一种基于mixup的人脸训练与识别方法与流程
本发明属于人工智能领域,涉及深度学习和人脸识别技术,尤其涉及一种基于mixup的人脸训练与识别方法。
背景技术:
现如今人脸识别技术在移动支付、视频监控等多个领域有了广泛的应用,其中应用的深度学习技术也发展迅猛。为了提高人脸识别的准确率以及速率,当前主要有两个改进方向:(1)从改进神经网络结构入手,如增加网络深度和宽度,修改卷积和池化操作和修改激活函数等;(2)增加训练数据样本。大规模深度神经网络虽然具有强大的性能,但是会损耗巨大的内存,以及对对抗样本的敏感性不好。
并且训练神经网络时,一方面损失函数的erm(经验风险最小化)允许大规模神经网络去记忆(而不是泛化)训练数据。另一方面,神经网络使用erm方法训练后,在训练分布之外的测试样本上验证时会极大地改变预测结果。因此,erm方法已不具有良好的解释和泛化性能。
本发明利用了基于mixup的训练方法能减缓这类问题。mixup规范神经网络,增强了训练样本之间的线性表达。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于mixup的人脸训练与识别方法,减少错误标签的开销,增强对抗样本的鲁棒性,稳定生成对抗网络的训练,最终提高网络训练的准确性,从而提高识别精度。
为达到上述目的,本发明提供如下技术方案:
一种基于mixup的人脸训练与识别方法,包括以下步骤:
s1:网络搭建;
s2:人脸特征分类器的训练:构建虚拟训练样本来训练卷积神经网络;
s3:人脸识别:包括摄像头的图像采集,人脸检测,人脸图像预处理,特征提取,人脸验证判断。
进一步,步骤s2中,构建虚拟训练样本具体为:
其中,xi表示第i个样本图片,yi表示第i个样本图片的标签,
进一步,步骤s2中,所述人脸特征分类器的训练具体包括以下步骤:
s21:将卷积神经网络进行参数权值的初始化;
s22:对输入图片进行mixup操作,假设输入一张图片xi,同时在批训练样本中随机得到另一张图片xj,然后进行混合操作:
s23:输入数据经过卷积层、池化层、全连接层等前向传播得到实际网络输出值y;
s24:将实际网络输出值y与期望输出值
s25:当误差超出允许范围时,将误差传回网络中,利用随机梯度下降法,依次求得全连接层、池化层、卷积层的参数误差,对网络参数进行权值更新,然后在转至步骤s22继续训练;当误差在允许范围内时,结束训练,保存参数。
进一步,步骤s3中,所述人脸识别具体包括以下步骤:
s31:摄像头视频读取:使用摄像头采集图片,将采集到的图片解析,并将其传输到系统中;
s32:人脸检测:对采集的图片进行人脸检测,如果判断有人脸,则转至步骤s33,若没有则继续采集图片;
s33:人脸图片预处理:对步骤s32的采集的人脸图片进行预处理,将人脸图片剪裁为统一大小,为卷积神经网络的特征提取做准备,将其转化为灰度图,是为了减少计算量,人脸对齐;
s34:特征提取:将步骤s33预处理好的人脸图片使用训练好的人脸特征分类器进行特征提取;整个提取过程,使用bp算法的前向计算过程,对比网络的训练,它少了后向梯度更新过程,所以计算量大大减少;
s35:特征验证:将步骤s34中提取的人脸特征向量与存储在人脸特征数据库中的特征向量进行相似度计算,判断人物身份。
进一步,所述步骤s32中,采用机器学习库dlib自带的frontal_face_detector来实现快速人脸检测。
进一步,所述步骤s33中,采用的opencv中自带的对齐算法进行人脸对齐映射。
本发明的有益效果在于:本发明训练的分类器在图片数据集上的卷积神经网络上实现,提高了其表现性能;在光照、背景、表情等干扰下达到的识别精度比现有方法的识别精度更高。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
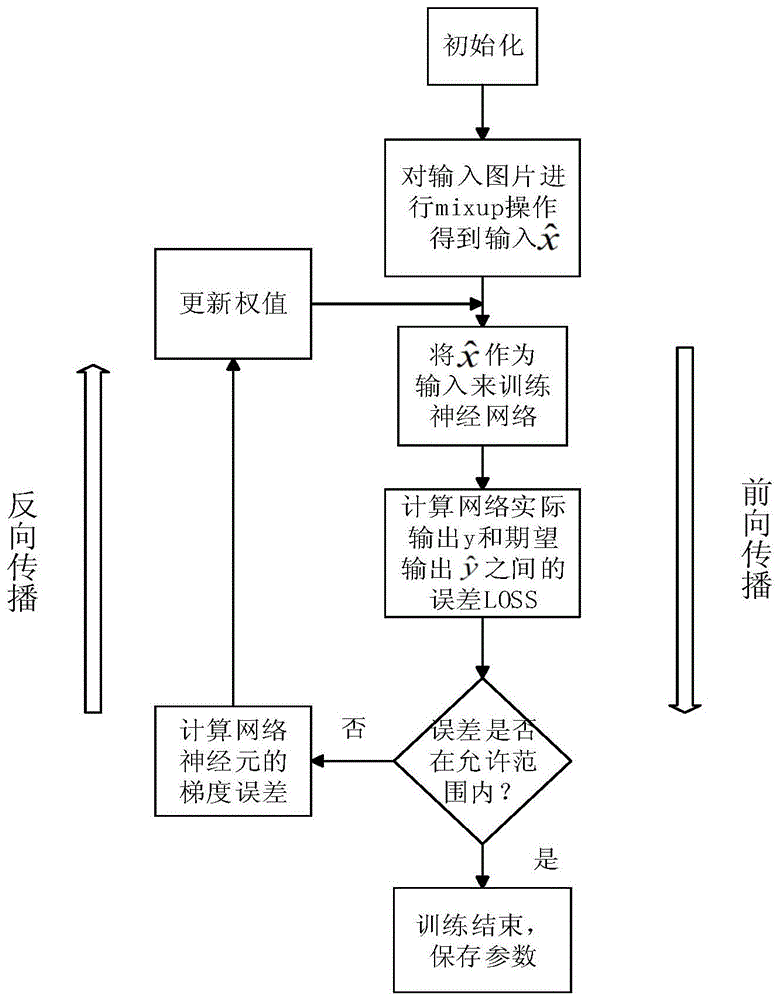
图1为人脸特征分类器的训练流程图;
图2为人脸识别流程图;
图3为神经网络训练时的实际输入效果图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
训练数据集和预处理:本实施例采用casia-webface人脸数据集,包含有黄种人、白种人和黑种人。casia-webface:该数据集是中科院自动化研究所建立的大型人脸图片库,图库包含了10575个人,共有494414张人脸图片,人均图片数量达到了46张。casia-webface人脸库的总量和人数都十分的丰富,在多分类问题上,使用更多的类别数的数据训练可以让网络的泛化能力增强,更好的区分出不同人脸的特征差异,网络的识别精度就会更高。
网络训练中,不直接使用casia-webface人脸库中的图片整张作为输入,而是将处理后的图片进行了局部裁剪,裁剪尺度为64*64,然后对图片中不同部分进行取样,获得更多的实验样本,从而增加样中背景和人脸位置的差异,使得模型对背景的改变和人脸位子的更换变得不敏感,进而提升模型的泛化能力。
本发明所述的一种基于mixup的人脸训练与识别方法,包括以下步骤:
步骤一:搭建resnet-18网络,本发明选用经典的resnet-18结构作为深度学习的神经网络,其包括多个卷积层、池化层、全连接层等和softmax输出层。
步骤二:训练该网络:利用casia-webface人脸数据库并结合mixup数据整合方法训练搭建好的resnet-18神经网络。基于mixup卷积神经网络的人脸特征分类器的训练过程:
mixup从真实样本中构建了虚拟的训练样本:
其中,(xi,yi)和(xj,yj)是从训练样本数据中通过随机抽取而得,且λ~beta(α,α),α∈(0,∞)。因此,mixup是通过结合先验知识,即样本特征向量的线性插值同时应导致相关标签的线性插值,来扩展训练分布。mixup仅需要几行代码即可实现,且花费计算开销较小。mixup超参数α控制了在特征与目标向量之间插值的强度,当α→0时恢复为原始样本输入的规则。
本实施中使用的网络是resnet-18。对于mixup(混合),将α设置为默认值1,表示λ会在0和1之间进行均匀采样;训练200个迭代;学习率为0.1(iter1-100)、0.01(iter101-150)和0.001(iter151-200);批量大小为128。
卷积神经网络的训练过程分为两个阶段。第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段。另外一个阶段是,将当前向传播得出的结果与预期结果进行误差计算(损失函数的计算--loss),将误差从高层次向底层次进行传播训练的阶段,即反向传播阶段。训练过程如图1所示。训练过程为:
1)将卷积神经网络进行参数权值的初始化;
2)对输入图片进行mixup操作,假设输入一张图片xi,同时在批训练样本中随机得到另一张图片xj,然后进行混合操作:
3)输入数据经过卷积层、池化层、全连接层等前向传播得到实际网络输出值y;
4)将实际网络输出值y与期望输出值
5)当误差超出允许范围时,将误差传回网络中,利用随机梯度下降法,依次求得全连接层、池化层、卷积层的参数误差,对网络参数进行权值更新,然后在转至步骤2)继续训练;当误差在允许范围内时,结束训练,保存参数。
步骤三:在线人脸识别流程:系统的人脸识别流程如图2所示,主要包括以下几个模块:摄像头的图像采集,人脸检测,人脸图像预处理,特征提取,人脸验证判断。这些模块按照顺序构成了一个完整的人脸识别流程:
1)摄像头视频读取:使用摄像头采集图片,将采集到的图片解析,并将其传输到系统中;
2)人脸检测:采用的人脸检测器是机器学习库dlib自带的frontal_face_detector来实现快速人脸检测,对采集的图片进行人脸检测,如果判断有人脸,则转至步骤1),若没有则继续采集图片;
3)人脸图片预处理:对步骤2)的采集的人脸图片进行预处理,将人脸图片剪裁为统一大小,为卷积神经网络的特征提取做准备,将其转化为灰度图,是为了减少计算量,人脸对齐采用的是opencv中自带的对齐算法进行人脸对齐映射;
4)特征提取:将步骤3)预处理好的人脸图片使用训练好的人脸特征分类器进行特征提取;整个提取过程,使用bp算法的前向计算过程,对比网络的训练,它少了后向梯度更新过程,所以计算量大大减少;
5)特征验证:将步骤4)中提取的人脸特征向量与存储在人脸特征数据库中的特征向量进行相似度计算(cosino计算相似度),判断人物身份。
如图3所示,假设λ=0.5,按各50%的比例将人脸1和人脸2两张图通过mixup混合到一起,用混合好的样图去训练,最终希望判断结果为50%可能是人脸1以及50%可能是人脸2。
本发明训练的分类器在lfw人脸数据集上验证,在一定程度上提高了识别性能。在光照、背景、表情等干扰下达到的识别精度比当前的方法有了一定的提升。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!