基于智能物联网系统的行人重识别方法与流程
本发明涉及一种行人重识别方法,尤其涉及一种基于智能物联网系统和深度学习的行人重识别方法。
背景技术:
随着人工智能技术的迅猛发展和视频监控设备的日益普及,智能监控以其准确、及时和功能丰富而受到社会各界的广泛关注。目前,很多公共场合都布有监控,视频监控已经成为继数字电视、视频会议之后的又一个重大视频应用,而且日益成为“体量”最大的一个视频应用系统。治安管理监控作为视频监控领域的一个重要应用,其现有技术存在视频监控功能单一,记录繁多,智能监控在不同角度不同光照条件下对于行人图像的特征学习率不高等诸多缺点,如何提高智能视频监控的特征提取率,如何使得智能监控在复杂环境下训练学习所得的模型过/欠拟合等问题面临重大挑战。随着未来安防系统性价比的不断提高和数字高清化、智能化等技术的发展,市场应用空间将不断增长。
智能视频分析技术是监控技术第三个发展阶段“机器眼+机器脑”中的“机器脑”部分,利用机器,将“人脑”对于视频画面的监控判断,进行数据分析提炼特征形成算法植入机器,形成“机器脑”对视频画面自动检测分析,并作出报警或其他动作。它借助计算机强大的数据处理能力过滤掉视频画面无用或干扰信息、自动分析、抽取视频源中的关键有用信息,从而使摄像机不但成为人的眼睛,也使计算机成为人的大脑。现有的智能视频分析行人的方案存在以下问题:1、现有的方案下,多摄像头实时监控但识别特征无法共享;2、现有的行人识别算法只能对行人进行有限个主要特征的学习,而对细节特征点的提取还远远不足以满足现实中行人图像识别精度的要求;3、为了提高识别精度而提出的使用深度卷积网络训练模型的方案,在复杂环境条件下由于提取特征点过多,会导致训练出来的模型过拟合。
技术实现要素:
发明目的:针对以上问题,本发明提出一种基于智能物联网系统的行人重识别方法,能够提升行人重识别的精确度,有效提高安防监控系统对行人图像的识别能力。
技术方案:本发明所采用的技术方案是一种基于智能物联网系统的行人重识别方法,包括以下步骤:
(1)制作行人重识别数据集;
所述步骤1包括以下过程:
(11)将多个国际公认的行人重识别数据集进行混合打包,所述行人重识别数据集包括market1501、cuhk03、dukemtmc和mars数据集;
(12)将数据集中的图像数据归一化预处理为256*128像素大小。
(2)利用深度残差网络训练行人重识别模型;
其中,所述步骤2包括以下过程:
(21)将预处理后的图像数据作为输入,经过7╳7╳64的卷积核运算输出;
(22)经过3╳3的最大池化层;
(23)依次经过深度逐渐增加的多个残差块组进行特征值深度学习;其中每个残差块组由连续的若干单个残差块组成,具体是由3个深度为256的残差块、4个深度为512的残差块、6个深度为1024的残差块以及3个深度为2048的残差块顺序组成。
进一步的,所述的单个残差块中包括三层卷积神经网络,第一层含有1╳1卷积核,第二层含有3╳3卷积核,第三层含有1╳1卷积核。先降维再升维的处理可以提高计算效率。
(24)经过平均池化层输出与目标人数相等的图片特征节点。
(3)通过多个摄像头从不同角度实时采集行人连续帧图像发送至服务器,并对采集到的行人连续帧图像采用深度残差网络进行图像特征提取;
(4)将图像特征与步骤2中所得到的模训练型进行匹配,识别行人身份。
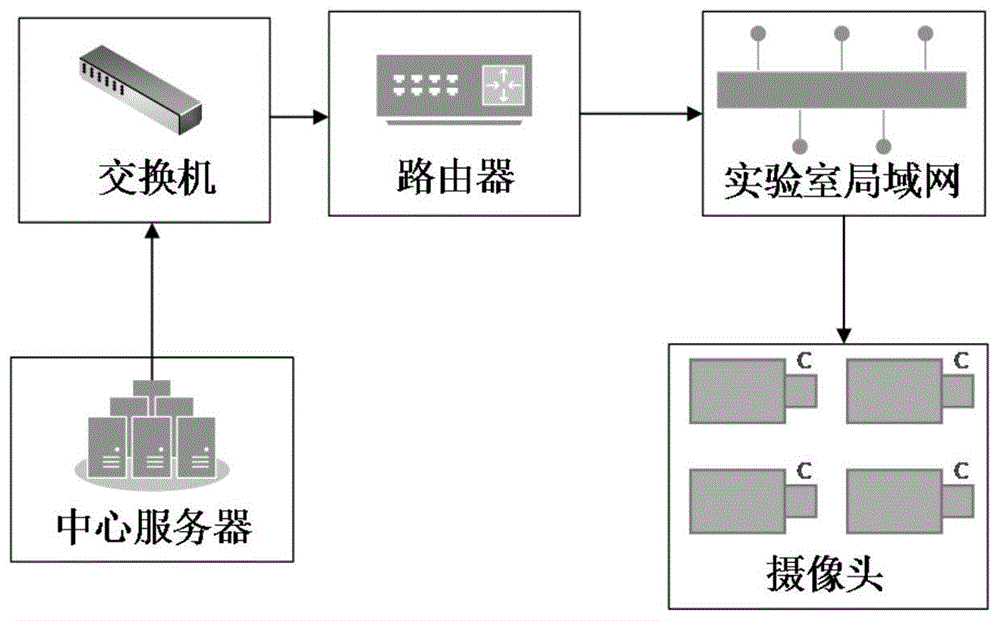
本发明还提供了一种应用于行人重识别方法的智能物联网系统,其特征在于:该系统包括中心服务器、交换机、路由器和多个用于采集行人视频图像的摄像头;中心服务器与交换机相连接,通过局域网内的路由器与摄像头通信,实时获取监控区域的连续帧图像,并对实时图像进行行人重识别。
有益效果:本发明将深度学习和特征识别相结合应用于安防监控,针对拓展安防视频监控功能做出创新优化。与现有技术相比有以下优点:第一,搭设通过交换机和路由器连接实验室局域网的中心服务器的多摄像头监控系统,所有的图片和视频记录都上传至服务器上进行处理,解决了多摄像头识别特征共享的问题;第二,利用深度残差网络提取行人数据集的图像特征并训练行人重识别模型,提高了治安监控的准确性以及识别率,同时加快了运行速率;第三,训练行人重识别模型时采用混合数据集,提高了模型精度;第四,本发明所述的残差网络中,单个残差块采用了3层神经网络结构,先降维再升维的处理方法减少了运算过程中的冗余参数,提高了运算效率。该发明可以应用于视频监控的多个场合,包括银行、商场、企业等,相比于传统监控方案,极大地提升了监控系统的智能性和安全性。
附图说明
图1是本发明所述智能物联网系统结构框图;
图2是本发明所述行人重识别方法流程图;
图3是本发明所述残差块示意图;
图4是本发明所述深度残差网络训练模型的过程示意图。
具体实施方式
下面结合附图和实施例对本发明的技术方案作进一步的说明。
本发明所述的基于智能物联网系统如图1所示,包括中心服务器、交换机、路由器和多个1080p网络摄像头。将4台摄像头安装在试验区域的不同位置,用于采集行人视频图像。4台摄像头就近接入网络端口,通过局域网与路由器相连,连接着服务器的交换机连通路由器,摄像头通过调用opencv实时获取监控区域的连续帧,帧速率可达30帧/秒。获取的帧图像通过局域网实时传输到中心服务器上进行行人重识别。中心服务器的设备配置如下,cpu采用intelcorei7-6800k,内存32gddr4,gpu采用nvidiagetforcegtx1080ti,操作系统为ubuntu16.04lts,深度学习框架为pytorch开源框架。
本发明所述的行人重识别方法的流程图如图2所示,包括以下步骤:
(1)制作行人重识别数据集。
在训练行人识别模型前,为了提高模型的精确度和泛化能力,将多个国际公认的行人重识别数据集包括market1501,cuhk03,dukemtmc和mars进行了混合打包,将数据归一化预处理为256*128像素大小的行人图像,训练集包括行人2000人(其中选自market1501的500人,cuhk03的400人,dukemtmc的500人,mars的600人),共有40000张行人图像数据作为训练集。测试集包括行人1000人(其中选自market1501的250人,cuhk03的200人,dukemtmc的250人,mars的300人),共有20000张行人图像数据作为测试集。通过研究测试的结果,发现改变数据集的像素大小会对模型训练与测试产生影响。经过反复地测试,得出结论:归一化预处理为256*128像素大小的行人图像所得到的模型,它的精确度和鲁棒性是最优的。像素如果低于256*128像素,则在market1501和mars的行人图像识别上准确率会有所降低;像素如果高于256*128像素,则在cuhk03和dukemtmc的行人图像识别上准确率会有所降低。我们猜测可能是因为当改变了原图像的像素后,原图像的一些特征信息可能会由于像素变化而发生改变,就如同我们放大一张照片后,照片上人物的细节会变得模糊。所以我们在制作训练集和测试集的时候,需要考虑到多种数据集的像素大小,取一个相对折中的大小作为行人数据集的统一规格,对于上述的混合打包数据集,该大小即为256*128像素。
(2)利用深度残差网络训练行人重识别模型
简单堆叠过多的神经网络会导致梯度消失或爆炸以及精度退化等问题,但在处理行人重识别问题时,由于数据量很大,又需要较深的网络去更加精确地提取行人图像特征。由此本发明提出了残差网络快速通道的思想来避免梯度消失的问题。深度残差网络由很多个残差块组成,单个残差块示意图如图3(b)。图3(a)是传统残差网络残差块的结构,它是一个两层的神经网络,在l层进行激活,得到al+1,再次进行激活,两层之后得到al+2。激活过程首先从al开始,进行线性激活,根据公式:
zl+1=wl+1al+bl+1
上式中al代表l层的激活层输入样本矩阵,zl+1代表l+1层的激活层输出。通过al算出zl+1,即al乘以权重矩阵wl+1,再加上偏差因子bl+1,然后zl+1再通过relu非线性激活函数得到al+1,迭代入上述公式可以得到zl+2,这是特征提取的主路径。
而我们在深度神经网络中处理行人图片时,采用针对图3(a)改进后的图3(b)所示的残差块。不仅将输入al直接向后传输,拷贝到神经网络的深层,每两层形成一个捷径,与relu非线性激活函数g的输入相加,即:
al+2=g(zl+2+al)
其中,g代表relu非线性激活函数,al+2代表残差块的输出,zl+2代表l+2层的激活层输出。而且在获得zl+2的过程采用了先经过1╳1╳64卷积核降维,然后经过3╳3╳64的卷积核升维的方法,可以减少运算过程中的冗余参数,提高运算效率。
利用深度残差网络训练模型的过程如图4所示。在达到相同感受野的情况下,卷积神经网络的深度越小,所需要的参数和计算量越少,所以采用了深度层层递进的计算方法来减少运算量。并且通过数据实验,对每一层卷积的参数及层数进行了实验优化,得到了相对最优的识别结果所对应的深度残差网络训练模型如下。将步骤1制作的归一化成256*128矩阵的行人图片数据集作为输入数据,第一层经过一个7╳7,深度64的卷积神经网络,输出矩阵再经过一个3╳3的最大池化层后依次进入连续的三个残差块,输出矩阵缩小一半。所述单个残差块的结构如图3(b)所示,其中包括三层卷积神经网络,第一层包含有1╳1╳64卷积核,第二层包含有3╳3╳64卷积核,第三层包含有1╳1╳256卷积核。然后依次经过连续的四个结构相同、深度增加的残差块,输出矩阵再次缩小一半,其中单个残差块中第一、二层中卷积核的深度为128,第三层中深度为512。再然后依次进入连续的六个残差块,输出矩阵再次缩小一半,其中单个残差块中第一、二层中卷积核的深度为256,第三层中深度为1024。最后是依次进入连续的三个残差块,输出矩阵再次缩小一半,其中单个残差块中第一、二层中卷积核的深度为512,第三层中深度为2048。卷积结束后,再经过一个平均池化层后全连接输出1000个节点表示行人图片的特征。一般情况下,最后一个输出层的节点个数与分类任务的目标数相等。那么对于每一个行人图片样例,深度残差神经网络可以得到一个1000维的数组作为输出结果,数组中每一个维度会对应一个类别。在最理想的情况下,如果一个样本属于k,那么这个类别所对应的的输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的label,是神经网络最期望的输出结果。但实际训练中,由于样本误差,基本不存在节点完全对应的情况,这也是训练的模型没办法做到100%识别的原因之一。通过以上过程,就可以实现即使在行人重识别问题当中构建深度的神经网络,也不会出现梯度消失和性能下降的问题。
(3)多个摄像头从不同角度实时采集行人连续帧图像发送至服务器,并对采集到的行人连续帧图像采用深度残差网络进行图像特征提取,其图像特征提取的步骤与步骤2相同。
(4)将图像特征与步骤2中所得到的模训练型进行匹配,识别行人身份。即经过模型计算的图像特征值与原模型中训练得到的特征值进行比较,计算损失值。本例中计算损失值的算法为交叉熵损失,如果损失小于某个定值,说明匹配成功,成功识别目标。所述定值可调。其他诸如三重损失的算法同样可以计算该损失值。
- 还没有人留言评论。精彩留言会获得点赞!