基于CWK-means的在线学习资源质量分析方法与流程
本发明涉及数据分析领域,具体涉及一种基于cwk-means的在线学习资源质量分析方法。
背景技术:
互联网+教育技术的飞速发展给传统的教学模式带来了一个新的改革创新,我国在线教育发展迅速,用户规模呈直线上升趋势,在线学习的出现给学习者提供了很多便利,如今网络上的学习资源数不胜数,但质量良莠不齐。学习资源质量不高直接影响学习者的学习体验和学习效果,导致完成网络课程学习的人很少、课程的利用率低。在线学习资源质量不高的问题亟待解决,但很少有人使用在线学习平台中的学习行为数据去分析、改进在线学习资源的质量。因此使用数据挖掘技术通过学习者的学习行为分析学习资源质量,并挖掘学习者学习行为与学习资源质量的关系,从源头上解决学习资源质量问题,给学习者提供更优质的学习资源,这是非常有意义的。
技术实现要素:
针对上述存在的问题,本发明提出一种基于cwk-means算法的在线学习资源质量分析方法,以提高学习资源质量。
为实现上述目的,本发明具体技术方案如下:一种基于cwk-means的在线学习资源质量分析方法,包括以下步骤:
1)从在线学习平台采集日志数据和数据库数据,构建特征向量;所述日志数据包括视频学习行为数据、文本学习行为数据和论坛学习行为数据,所述数据库数据包括测试学习行为数据和反馈数据;所述特征向量包括视频学习行为数据特征向量、文本学习行为数据特征向量和论坛学习行为数据特征向量、测试学习行为数据特征向量和反馈数据特征向量;所述视频学习行为数据的特征向量表示为:
video={slv,pn,pt,an,at,rn,rt}
其中,slv、pn、pt、an、at、rn、rt分别代表学习时长、暂停次数、暂停时长、前进次数、前进时长、后退次数、后退时长;所述文本学习行为数据的特征向量表示为:
text={slt,fs,bs,ma,dl,cp,crt}
其中,slt、fs、bs、ma、dl、cp、crt分别代表学习时长、前进滚动、后退滚动、标记、下载、复制、收藏;所述论坛学习行为数据的特征向量表示为:
forum={slf,wr,pr,rr,crf}
其中,slf、wr、pr、rr、crf分别代表学习时长、看帖记录、发帖记录、回帖记录、收藏记录;所述测试学习行为数据的特征向量表示为:
examinate={sle,es,wq}
其中,sle、es、wq分别代表测试时长、测试成绩、错题;所述反馈数据的特征向量表示为:
feedback={ur,fs,ft,fr}
其中,ur、fs、ft、fr分别代表用户、反馈分数、反馈时间和反馈资源;
2)数据预处理,构建数据集x,记为:x={x1,x2,…,xn},xi表示数据集x中第i个数据对象,每个数据对象包含m个特征,表示为xi={xi1,xi2,…,xim},xij为第i个数据对象的第j个特征属性;
3)采用主客观相结合的方法计算各个特征属性的权重,第m个特征xim的权重记为
4)利用权重计算初始聚类中心;
5)利用步骤3)和步骤4)中计算出的权重和初始聚类中心,通过k-means算法对学习资源聚类即cwk-means算法对学习资源聚类,每个聚类对应一个质量等级。
进一步的,上述步骤2)中,数据预处理包括数据清洗、数据集成、数据归约、数据变换;所述数据清洗包括分析数据、缺失值处理、异常值处理、去重处理、噪音数据处理;所述数据集成采用模式集成方法;所述数据变换包括平方根转换、对数转换、倒数变换。
进一步的,上述步骤3)中第m个特征xim的权重
3.1)建立系统的递阶层次结构模型,层次结构模型包括目标层、准则层、方案层;
3.2)根据系统的递阶层次结构模型构造判断矩阵a=(aij)n*n,记为:
其中,aij为同一层次中关于某一准则重要性的两两比较的结果,取值方法如下:特征i与特征j相比较,具有相同重要性取值为1,前者比后者稍重要取值为3,前者比后者明显重要取值为5,前者比后者强烈重要取值为7,前者比后者极端重要取值为9;取值2、4、6、8表示上面相邻判断的中间值;i与j之比为aij则j与i之比为aji=1/aij;
3.3)检验各判断矩阵是否满足一致性要求,如果满足一致性要求转步骤3.4),否则转步骤3.2)修改判断矩阵;
3.4)计算主观权重w,计算公式如下:
aw=λmaxw
3.5)利用资源质量分析结构模型构建原始数列矩阵r,记为:
其中,rij表示评价对象i在评价指标j下的评价值;
3.6)对原始数列矩阵r中的数据进行无钢化处理,使各个指标具有可比性,其中,选取的指标包括越大越优型指标和越小越优型指标,所述越大越优型指标计算公式如下:
所述越小越优型指标计算公式如下:
其中,vij表示rij经过无钢化处理之后的数值,max(rj)和min(rj)分别表示第j个指标的最大值和最小值;
3.7)计算第j个指标下第i个对象指标值所占比重pij,计算公式如下:
3.8)计算第j个指标的熵值,计算公式如下:
3.9)计算客观权重w,计算公式如下:
其中,dj为差异系数,dj=1-ej,dj越大表示该指标包含的信息量越大,应该赋予越大的权重;
3.10)使用拉格朗日乘子法组合计算出来的两种权重,计算最终的权重
其中,wi为层次分析法计算出来的权重,wi为熵权法计算出来的权重。
进一步的,上述步骤4)中初始聚类中心的计算方法包括如下步骤:
4.1)计算两两数据对象之间基于权重的欧式距离,任意对象xi,xj(1≤i≠j≤n)之间基于权重的欧式距离公式如下:
其中,
4.2)计算数据集中的数据对象xi(i∈[1,n])对应的距离密度,计算公式如下;
4.3)计算数据集中数据对象xi(i∈[1,n])的邻域半径ri;
其中,cr(cr∈(0,1))为邻域半径调节系数,当cr=0.13时有较好的聚类效果;
4.4)依次计算数据对象xi的点密度d(xi),即以xi为圆心,邻域半径ri为半径的球形域内包含的数据对象个数;
d(xi)=|{p|d(xi,p)≤ri,p∈x}|
4.5)把数据集中的数据对象按照点密度d(xi)降序排放;
4.6)使用分离系数函数确定k的值,分离系数函数表示为:
其中,uij是xi在第j个类中的隶属度,k的最优选择公式为:
其中,ω为所有聚类结果;
4.7)取点密度最大的数据对象作为第一个初始聚类中心c1;
4.8)选择一个和c1距离超过r1的且密度仅次于c1的数据对象作为第二个初始聚类中心;
4.9)判断是否找到k个聚类中心,如果找到转步骤5),否则转步骤4.8)。
进一步的,上述步骤3.3)中检验各判断矩阵一致性的方法为:计算出判断矩阵的最大的特征根λmax,计算一致性指标ci,计算一致性比例cr,当cr<0.10时,满足一致性要求,其中一致性指标计算公式如下:
一致性比例计算公式如下:
ri是同阶随机判断矩阵的一致性指标的平均值。
本发明的有益效果在于克服k-means算法对初始聚类中心比较敏感的问题,减小了无关属性对学习资源聚类的影响,使得学习资源的划分更科学、提高了资源聚类的精确度,使得学习资源的优劣对比更加明显;更有效的分析学习资源存在的问题,从而提高学习资源质量。
附图说明
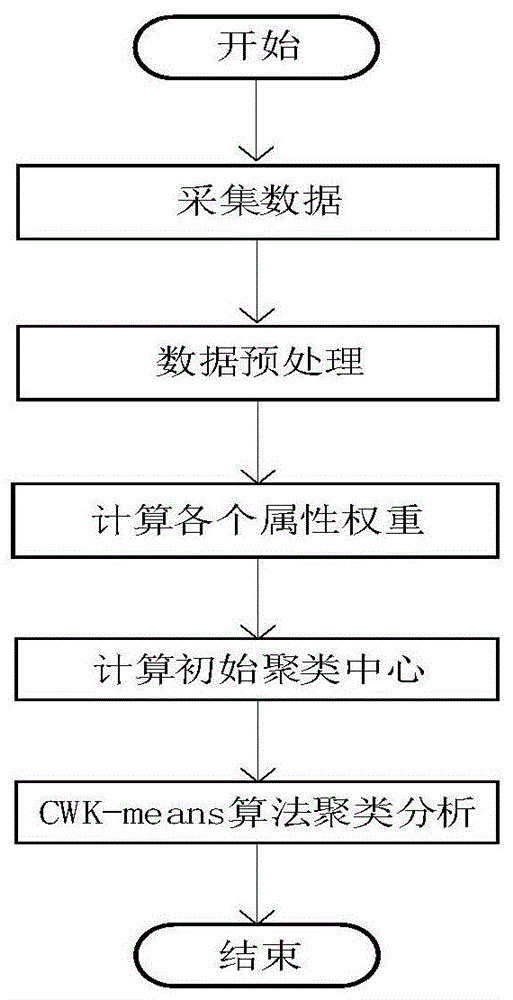
图1是资源质量分析方法流程图。
图2是资源质量分析的递阶层次结构模型图。
图3是cwk-means算法的流程图。
图4是学习资源质量分析模型图。
具体实施方式
下面结合附图以及具体实施例对本发明作进一步的说明,需要指出的是,下面仅以一种最优化的技术方案对本发明的技术方案以及设计原理进行详细阐述,但本发明的保护范围并不限于此。
所述实施例为本发明的优选的实施方式,但本发明并不限于上述实施方式,在不背离本发明的实质内容的情况下,本领域技术人员能够做出的任何显而易见的改进、替换或变型均属于本发明的保护范围。
下面详细介绍基于cwk-means的在线学习资源质量分析方法的技术方案。学习资源质量分析模型图如图2所示,本方法从在线学习平台采集学习者在线学习行为数据。
本发明一种基于cwk-means的在线学习资源质量分析方法,主要包括以下几个步骤:采集数据,特征提取,数据预处理,cwk-means聚类,数据分析,数据可视化。
1)采集数据,构建数据的特征向量;从在线学习平台采集数据,采集的数据包括日志数据和数据库数据,日志数据包括视频学习行为数据、文本学习行为数据和论坛学习行为数据,数据库数据包括测试学习行为数据和反馈数据;其中,视频学习行为数据表示为:
video={slv,pn,pt,an,at,rn,rt},
其中,slv、pn、pt、an、at、rn、rt分别代表学习时长、暂停次数、暂停时长、前进次数、前进时长、后退次数、后退时长;文本学习行为数据表示为:
text={slt,fs,bs,ma,dl,cp,crt},
其中,slt、fs、bs、ma、dl、cp、crt分别代表学习时长、前进滚动、后退滚动、标记、下载、复制、收藏;论坛学习行为数据表示为:
forum={slf,wr,pr,rr,crf}
其中,slf、wr、pr、rr、crf分别代表学习时长、看帖记录、发帖记录、回帖记录、收藏记录;测试学习行为数据表示为:
examinate={sle,es,wq},
其中,sle、es、wq分别代表测试时长、测试成绩、错题;反馈数据表示为:
feedback={ur,fs,ft,fr}
其中,ur、fs、ft、fr分别代表用户、反馈分数、反馈时间和反馈资源;
2)通过数据清洗、数据集成、数据归约和数据变换对数据进行预处理,构建数据集x,表示为x={x1,x2,…,xn},xi表示数据集x中第i个数据对象,每个数据对象包含m个特征,表示为xi={xi1,xi2,…,xim},第i个数据对象的第j个特征属性定义为xij;
3)采用主客观相结合的方法计算各个特征属性的权重,第m个特征xim的权重为
3.1)建立系统的递阶层次结构模型,其中,层次结构模型包括目标层、准则层、方案层,如图3所示;
3.2)根据系统的递阶层次结构模型构造判断矩阵,对同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,引用数字1-9及其倒数作为标度定义判断矩阵a=(aij)m*n;具体方法如下:
特征i与特征j相比较,具有相同重要性取值为1,前者比后者稍重要取值为3,前者比后者明显重要取值为5,前者比后者强烈重要取值为7,前者比后者极端重要取值为9;取值2、4、6、8表示上面相邻判断的中间值;i与j之比为aij则j与i之比为aji=1/aij;
3.3)检验各判断矩阵是否满足一致性要求,如果满足转步骤3.4),否则转步骤3.2),修改判断矩阵,其中,检验各判断矩阵一致性的方法如下:
计算出判断矩阵的最大的特征根λmax,计算一致性指标ci,计算一致性比例cr,当cr<0.10时,满足一致性要求,计算公式如下:
一致性指标:
一致性比例:
其中,ri是同阶随机判断矩阵的一致性指标的平均值,ri的取值如下:
(n,ri)={(1,0),(2,0),(3,0.52),(4,0.89),(5,1.12),(6,1.24),(7,1.36),(8,1.41),(9,1.46)}
3.4)计算主观权重w,公式如下:
aw=λmaxw
3.5)利用资源质量分析结构模型构建原始数列矩阵r,其中,rij表示评价对象i在评价指标j下的评价值,评价对象mi(i=1,2,…,m),评价指标nj(j=1,2,…,n),资源质量分析结构模型如图3所示;
3.6)采用阙值法对原始数列矩阵r无钢化处理,使vij处于0~1之间,使各个指标具有可比性,其中分为两种指标类型:越大越优型指标和越小越优型指标,计算公式如下:
越大越优型指标:
越小越优型指标:
其中,vij表示rij经过无钢化处理之后的数值,max(rj)和min(rj)分别表示第j个指标的最大值和最小值;
3.7)计算第j个指标下第i个对象指标值所占比重pij;
3.8)计算第j个指标的熵值;
3.9)计算出客观权重w;
其中dj为差异系数,dj=1-ej,dj越大表示该指标包含的信息量越大,应该赋予越大的权重;
3.10)使用拉格朗日乘子法组合计算出来的两种权重,得到最终的权重
其中,wi为层次分析法计算出来的权重,wi为熵权法计算出来的权重;
4)利用权重计算初始聚类中心,如图4所示计算方法包括如下步骤:
4.1)计算两两数据对象之间基于权重的欧式距离,任意对象xi,xj(1≤i≠j≤n)之间基于权重的欧式距离公式如下:
其中,
4.2)计算数据集中的数据对象xi(i∈[1,n])对应的距离密度,计算公式如下;
4.3)计算数据集中数据对象xi(i∈[1,n])的邻域半径ri;
其中,cr(cr∈(0,1))为邻域半径调节系数,当cr=0.13时有较好的聚类效果;
4.4)依次计算数据对象xi的点密度d(xi),即以xi为圆心,邻域半径ri为半径的球形域内包含的数据对象个数;
d(xi)=|{p|d(xi,p)≤ri,p∈x}|
4.5)把数据集中的数据对象按照点密度d(xi)降序排放;
4.6)使用分离系数函数确定k的值,分离系数函数表示为:
其中,uij是xi在第j个类中的隶属度,k的最优选择公式为:
其中,ω为所有聚类结果;
4.7)取点密度最大的数据对象作为第一个初始聚类中心c1;
4.8)选择一个和c1距离超过r1的且密度仅次于c1的数据对象作为第二个初始聚类中心;
4.9)判断是否找到k个聚类中心,如果是转步骤5),否则转步骤4.8);
5)利用步骤3)和步骤4)中计算出的权重和初始聚类中心,通过k-means算法对学习资源聚类即cwk-means算法对学习资源聚类,每一个类中在线学习资源质量相似,根据学习者学习过程中的行为,判断学习资源存在的不足,最终每个聚类对应一个质量等级。
- 还没有人留言评论。精彩留言会获得点赞!