一种基于BiLSTM-CRF的旅游行程路线生成方法与流程
本发明属于智慧旅游智能推荐领域,涉及人工智能算法与行程规划算法,具体来讲是一种基于bilstm-crf(bi-directionallongshort-termmemory-conditionalrandomfields)的旅游行程路线生成方法。
背景技术:
智慧旅游,利用云计算、人工智能等新技术,通过互联网/移动互联网,借助便携的终端上网设备,主动感知旅游资源、旅游经济、旅游活动等方面的信息。在这一领域,面向旅游行程路线智能推荐的解决方案十分稀少,大多数旅游网站、机构仍然停留在人工制定旅游行程的传统方法。该方法成本高昂,无法满足数量庞大的游客旅游出行需求,也与智慧旅游相去甚远。所以更好的制定旅游行程路线方法是利用人工智能技术,通过深度学习建立领域模型,让模型自动学习大量旅游攻略和游记的行程路线,从而自动高效迅速的生成旅游行程路线方案。
技术实现要素:
本发明针对智慧旅游领域在旅游行程路线推荐方面无法提供高效解决方法的问题,公开一种基于bilstm-crf的旅游行程路线生成方法,一种能够从大量旅游攻略和游记中自动识别并生成旅游行程路线的方法。
为实现以上的技术目的,本发明将采取以下的技术方案:
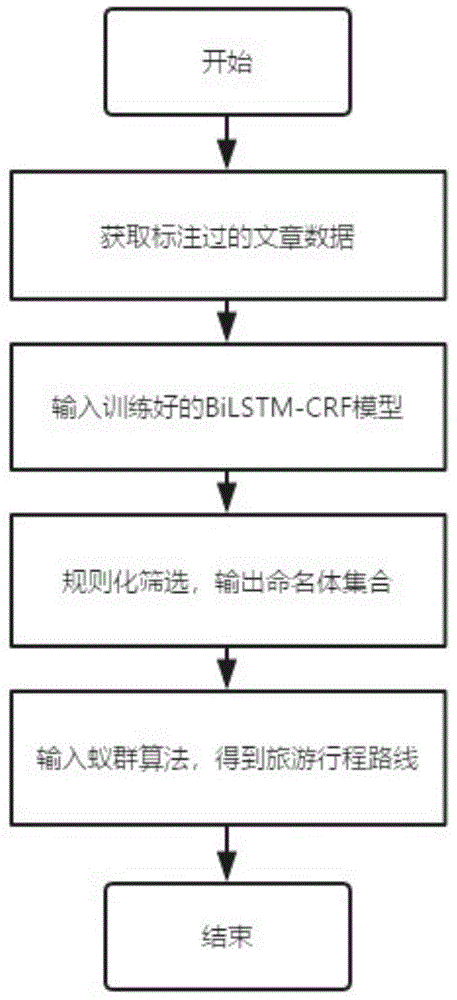
步骤(1)训练bilstm-crf模型;
步骤(2)将文章输入训练好的bilstm-crf模型,输出文章中含有的中文命名体集合(人名、地名和组织机构名);
步骤(3)对模型输出的命名体集合进行规则化筛选,挑选出符合条件的中文景区名称;
步骤(4)将经过筛选的命名体集合,输入到蚁群算法,输出旅游行程路线。
步骤(1)所述的训练bilstm-crf模型,具体实现如下:
1-1.对收集到的文章使用bio标注集,构建字典,构造查找表,构建词嵌入向量,获取数据集。
1-2.构建bilstm循环神经网络框架;
1-3.构建crf条件随机场算法框架;
1-4.计算句子中每个字的所有标签的各自得分,将步骤1-1处理后的数据集输入bilstm循环神经网络,计算出得分;
1-5.将步骤1-4中计算出的每个字的所有标签的各自得分归一化后当作crf模型的发射概率输入crf模型中,计算得出每个字对应的预测标签序列。
1-6.对步骤1-5中求得的标签序列通过viterbi(维特比)算法来解得最优解,计算出最优标签序列。
进一步的,步骤1-1具体为:
将每个元素标注为“b-x”、“i-x”或者“o”。其中,“b-x”表示此元素所在的片段属于x类型并且此元素在此片段的开头;“i-x”表示此元素所在的片段属于x类型并且此元素在此片段的中间位置;“o”表示不属于任何类型。
进一步将bio应用到ner中,即b-per、i-per分别代表人名首字、人名非首字,b-loc、i-loc分别代表地名首字、地名非首字,b-org、i-org分别代表组织机构名首字、组织机构名非首字,o代表该字不属于任何类型。
首先构建字典,将每个句子的每个字按照其在句子中的位置设置编号,记作ni,i表示该字在句子的位置;
接着构建每个字的one-hot矩阵,通过one-hot矩阵表示一个字,one-hot矩阵是指每一行有且只有一个元素为1,其他元素都是0的矩阵。针对字典中的每个字,根据其编号,对某个句子进行编码时,将句子中的每个字转换成字典里面这个字的编号对应的位置为1的one-hot矩阵,如下所示:
接下来,利用预训练或随机初始化的向量矩阵将句子中的每个字由one-hot矩阵映射为低维稠密的字向量(characterembedding)。
进一步的,步骤1-2中:
将前向的lstm与后向的lstm结合成bilstm,可以更好的捕捉双向的语义依赖,其中lstm的计算过程如下:
(1)计算遗忘门f,选择要遗忘的信息:
ft=σ(wf·[ht-1,xt]+bf)
(2)计算记忆门的值it,选择要记忆的信息:
it=σ(wi·[ht-1,xt]+bi)
(3)计算当前时刻细胞状态:
(4)计算输出门的值ot和当前时刻隐层状态ht:
ot=σ(wo·[ht-1,xt]+bo)
ht=ot*tanh(ct)
最终得到与句子长度相同的隐层状态序列。
其中,参数t表示计算过程中的时刻,ht-1为前一时刻的隐层状态,xt为当前时刻的输入词,ft为遗忘门的值,w表示权重矩阵,b表示偏置值,是sigmoid函数,下标f表示遗忘门本身,下标i表示输入门本身,下标c表示临时细胞状态本身,下标o表示输出门本身;
进一步的,步骤1-3中:
选择线性链条件随机场作为标注模型,即在给定随机变量序列x的条件下,随机变量序列y的条件概率分布为p(y|x)构成条件随机场,且满足马尔可夫性。
进一步的,在随机变量x取值为x的条件下,随机变量y取值为y的条件概率具有如下形式:
其中:
式中,tk和sl是特征函数,λk和μl是对应的权值;z(x)是规范化因子,求和是在所有可能的输出序列上进行的;其中下标k表示边,下标l表示结点,下标i表示y的取值可能。
进一步的,条件随机场的学习算法,通过给定训练数据集估计条件随机场模型参数,采用极大似然估计法计算权重参数,训练数据的对数似然函数为:
其中,
进一步的,步骤1-6中的viterbi算法公式为:
其中x为观察序列(也称输入序列,即步骤1-5中求得的标签序列),y为标记序列(也称输出序列,即最终所求的最优序列)。
进一步的,步骤(3)所述的对模型输出的包含文章命名体的最优序列,将其对照事先准备好的字典(字典为一系列命名体集合)进行筛选,即剔除序列中所有不包含在字典内的命名体,只留下实际需要的景区或地名等。
进一步的,步骤(4)所述的对经过筛选的景区或地名,根据各景点之间的实际距离,利用蚁群算法计算出最优路径(即各景点走一遍后回到原点所走过的长度最短),即最终的旅游行程路线方案,具体实现方法如下:
4-1.初始化存储信息素表,已走过景点表,未走过景点表,定义固定数量的蚂蚁,其中蚂蚁每经过一个景点就会释放信息素。
4-2.通过计算转移概率,为每只蚂蚁选择下一个节点(景点),该公式如下:
其中,
4-3.当所有蚂蚁完成一次循环计算后,更新各路径上的信息素,具体计算方式如下:
τij(t+n)=ρ·τij(t)+δτij
其中,τij(t+n)为t+n时刻景点i与j之间的信息浓度,ρ为控制参数,q为正常数,lk为蚂蚁k在本次行走中所走过的路径的长度。
4-4.设置算法迭代次数为140次,当迭代次数达到最大迭代次数时,算法终止,跳到步骤4-5;否则,重复执行步骤4-2、4-3、4-4直到迭代结束;
4-5.输出计算结果,即最优路径(最优旅游行程路线)。
本发明由于采取以上技术方案,具有如下优点:
本发明利用前后向循环神经网络结合条件随机场实现对文章的命名体识别,随后再利用蚁群算法实现路径规划,最终输出合理可解释的旅游行程路线方案,这种方法能有效结合智慧旅游概念,充分利用海量的旅游资源,形成个性化推荐旅游行程方案,满足广大游客的需求。
附图说明
图1是本发明的整体实施方案流程图;
图2是本发明的训练模型示意图;
图3是本发明工艺实施方案的具体流程图;
具体实施方式
附图非限制性的公开了本发明所涉及优选实施例的流程示意图;以下将结合附图详细的说明本发明的技术方案。
一种基于bilstm-crf的旅游行程路线生成方法,其基本步骤如下:
训练bilstm-crf模型;
将文章输入训练好的bilstm-crf模型,输出文章中含有的中文命名体(人名、地名和组织机构名);
对模型输出的命名体进行规则化筛选,挑选出符合条件的中文地名,中文景区名称;
对经过筛选的结果使用蚁群算法计算行程路线,输出行程方案。
其中训练训练bilstm-crf模型的步骤如下:
从网络上采集所需旅游攻略游记,以篇为单位,做好前期标注工作,并将所有数据集分为两部分,一部分作为训练集,一部分作为测试集。
取训练集中的文章,对文章的每个字构造词嵌入向量,构造查找表。接着将词嵌入向量输入bilstm网络,计算出每个字的对应各个类别的分数,全部字的类别分数构成一个矩阵。
将上述字的类别分数矩阵输入crf模型,输出每个字或词的预测标签,最终通过维特比算法求出最优解,此时得到的是一个包含文章所有命名体的结果。
通过上述步骤可以训练出bilstm-crf模型。
本发明详细流程如图1和图3。其中具体的bilstm-crf模型模型如图2。
实施例:
从网络上采集所需旅游攻略游记,以篇为单位,做好前期标注工作,具体例子如下:
小(b-per)明(i-per)在(o)希(b-org)望(i-org)小(i-org)学(i-org)读(o)书(o)
并将所有数据集分为两部分,一部分作为训练集,一部分作为测试集。取训练集中的文章,以句子为单位,构造词嵌入向量,构造查找表。
如图1,将词嵌入向量输入bilstm网络,计算出每个字的对应各个类别的分数,全部字的类别分数构成一个矩阵,具体实现步骤如下:
将一个句子的各个字的词嵌入向量序列作为双向lstm各个步的输入,再将正向lstm的输出的隐状态序列与反向lstm的隐状态序列在各个位置输出的隐状态序列进行拼接,得到完整的隐状态序列;
最后将隐状态序列依照标签数变换成字的类别标签分数矩阵。
如图3,将上述字的类别标签分数矩阵输入crf模型,输出每个字或词的预测标签,最终通过维特比算法求出最优解,此时得到的是一个包含文章所有命名体的结果;
为上述步骤设置1000次左右的迭代训练次数,次数过多会发生过拟合,期望测试结果是识别效果达到百分之八十以上。
将上述所得的命名体集合通过字典进行规则化筛选,筛除部分不符合要求的命名体;接着对经过筛选后的命名体集合,利用蚁群算法求解出基于距离长短的最优路径,最终输出合理的旅游行程路线方案。
- 还没有人留言评论。精彩留言会获得点赞!