结合关键词检索与孪生神经网络的目标领域问答推送方法与流程
本发明涉及数据挖掘和自然语言处理领域,尤其涉及一种结合关键词检索与孪生神经网络的目标领域问答推送方法。
背景技术:
与搜索引擎系统类似,智能问答系统也是从大量数据中找到最能满足用户意图的文字信息。然而,两者的不同之处包括:首先,搜索引擎系统要求用户明确地输入关键词,而智能问答系统允许用户输入更符合人类习惯的自由问句。其次,搜索引擎系统返回大量的搜索结果,需要用户自行从中找出最符合其意图的,而智能问答系统返回一个或少量最符合用户意图的结果,能大大提高用户的信息获取效率。因此,智能问答系统比搜索引擎系统具有更高的技术挑战。
根据底层技术的不同,智能问答系统大致可以分为基于信息检索的智能问答系统、基于阅读理解的智能问答系统、基于知识图谱的智能问答系统等。其中,基于信息检索的智能问答系统指在真实历史问答数据中搜索得到最符合用户当前问题的答案。由于真实历史问答数据通常由领域专家提供,因此基于信息检索的智能问答系统通常精确度较高、覆盖率较低,这种特性使得其较为适合实现专业的、对答案质量要求较高的目标领域的智能问答系统。
现有基于信息检索的智能问答系统的实现技术主要包括关键词检索和语义匹配两种。关键词检索指从用户问题中抽取关键词,然后转化成一个全文检索的任务。由于全文检索可以有效地利用数据库索引,因此执行效率很高。然而,将用户问题抽象成几个关键词,丢失了问题整体的语义和关键词间的关联,导致难以找到最符合用户意图的答案。另一方面,语义匹配指将用户问题和历史问题(或历史答案)进行语义相似度计算,然后返回语义相似度最高的若干答案。语义相似度计算通常基于机器学习模型实现,因此能够较为精确地找到符合用户意图的答案。然而,由于需要计算用户问题和每个历史问题(或历史答案)的语义相似度,计算量巨大,在历史数据很大的情况下难以保证系统的实时性。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种结合关键词检索与孪生神经网络的目标领域智能问答方法,可有效解决上述问题。本发明具体采用的技术方案如下:
一种结合关键词检索与孪生神经网络的目标领域问答推送方法,用于根据用户提出的实时问题推送相应的答案,该方法包括以下步骤:
S1:对目标领域进行知识构建和历史问题数据预处理,具体包含以下子步骤 S101~S104:
S101:获取并筛选出与目标领域相关的词条作为概念词,建立领域概念词表;
S102:对领域概念词表中的每个概念词,给出表达方式不同的同义词,在此基础上建立领域概念词消歧表,将不同表达方式的同义领域概念词映射到同一个词;
S103:将领域概念词表加入分词词表,然后对每个历史问题进行分词和去停用词处理;
S104:对每个历史问题,基于领域概念词表和领域概念词消歧表将句子中出现的所有不同表达方式的领域概念词替换为同一个词;
S2:基于孪生神经网络训练语义相似度模型,用以计算任意两个句子的语义相似度值,具体包含以下子步骤S201~S205:
S201:收集短句样本,并根据短句表达的含义将其进行分类,构建训练集 TS;所述训练集TS里的每个样本为一个三元组其中和分别为经过分词、去停用词和消歧预处理的两个短句,yi为和的关系标注,若两个短句属于同一类型则yi为1,属于不同类型则yi为0;
S202:采用孪生神经网络训练语义相似度模型,网络结构包括输入层、卷积层、交互层和输出层;
在所述输入层中,基于词嵌入技术将和中所有词替换为其对应的向量,对向量进行纵向拼接得到两个矩阵和然后通过尾部截断或填充全0向量的方式将和都处理成大小为l×d的输入矩阵,其中l为短句统一长度, d为词向量维度;
在所述卷积层中,采用两个参数完全共享的卷积神经网络分别处理和每个卷积神经网络首先采用多个不同尺寸的卷积核对输入矩阵进行卷积操作;然后采用Max Pooling Over Time策略对卷积结果进行池化操作;最后拼接池化结果得到卷积特征向量,记和的卷积特征向量分别为和
在所述交互层中,基于余弦相似度计算和的相似度;
在所述输出层中,采用对比损失函数作为训练的损失函数,输出和的预测相似度值;
S3:针对用户输入的实时问题Qi,通过抽取关键词对历史问题进行全文检索,得到候选问题列表,具体包含以下子步骤S301~S304:
S301:对实时问题Qi进行预处理,所述预处理包括分词、去停用词和消歧;
S302:首先基于TextRank算法计算Qi中每个词的重要度权值;然后抽取 Qi中所有消歧后的领域概念词,若抽取出的领域概念词数量小于等于关键词数量设定阈值k,则保留所有抽取出的领域概念词;否则保留重要度权值最高的k个抽取出的领域概念词;将最终保留的领域概念词集记为CW(Qi),其包含的词的数量为kCW;
S303:若kCW<k,在Qi包含的非领域概念词中挑选重要度权值最高的(k-kCW) 个词作为普通关键词,将最终保留的普通关键词集记为NW(Qi);
S304:实时问题Qi的最终关键词集KW(Qi)=CW(Qi)∪NW(Qi),基于Lucene 引擎检索至少包含KW(Qi)中一个词的所有预处理后的历史问题,形成候选问题列表CQ(Qi);
S4:匹配度值计算和答案返回:计算实时问题Qi和候选问题列表CQ(Qi)中每个候选问题的关键词一致性和语义相似度,然后融合关键词一致性值和语义相似度值得到每个候选问题的匹配度值,按照匹配度值高低排序返回答案,具体包含以下步骤:
S401:对CQ(Qi)中每个候选问题CQj,计算其包含CW(Qi)中词的数量n(CQj) 和包含NW(Qi)中词的数量m(CQj),然后对n(CQj)和m(CQj)进行加权求平均计算关键词一致性值s1(Qi,CQj);
S402:对CQ(Qi)中每个候选问题CQj,将实时问题Qi和CQj输入训练好的语义相似度模型,得到两者的语义相似度预测值s2(Qi,CQj);
S403:对s1(Qi,CQj)和s2(Qi,CQj)加权求和计算匹配度值s(Qi,CQj);
S404:从候选问题中挑选匹配度值最高的一个或多个,其对应的答案作为实时问题Qi的答案进行返回推送。
基于上述技术方案,其中的部分步骤可采用如下优选方式实现。
优选的,步骤S1中所述的与目标领域相关的词条,采用网络爬虫爬取百度百科词条数据,然后由领域专家人工进行筛选得到。
优选的,步骤S3中对实时问题Qi的预处理与S1中对历史问题的预处理相同,均包括分词、去停用词和消歧。
优选的,步骤(2)中所述的多个不同尺寸的卷积核的宽度均为w,高度则不同。
优选的,步骤(2)中所述的对比损失函数L计算公式如下:
ei=|yi′-yi|
其中yi′为样本tsi的预测语义相似度值,yi为样本tsi包含短句的关系标注,N 为训练集TS中的样本总数。
优选的,步骤(4)中所述的关键词一致性值s1(Qi,CQj)计算公式如下:
其中α为领域概念词权重,0<α<1;β为普通关键词权重,0<β<1,并且β<α。
优选的,步骤(4)中所述的匹配度值s(Qi,CQj)计算公式如下:
s(Qi,CQj)=λs1(Qi,CQj)+(1-λ)s2(Qi,CQj)
其中λ为关键词一致性值权重,0<λ<1。
优选的,所述的历史问题数据中。每个历史问题均具有对应的答案。
本发明提出的一种结合关键词检索与孪生神经网络的目标领域问题答案推送方法,结合关键词检索和基于孪生神经网络训练语义相似度模型实现目标领域的智能问答及最优答案的推送。相比于传统的答案推送方法,本法明具有如下收益:
1、结合信息检索技术和深度学习技术,有效地平衡了方法的效率和性能;
2、结合领域知识关键词匹配和深度模型相似度匹配,同时保证了方法的召回率和准确率。
附图说明
图1为结合关键词检索与孪生神经网络的目标领域问题答案推送方法的流程图;
图2为语义相似度模型的网络结构图;
图3为匹配度值计算的过程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
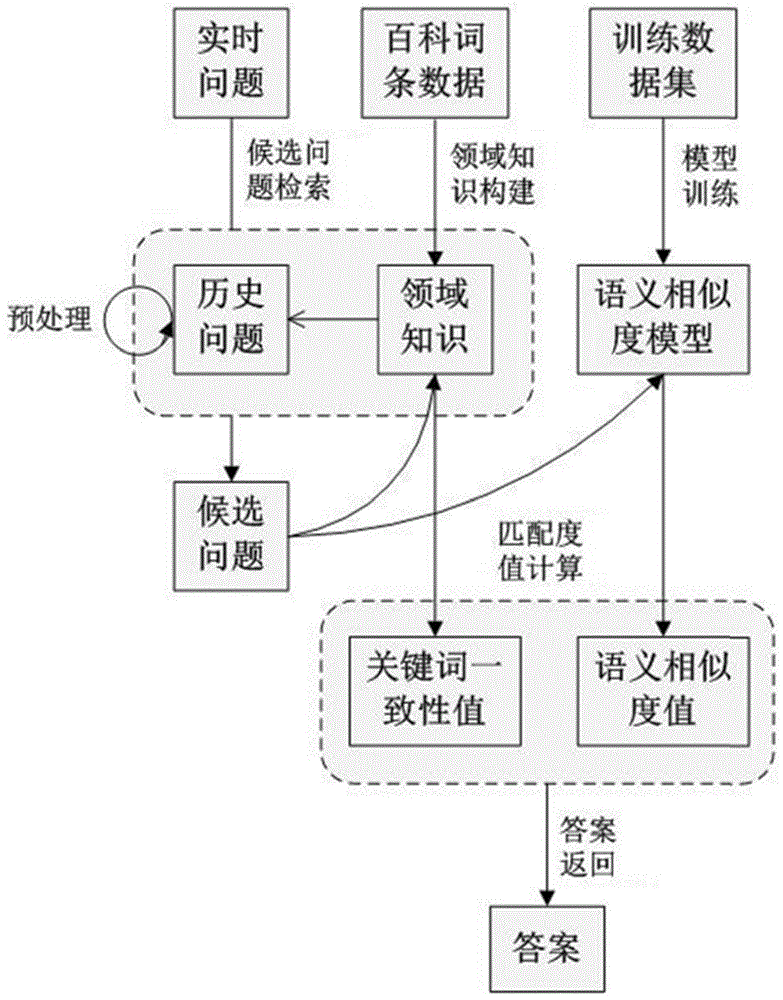
如图1所示,一种结合关键词检索与孪生神经网络的目标领域问题答案推送方法,该方法用于在特定的领域中,根据用户提出的实时问题自动推送相应的答案。其基本的实现思路为:(1)结合互联网和专家经验构建领域知识,并基于领域知识对历史问题进行预处理;(2)基于孪生神经网络训练语义相似度模型;(3) 对用户提出的实时问题,抽取其包含的关键词,并在此基础上进行全文检索,得到候选问题列表;(4)对每个候选问题,基于领域知识计算其关键词一致性值,基于语义相似度模型计算其语义相似度值,并综合两者计算匹配度值,在此基础上返回匹配度值最高的若干答案。
下面具体描述本实施例中该方法的具体实现步骤:
S1:对目标领域进行知识构建和历史问题数据预处理:收集领域内的百科词条作为概念词建立概念词表,并收集概念词的同义词建立领域概念词消歧表;在此基础上对历史问题数据进行预处理,其中预处理包括分词、去停用词、消歧。
该步骤具体包含以下子步骤S101~S104:
S101:领域概念词表构建:采用网络爬虫爬取与目标领域相关的百度百科词条数据,然后由领域专家人工从中获取并筛选出与目标领域相关的词条作为概念词,建立领域概念词表。当然,这些词条也可以通过其他方式进行获取,但是应当保证与目标领域的相关性,以提高其准确性。
S102:领域概念词消歧表构建:对领域概念词表中的每个概念词,由领域专家给出表达方式不同的同义词,在此基础上建立领域概念词消歧表,将不同表达方式的但具有相同含义的同义领域概念词映射到同一个词,以提高相似度计算的准确性。
S103:分词:将领域概念词表加入分词词表,然后对每个历史问题进行分词和去停用词处理。
S104:消歧:对每个历史问题,基于领域概念词表和领域概念词消歧表将句子中出现的所有不同表达方式的领域概念词替换为同一个词。
历史问题数据中,每个历史问题均预先带有对应的答案,用于供后续调用推送。历史问题的样本应当足量,能够尽可能覆盖用户可能提问的类型。
S2:语义相似度模型训练:基于孪生神经网络训练语义相似度模型,用以计算任意两个句子的语义相似度值,具体包含以下子步骤S201~S205:
S201:训练集构建:收集大量的短句样本,并根据短句表达的含义人工将其进行分类,构建训练集TS。其中,训练集TS里的每个样本为一个三元组其中和分别为经过分词、去停用词和消歧预处理的两个短句,yi为和的关系标注,若两个短句属于同一类型则yi为1,属于不同类型则yi为0。
S202:相似度模型训练:采用孪生神经网络训练语义相似度模型,其网络结构如图2所示,包括输入层、卷积层、交互层和输出层。
在输入层中,基于词嵌入技术将和中所有词替换为其对应的向量,对向量进行纵向拼接得到两个矩阵和然后通过尾部截断(长度过长时) 或填充全0向量(长度过短时)的方式,将和都处理成大小为l×d的输入矩阵,其中l为短句统一长度,d为词向量维度。
在卷积层中,采用两个参数完全共享的卷积神经网络分别处理和每个卷积神经网络首先采用多个不同尺寸的卷积核(卷积核的宽度均为d,高度不同)对输入矩阵进行卷积操作;然后采用Max Pooling Over Time策略对卷积结果进行池化操作;最后拼接池化结果得到卷积特征向量,记和的卷积特征向量分别为和
在交互层中,基于余弦相似度计算和的相似度
在输出层中,采用对比损失函数作为训练的损失函数,输出和的预测相似度值。本模型采用对比损失函数L作为训练的损失函数,计算公式如下所示:
ei=|yi′-yi|
其中yi′为样本tsi的预测语义相似度值,yi为样本tsi包含短句的关系标注,N 为训练集TS中的样本总数,ei为中间参数。
由此,完成语义相似度模型的训练过程,模型精度达到要求后即可用于后续的实际使用。
S3:候选问题检索:当用户输入提问的实时问题Qi时,针对实时问题Qi,通过抽取关键词对历史问题进行全文检索,得到候选问题列表。该步骤具体包含以下子步骤S301~S304:
S301:实时问题预处理:对实时问题Qi进行预处理,此处对实时问题Qi的预处理最好与与S1中对历史问题的预处理相同,即按照S103和S104的方式进行分词、去停用词和消歧步骤。
S302:领域概念词抽取:首先基于TextRank算法计算Qi中每个词的重要度权值;然后抽取Qi中所有消歧后的领域概念词,若抽取出的领域概念词数量小于等于关键词数量设定阈值k,则保留所有抽取出的领域概念词;否则保留重要度权值最高的k个抽取出的领域概念词。将最终保留的领域概念词集记为CW(Qi),其包含的词的数量为kCW。
S303:普通关键词抽取:若kCW<k,在Qi包含的非领域概念词中挑选重要度权值最高的(k-kCW)个词作为普通关键词,将最终保留的普通关键词集记为NW(Qi)。
S304:全文检索:实时问题Qi的最终关键词集KW(Qi)=CW(Qi)∪NW(Qi),基于Lucene引擎检索至少包含KW(Qi)中一个词的所有预处理后的历史问题,形成候选问题列表CQ(Qi)。候选问题列表是与实时问题Qi可能相关的问题的集合,可进一步通过筛选后进行推送。
S4:匹配度值计算和答案返回:计算实时问题Qi和候选问题列表CQ(Qi)中每个候选问题的关键词一致性和语义相似度,然后融合关键词一致性值和语义相似度值得到每个候选问题的匹配度值,按照匹配度值高低排序返回答案。本实施例中,匹配度值计算的详细步骤如图3所示,具体包含以下步骤:
S401:关键词一致性计算:对CQ(Qi)中每个候选问题CQj,计算其包含CW(Qi) 中词的数量n(CQj)和包含NW(Qi)中词的数量m(CQj),然后对n(CQj)和m(CQj)进行加权求平均计算关键词一致性值s1(Qi,CQj)。本实施例中,关键词一致性值s1(Qi, CQj)计算公式如下:
其中α为领域概念词权重,0<α<1;β为普通关键词权重,0<β<1,并且β<α。α、β的具体取值可以根据实际进行调整,选择最佳值。
S402:语义相似度计算:对CQ(Qi)中每个候选问题CQj,将实时问题Qi和 CQj输入训练好的语义相似度模型,得到两者的语义相似度预测值s2(Qi,CQj);
S403:匹配度值计算:对s1(Qi,CQj)和s2(Qi,CQj)加权求和计算匹配度值s(Qi, CQj)。本实施例中,匹配度值s(Qi,CQj)计算公式如下:
s(Qi,CQj)=λs1(Qi,CQj)+(1-λ)s2(Qi,CQj)
其中λ为关键词一致性值权重,0<λ<1,取值根据实际进行调整,选择最佳值。
S404:答案返回:经过上述计算,每个候选问题均具有一个与实时问题Qi之间的匹配度值,从候选问题中挑选匹配度值最高的一个或多个,这些候选问题对应的答案就可以作为实时问题Qi的答案,进行返回,推送给用户。推送的候选问题个数可以根据实际需要进行设定。
基于上述方法,可以根据特定的领域,快速构建智能问答系统,其结合关键词检索和基于孪生神经网络训练语义相似度模型实现目标领域的智能问答及最优答案的推送,同时兼顾了效率和性能,保证了方法的召回率和准确率。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!