一种基于部件模型表达的工件位姿估计方法与流程
本发明涉及计算机视觉领域,具体涉及一种基于部件模型表达的工件位姿估计方法。
背景技术:
在实际应用中,获取目标物体的三维信息是非常关键的。例如,在机械臂抓取操作任务中,识别物体6d位姿(三维定位和三维方向),为抓取和运动规划提供了有用的信息。对于工件进行位姿估计的难点在于工件属于弱纹理物体,易受到光照、反射情况的影响,使得从2d图像中反映出来的纹理不一定是3d物体表面真实的纹理。而且当图像的分辨率变化的时候,所计算出来的纹理可能会有较大偏差,特征提取算法不容易识别。在位姿估计实际过程中还存在遮挡,多目标等复杂场景的客观因素影响。
现有的6d位姿估计问题是通过将从图像中提取的局部特征与物体三维模型中的特征进行匹配来解决的。利用二维与三维对应关系,可以恢复物体的6d位姿。但是这些按方法不能很好的处理无纹理对象,因为只能提取很少的局部特征。为了处理无纹理物体,有两类方法,第一类方法是估计输入图像中物体像素或关键点的三维模型坐标。这样就建立了二维与三维的对应关系,从而可以进行6d位姿估计。第二类方法通过对位姿空间离散化,将6d位姿估计问题转化为位姿分类问题或位姿回归问题。这些方法能够处理无纹理的物体,但不能实现高精度的位姿估计,分类或回归阶段的小误差直接导致位姿不匹配。
此外,传统的可变形部件模型采用的是基于滑动窗口的检测方式,检测过程中利用一个较为粗糙的,覆盖整个目标的根模板遍历图像中所有位置进行模型匹配,然后通过几个高分辨率的部件模板计算对应空间位置得分的最大值,再根据部件模板相对于根模板的空间位置变形花费以确定检测目标。目前,可变形部件模型算法仅用来目标检测,没有充分利用部件表达的信息,并且没有将学习的特性运用在模板当中。在工件姿态估计中,存在部件信息所占整体比例较小,但对于位姿估计准确度有相当大的影响并可抑制整体位姿估计所导致的位姿不匹配问题。
技术实现要素:
本发明所要解决的技术问题是提供一种基于部件模型表达的工件位姿估计方法,解决现有方法无法较好处理工件等弱纹理物体,无法精确对工件进行位姿估计,并且适应性不高的问题。
为解决上述技术问题,本发明采用的技术方案是:
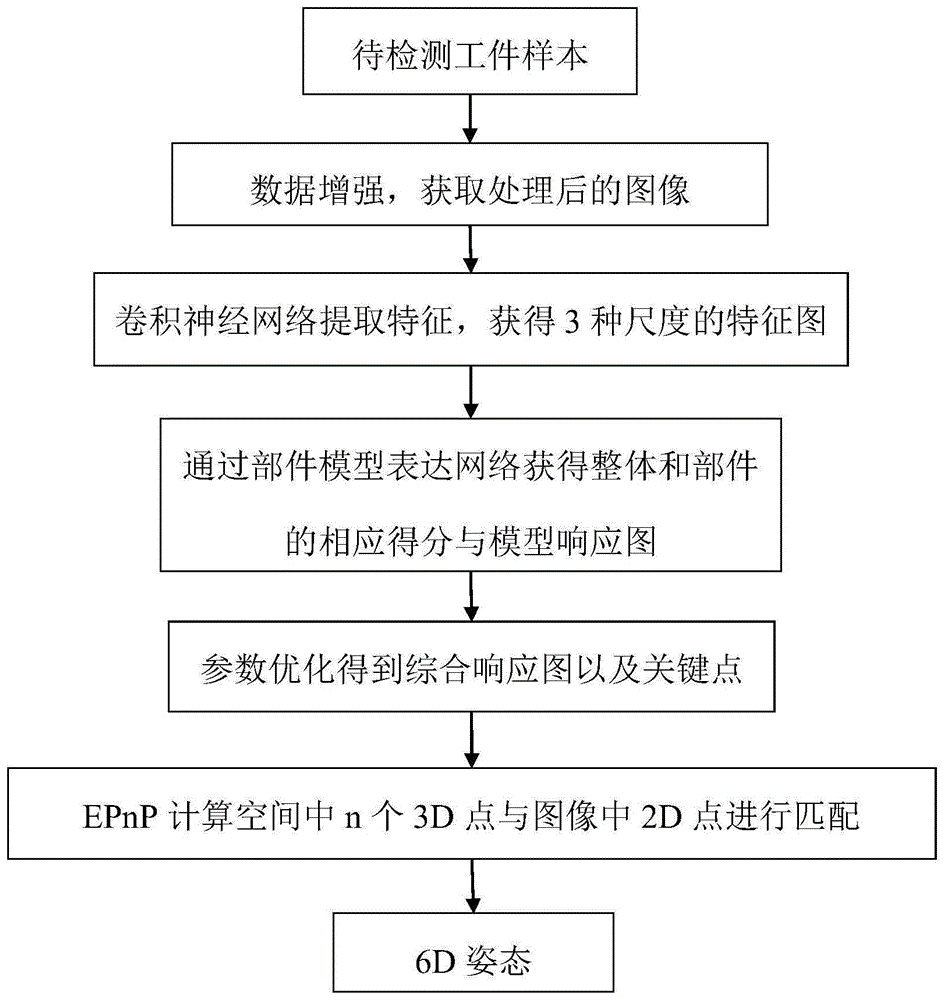
一种基于部件模型表达的工件位姿估计方法,包括以下步骤:
步骤1:对待检测数据进行数据增强,将图像进行随机裁剪、缩放、旋转操作后重置图片尺寸,保持与原图大小分辨率相同;
步骤2:通过卷积神经网络对图像进行特征提取,获得13×13,26×26,52×52三种尺度的特征图;
步骤3:将每个特征图通过部件模型表达网络结构,获得整体和部件的相应得分与模型响应图;
步骤4:将所有模型响应图经过参数优化得到综合响应图以及关键点;
步骤5:通过epnp算法计算空间中n个3d点与图像中2d点进行匹配,进而得到相机对应位姿。
进一步的,所述步骤2具体为:
卷积神经网络共包含三个混合空洞稠密块,每个稠密块里面的层数相同;在稠密块中,采用空洞卷积的方式,默认参数rate=1,2,5,当工件直径小于等于70mm时,选择rate=1,2,当工件直径大于70mm时,选择rate=1,2,5,保证各个层的特征图大小一致,在通道维度上直接连接;
稠密块中的非线性组合函数采用组合批归一化,relu激活函数,3×3的卷积的结构;所有稠密块中各个层卷积之后均输出h个特征图,即得到的特征图的通道数为h,h在该网络结构为一个超参数;通过三个模块的特征图大小分别为32×32,16×16,8×8;在该卷积神经网络中,所有的3×3卷积均采用步长为1,填充为1的方式以保证特征图大小维持不变;该卷积神经网络使用如下网络配置:{ls=190,h=12,rate=1,2,5},ls为层数。
进一步的,所述步骤3具体为:
采用部件模型表达结构对每个类别c,视野v构建一个根模板卷积核
其中,一个根模板卷积核对应o个部件模板卷积核;φa(xs)表示图片xs的特征图,所得表达得分为:
部件模型表达网络结构通过计算表达得分和根模板卷积核、部件模板卷积核在空间中关系的变形花费找到最优的部件位置;其中表达分数为
等式中的最大值对应每个独立的输出空间位置;对于每一个输出位置,均能够找到最大可能的形变(δi,δj);在训练过程,约束搜索窗口[-s,s]×[-s,s],其中s是在特征空间中部件的大小;通过训练,在每一次输出位置找到最优的
进一步的,所述步骤4具体为:
设定变量
工件物体的类别用
通过部件模型表达网络,对目标工件的利用公式得到最终响应,并根据部件的所占权重,优化整体3d边界框即整体的8个关键点:
在训练过程中,部件表达模型的损失函数为:
上式中,λpt、λclass、λag分别表示关键点、分类、角度损失函数的系数;xi,yi,p(ci),vi分别为预测关键点在二维图像中的坐标、类别概率以及视角角度,
进一步的,所述步骤5具体为:
通过步骤4得到工件表面的n+8×part个关键点,考虑到效率与精度取优化后的整体的3d边界框组成的8个关键点;取{ui}i=1,…,n是参考点{pi}i=1,…,n的2d投影,控制点在世界坐标系中的坐标为
根据投影方程得到世界坐标系中参考点坐标和相机坐标系中参考点的约束关系,对于
得线性方程组mx=0,其中
进一步的,还包括步骤6:对位姿估计精度进行评价,设位姿标签为pose=[r|t],预测位姿为
与现有技术相比,本发明的有益效果是:采用部件模型表达的思想,将传统的可变形部件模型算法通过深度学习进行优化特征选取,将每个部件的信息都作为一定的权重来优化整体的3d边界框和关键点;同时,通过隐式获取工件的部件信息,只需工件整体的标签即可获取部件信息,将部件所占整体比例较小但对于位姿估计准确影响较大的部件进行有效的表达,从而使得工件姿态估计有着快速而高效的性能,能实时、精确地计算工件6d位姿。
附图说明
图1为本发明的流程示意图;
图2为网络结构特征提取的示意图;
图3为模板卷积核学习过程的示意图;
图4为部件模型卷积核形变示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明可以在windows和linux平台上实现,编程语言也是可以选择的,可以采用python实现。
如图1所示,本发明一种基于部件模型表达的工件位姿估计方法,包括以下步骤:
步骤1:对待检测数据进行数据增强,将图像进行随机裁剪、缩放、旋转操作后重置图像尺寸,保持与原图大小分辨率相同;
步骤2:通过卷积神经网络对图像进行特征提取,获得3个尺度的特征图;
步骤3:将每个特征图通过部件模型表达网络结构,获得整体和部件的相应得分与模型响应图;
步骤4:将所有模型响应图经过参数优化得到综合响应图以及关键点;
步骤5:通过epnp算法计算空间中n个3d点与图像中2d点进行匹配,进而得到相机对应位姿。
所述步骤1可采用以下方式:
对工件cad模型(或包含点云的模型)进行渲染,在方位角区间为[0,2π],高度角区间为[-0.5π,0.5π],半径以毫米为单位在[50,100,150,200]这4个范围内进行采样。将图片进行随机裁剪、缩放、旋转等操作后重置图片尺寸,保持与原图大小分辨率相同。
如图2所示,所述步骤2可采用以下方式:
采用卷积神经网络,将所有卷积层相互连接。每个层都会接受其前面所有层作为其额外的输入。即每个层都会与前面所有层在通道维度上连接在一起,并作为下一层的输入。对于一个ls层的网络,该网络共包含
如图4所示,所述步骤3可采用以下实现方式:
采用部件模型表达结构对每个类别c,视野v构建一个根滤波器
部件模型表达网络结构通过计算表达得分和根模板卷积核、部件模板卷积核在空间中关系的变形花费找到最优的部件位置;其中表达分数为
等式中的最大值对应每个独立的输出空间位置。对于每一个输出位置,均可找到最大可能的形变(δi,δj)。在训练过程,约束搜索窗口[-s,s]×[-s,s],其中s是在特征空间中部件的大小。通过训练,在每一次输出位置找到最优的
所述步骤4可采用以下实现方式:
设定用变量
在训练过程中,部件表达模型的损失函数为:
上式中,λpt、λclass、λag分别表示关键点、分类、角度损失函数的系数,在训练初期,分别设置为0.5,0.3,0.5,经过5个epoch后分别设置为0.8,0.7,0.9.以保证网络在初期主要学习对关键点和角度的学习。xi,yi,p(ci),vi分别为预测关键点在二维图像中的坐标,类别概率以及视角角度,
所述步骤5可以采用以下实现方式:
通过步骤4可得工件表面的n+8×part个关键点,考虑到效率与精度取优化后的整体的3d边界框组成的8个关键点。取设{ui}i=1,…,n是参考点{pi}i=1,…,n的2d投影,控制点在世界坐标系中的坐标为
根据投影方程得到世界坐标系中参考点坐标和相机坐标系中参考点的约束关系,对于
因此可得线性方程组mx=0,其中
- 还没有人留言评论。精彩留言会获得点赞!