的应用排序来对数据进行一次性编码,可对新增的记录内容实现自编码,且已编码的内容编号保持不变。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!