一种融合方面隐式反馈的试题可解释Top-K推荐方法与流程
本发明属于在线推荐领域的试题推荐方法,具体是一种融合方面隐式反馈的试题可解释top-k推荐方法。
背景技术:
随着互联网的飞速发展,信息过载问题越来越成为用户的痛点。例如,在某在线编程教育平台上,某初中生欲通过平台上的试题提升自身的编程水平,而该生在对自身编程能力不确定的情况下是难以精准地找到试题的。因此,如何通过智能推荐算法自动地捕捉用户的兴趣偏好、编程能力为其进行针对性地推荐成为受关注的问题。由于显式反馈不容易获取,所以常见的基于显式反馈的推荐方法就会因为面临数据稀疏性问题而失效。因此,本发明提供一种融合方面隐式反馈的试题可解释top-k推荐方法。
近几年来,现有工作提出了多种基于方面隐式反馈的试题可解释top-k推荐方法。但是,它们存在着一个问题:辅助信息(如用户评论文本信息)中未观测到的用户隐式反馈都视为负反馈,忽略了其中的缺失值,致使这些方法对用户偏好建模有偏差,从而影响到top-k推荐的性能。
本发明一种融合方面隐式反馈的试题可解释top-k推荐方法,它的思想是将评论中的隐式反馈信息融合到基于贝叶斯个性化排序的矩阵分解中,从而提升top-k排序的性能。为了挖掘评论文本中的未观测的隐式反馈,本章将评论文本中观测到的隐式反馈(正反馈)编码到矩阵分解的因子矩阵中,并通过矩阵分解来恢复未观测到的隐式反馈(负反馈和缺失值),由此区分负反馈和缺失值。为了融合隐式反馈信息提升top-k排序的性能,本章将贝叶斯个性化排序引入到融合了隐式反馈信息的矩阵分解中。
技术实现要素:
本发明的目的在于克服上述现有的推荐方法的不足,提供一种融合方面隐式反馈的试题可解释top-k推荐方法。本系统首先收集用户的评论文本,然后挖掘用户的隐式反馈信息并融合到基于贝叶斯个性化排序的矩阵分解中并进行离线训练,最后将试题推荐列表和可解释信息保存到内存服务器中供在线实时推荐。
本发明是一种融合方面隐式反馈的试题可解释top-k推荐方法,包括以下步骤:
步骤1:通过日志系统收集用户的隐式反馈数据,并保存到数据库中。
步骤2:基于用户的隐式反馈信息构建(用户,试题,方面)三元隐式反馈集p、(用户,试题,方面)三元正隐式反馈集p+、(用户,试题)二元隐式反馈集q、(用户,试题)二元正隐式反馈集q+。
步骤3:构建用户隐式方面兴趣。
步骤4:通过最小化损失函数学习得到模型的参数wm、ha、hb,其中wm表示用户m的因子向量,ha表示已观察到的试题的因子向量,hb表示未观察到的试题的因子向量。
步骤5:利用precision@k和recall@k评价本方法的性能,其中precision@k为查准率,recall@k为查全率,k代表推荐列表的长度。
步骤6:对用户和试题的因子向量进行内积运算,得到重构后的隐式反馈矩阵
步骤7:利用重构后的隐式反馈矩阵
所述步骤1通过日志系统采集用户的隐式反馈信息包括用户的唯一标识、试题的唯一标识、用户的评论信息,并保存于数据库中,具体为:四元组(u,i,rui,t)表示t时刻用户u对物品i的评分记录,四元组(u,i,cui,t)表示t时刻用户u对物品i的隐式反馈信息。
所述步骤2中从数据库中获取用户的反馈信息,并分析用户的评论在方面的正负反馈情况。
根据权利要求1所述的融合方面隐式反馈的试题可解释top-k推荐方法,其特征在于:所述步骤3中构建用户隐式方面兴趣:
其中,wm表示用户偏好向量,共l维,第l维
其中,
其中,σ(·)代表逻辑斯蒂函数,
所述步骤4中最小化损失函数学习得到模型的参数wm、ha、hb:
所述步骤5中利用precision@k和recall@k评价本方法的性能:
其中,rec(m)是根据训练集的数据向用户m提供的推荐列表,test(m)是用户m在测试集上的试题列表,m表示用户数。
所述步骤6中对用户和试题的因子向量进行内积运算,得到重构后的隐式反馈矩阵
其中
所述步骤7中利用重构后的隐式反馈矩阵
附图说明
图1为本发明的推荐流程图。
图2为本发明的推荐算法设计图。
图3为本发明的推荐系统设计图。
具体实施方式
本发明是一种融合方面隐式反馈的试题可解释top-k推荐方法,下面结合附图,详细描述本发明的技术方案:
如图1所示,本发明的主要流程为:
步骤1:通过日志系统收集用户的隐式反馈数据,并保存到数据库中。
步骤2:基于用户的隐式反馈信息构建(用户,试题,方面)三元隐式反馈集p、(用户,试题,方面)三元正隐式反馈集p+、(用户,试题)二元隐式反馈集q、(用户,试题)二元正隐式反馈集q+。
步骤3:构建用户隐式方面兴趣。
步骤4:通过最小化损失函数学习得到模型的参数wm、ha、hb,其中wm表示用户m的因子向量,ha表示已观察到的试题的因子向量,hb表示未观察到的试题的因子向量。
步骤5:利用precision@k和recall@k评价本方法的性能,其中precision@k为查准率,recall@k为查全率,k代表推荐列表的长度。
步骤6:对用户和试题的因子向量进行内积运算,得到重构后的隐式反馈矩阵
步骤7:利用重构后的隐式反馈矩阵
所述步骤1通过日志系统采集用户的隐式反馈信息包括用户的唯一标识、试题的唯一标识、用户的评论信息,并保存于数据库中,具体为:四元组(u,i,rui,t)表示t时刻用户u对物品i的评分记录,四元组(u,i,cui,t)表示t时刻用户u对物品i的隐式反馈信息。
所述步骤2中从数据库中获取用户的反馈信息,并分析用户的评论在方面的正负反馈情况。
所述步骤3中构建用户隐式方面兴趣:
其中,wm表示用户偏好向量,共l维,第l维
其中,
其中,σ(·)代表逻辑斯蒂函数,
所述步骤4中最小化损失函数学习得到模型的参数wm、ha、hb:
所述步骤5中利用precision@k和recall@k评价本方法的性能:
其中,rec(m)是根据训练集的数据向用户m提供的推荐列表,test(m)是用户m在测试集上的试题列表,m表示用户数。
所述步骤6中对用户和试题的因子向量进行内积运算,得到重构后的隐式反馈矩阵
其中
所述步骤7中利用重构后的隐式反馈矩阵
图2示出了本发明方法的设计图,具体包括上述步骤3和4。
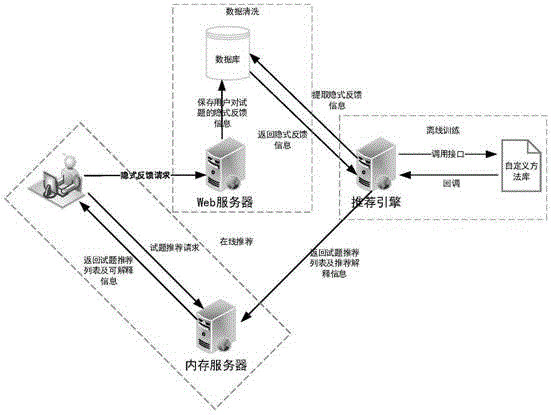
图3示出了一种处理试题推荐的系统结构设计图,该系统设计图由3部分构成:
第一部分为数据处理及保存模块,对应上述步骤1。
第二部分为离线计算模块,对应上述步骤2至6。
第三部分为推荐请求模块,用于用户推荐栏刷新获取。
该系统中的数据流向为:web服务器收集用户的试题评分和隐式反馈信息,然后经过清洗后保存到数据库中,在离线训练时,计算平台到数据库中拉取经过清洗后的数据,包括评分数据和隐式反馈数据,经过推荐引擎生成的推荐结果保存到内存服务器,供用户端随时获取。
采用本发明的试题推荐方法,有益效果如下:(1)将已观测的隐式反馈信息编码到矩阵分解的因子矩阵中,并通过矩阵分解来恢复未观测到的隐式反馈,从而区分未观测隐式反馈中的负反馈和缺失值;(2)通过融合评论中的隐式反馈信息提升了top-k推荐的性能。
以上对本发明实施所提供的一种融合方面隐式反馈的试题可解释top-k推荐方法进行了详细地介绍,本文对本发明的原理和实施方案进行了阐述,以上实施的说明只是用于辅助理解本发明的系统及其核心思想。
- 还没有人留言评论。精彩留言会获得点赞!