一种基于知识图谱向量化推理通用软件缺陷建模方法与流程
本发明软件安全
技术领域:
,特别是涉及一种基于知识图谱向量化推理通用软件缺陷。
背景技术:
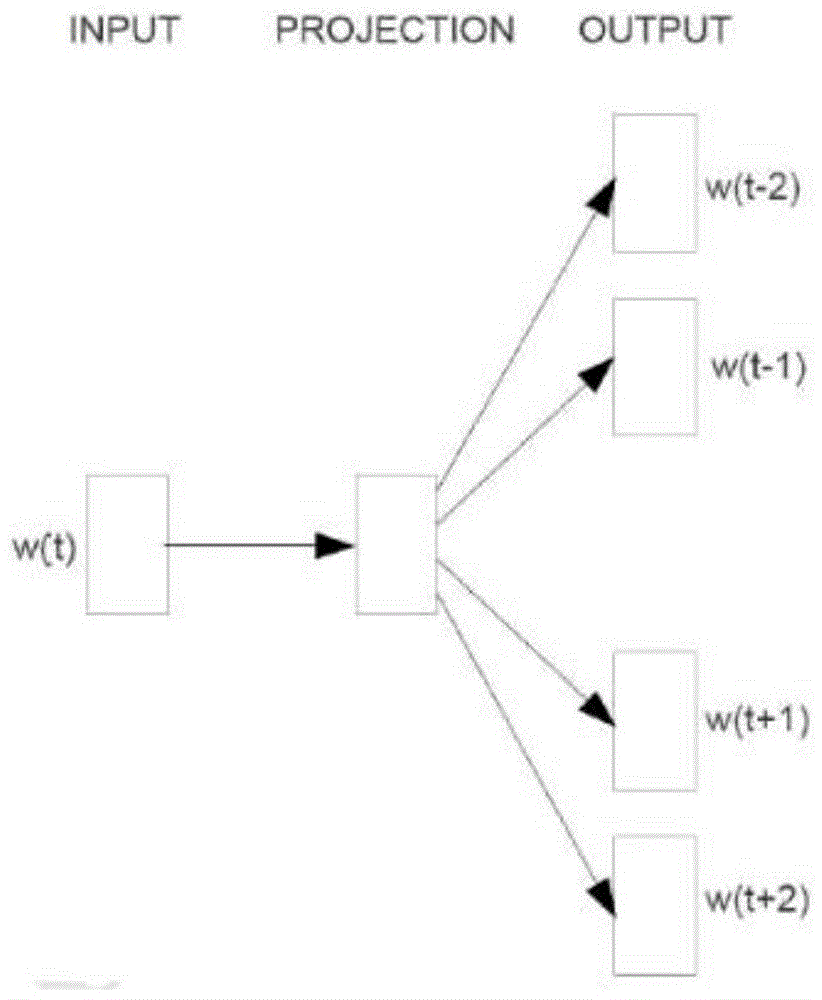
:安全对于一个软件产品来说是至关重要的,随着人们对电子产品的需求量不断增加、对实现复杂功能的软件产品的持续青睐,开发商为了满足市场需求不断地缩减开发周期,对软件开发之前的安全调研也未能顾全整个软件开发周期,如此,在进入软件开发阶段,开发人员按照设计所实现的软件便有极大的可能性带有缺陷,软件缺陷虽然不能直接对用户体验带来极大不适,也不会直接危害用户的信息与财产安全,但却隐藏着巨大的弊端,若是被黑客或者拥有特定技术的人发现软件所存在的缺陷,他们便可以对缺陷进行攻击,攻击成功缺陷便会变成漏洞,这必将会对使用者的个人信息造成泄露,更危险的是用户的银行卡信息被窃取,造成不必要的财产损失。因此,软件缺陷对于软件产品来说是致命的。软件缺陷(defect),即为计算机软件或程序中存在的某种破坏正常运行能力的问题、错误,或者隐藏的功能缺陷。缺陷的存在会导致软件产品在某种程度上不能满足用户的需要。ieee729-1983对缺陷有一个标准的定义:从产品内部看,缺陷是软件产品开发或维护过程中存在的错误、毛病等各种问题;从产品外部看,缺陷是系统所需要实现的某种功能的失效或违背。在软件开发生命周期的后期,修复检测到的软件错误的成本较高。那么准确有效的定义和描述软件缺陷,可以使软件缺陷得以快速修复,节约了软件测试项目的成本和资源,提高产品质量。通用缺陷枚举(commonweaknessenumeration)是一个软件社区项目,虽然cwe缺陷包含了很多的信息,比如缺陷描述、缺陷之间的关系、缺陷产生的结果等,但是cwe是超文本文件,不能支持先进的推理任务,比如关系预测、多标签预测、三元组的分类等任务,本发明设计的模型可以高效的完成这些任务,并且还可以结果zero-shot问题。技术实现要素:本发明旨在提出一种基于知识图谱向量化推理通用软件缺陷建模方法,利用将知识图中基于描述的知识和基于结构的知识相结合、将cwe和cwe关系嵌入到低维向量空间中,实现了软件缺陷模型transcat的构建。本发明的一种基于知识图谱向量化推理通用软件缺陷建模方法,包括以下流程:步骤1、数据获取与预处理,具体操作为:从数据源获得所有关于缺陷的数据,该缺陷数据至少包括缺陷id、缺陷描述、不同缺陷之间的关系以及缺陷造成的结果,对不同缺陷之间的关系和描述信息进行预处理;步骤2、学习基于描述的表示,具体操作为:通过大量的缺陷数据获得向量化模型,创建lookup字典包含所有缺陷的单词的向量化表示,构成了单词层次上的向量化,描述每一个句子的语义,获得句子层面的向量化,即对于具有n个单词的句子的向量化表示通过取n个单词的表示向量的平均值,从而构建基于描述的表示ed,ed是指实体的文本表示,表达式为:ed=||hd+r-td||,其中,hd、td分别表示头实体和尾实体的文本表示;步骤3、学习基于结构的表示,具体操作为:针对一个给定的缺陷实体三元组(h,r,t)∈t,其中h,t∈v,h,t表示头部实体和尾部实体,v表示头部实体和尾部实体的集合;r∈r,r表示关系,r表示关系的集合;t表示所有三元组的集合,构建基于描述的表示es,es是指实体的结构表示,表达式为es=||hs+r-ts||,而hs和ts分别表示头实体与尾实体的结构表示;步骤4、通过基于结构的表示es和基于描述的表示ed,构建最终的软件缺陷模型transcat模型:步骤5、进行transcat模型优化处理,优化目标是最小化的基于奖励的损失函数,最小化的基于奖励的损失函数的表达式如下:其中,γ表示奖励超参数,e(h,r,t)表示能源函数,t′表示t的负样本集合,即h′+r≠t′,h′和t′同样表示头部实体和尾部实体,并且t'的表达式如下:t'={(h',r,t)|h'∈e}∪{(h,r,t')|t'∈e}(5)利用adam优化算法去优化transcat模型的损失函数,具体的优化算法过程如下:(1)首先对关系的集合r中的每一个关系r,进行uniform函数转换确定其均匀分布的均匀标准在[-1,1]之间,本模型中维度k=36;(2)对关系所表示的向量进行归一化处理||r||是向量的模运算;(3)对于实体集e中的每一个实体e,对其进行uniform函数转换确定其均匀分布的均匀标准在[-1,1]之间;(4)对实体集合中的每一个集合e进行如下操作:(5)对e进行归一化(6)让实体e所表示的向量与基于描述所表示的向量连接形成维度加倍的向量;(7)从训练集中的三元组初始化一个minibatchtbatch←φ,并与负样本的三元组做并操作tbatch←tbatch∪{((h,r,t),(h',r,t'))},其中φ表示训练集合;(8)通过minibatch训练更新参数,进而提高向量化的表示;(9)不断修改损失函数的值;(10)最终得到transcat模型(knowledgegraphembeddingmodel)。与现有技术相比,本发明实现的transcat模型可以捕获关于常见软件弱点的文本和结构性知识,从而有效地支持软件弱点上的各种推理任务。附图说明图1为本发明的word2vec之skip-gram模型示意图;图2为transcat模型示意图;图3为baseline模型示意图,(a)baseline1示意图、(b)baseline2示意图、(c)baseline3示意图;图4为本发明的基于知识图谱向量化推理通用软件缺陷建模方法整体流程示意图。具体实施方式本发明的基于知识图谱向量化推理通用软件缺陷模型(transcat模型)是基于transe的连接模型,该模型从知识图谱中既学习基于结构的表示也学习基于描述的表示,通俗的讲,该模型不但可以获得结构信息也可以获得语义信息。通过transe方法学习基于结构的表示,得到transe模型的energy函数表示为:es=||hs+r-ts||,其中下标s表示structure;对于向量化cwe中的缺陷描述,首先通过可以捕获语义和语法的wordembedding去学习单词的表示,而训练wordembedding的语料库是爬取到的所有文本信息,包括cwe描述以及示例;然后使用连续的skip-gram模型进行词向量转化,得到的输出结果是一个单词向量的字典,这个字典包含cwe描述的每一个单词,之后便可以学习到单词的向量表示。而为了表示cwe描述还需要捕获句子的表示,采用每一个cwe描述的所有单词的向量化后的向量的平均向量作为每一个cwe句子的表示。它的energy函数表示为:ed=||hd+r-td||,下标d表示description。基于结构的表示和基于描述的表示在利用平移的方法被训练得到transcat的energy函数被表示为:transcat模型进行知识图谱向量化的目标也是为了提高向量化的效果,但是却在基于结构的基础上增加了基于描述的表示,更有利于向量化表示的效果。经过transcat模型的训练阶段,已经获得了transcat模型,之后需要对模型的超参数进行调优,得到更加稳定的模型,之后利用该模型进行推理任务,如不同cwe之间的关系预测、知识图谱三元组的分类、以及对cwe中的commonconsequence进行预测。transcat模型进行知识图谱向量化的目标也是为了提高向量化的效果,但是却在基于结构的基础上增加了基于描述的表示,更有利于向量化表示的效果。下面结合附图和实施例对本发明技术方案进行详细描述。如图4所示为本发明的基于知识图谱向量化推理通用软件缺陷建模方法整体流程示意图。本发明的transcat模型既考虑了实体结构信息也获得了实体描述的语义信息,可以更加准确的完成缺陷之间的推理任务。分别以三种基本方法即关系预测法、三元组分类法和结果预测法作对比实验,transcat模型性能比这三种方法更好,训练transcat模型用到的技术方案如下:步骤1、数据获取与预处理,具体为:通过数据爬取方法从数据源(https://cwe.mitre.org/)获得所有的(总共包括705个缺陷)缺陷描述数据,该缺陷描述数据至少包括缺陷的id、描述、关系以及缺陷造成的结果;然后预处理不同缺陷之间的关系,将cwe缺陷之间的关系总结为四种:父子关系(parent-child)、先后关系(precede-follow)、兄弟关系(peerof)和语义关系(semanticallyrelated),其中parent-child关系是由“childof”和“parentof”两种不同的关系合并获得的,而precede-follow关系是由“canprecede”和“canfollow”两种不同的关系合并获得的。对于cwe的描述信息也要进行预处理,具体为将特殊符号(如:*,#,@)以及数字去掉。其中标识符(id)用于每一个缺陷的辨别;描述是对每一个缺陷的文本描述;缺陷之间的关系总结为四类:父子关系、先后关系、兄弟关系以及语义关系;缺陷造成的结果是不同缺陷所造成的负面技术影响(共分为8个类别)。数据爬取方法主要包括wordembedding(词向量)、word2vec和knowledgegraph(知识图谱)。步骤2、学习基于描述的表示,具体为:先训练一个向量化模型,这个过程使用到的工具是word2vec中向量化的模型即skip-gram模型,用一个词语作为输入来预测它周围的上下文。假设存在一个w1,w2,w3,…,wt的词组序列,skip-gram的目标函数是为了最大化在中心词wt周边上下文wt+j的概率,该目标函数使用下面表达式进行表示:其中,t表示单词序列的长度,c表示单个方向的窗口大小,2c+1表示上下文窗口的大小,j用来确定目标单词的上下文单词位置。因此条件概率p(wt+j|wt)被定义如下:可见skip-gram是一个对称的模型,如果wt为中心词时,wk在其上下文窗口内,则wt也必然在以wk为中心词的同样大小的上下文窗口内。同时,skip-gram中的每个词向量表征了上下文的分布。skip-gram中的skip是指在一定上下文窗口内的词两两都会计算概率,就算它们之间隔着一些词,这样的好处是“白色汽车”和“白色的汽车”很容易被识别为相同的短语。前面提到的条件概率p(wt+j|wt)其实是一个多分类的逻辑回归,即softmax模型,对应的label是one-hotrepresentation,只有当前词对应的位置为1,其他为0。如图3所示,可以看出skip-gram预测概率p(wi|wt),其中i用来表示当前单词的上下文单词,具体范围为:t-c≤i≤t+c且i≠t,c是决定上下文窗口大小的常数,c越大则需要考虑的pair(当前单词与一个上下文单词是一个pair)就越多,一般能够带来更准确的结果,但是训练时间也会增加。现在用于向量化的工具已经确定,但是对缺陷的描述进行向量化,首先需要通过大量的数据来获得向量化模型,数据是步骤1中所有爬取到的文本信息,以此来创建的lookup字典包含了所有缺陷的单词的向量化表示,因此,每一个缺陷描述的单词都可以在字典中找到与之对应的向量化表示,这是单词层次上的向量化,本步骤的目的是描述每一个句子的语义,因此需要获得句子层面的向量化,采取的办法是:对于具有n个单词的句子的向量化表示通过取n个单词的表示向量的平均值;最后用ed表示基于描述的表示。步骤3、学习基于结构的表示:学习基于结构的表示的目标是为了将cwe的所有实体和cwe实体间的关系编码到一个连续的低维向量空间中,采用了transe模型。transe是知识图谱向量化的一个基本模型也是本专利的基础模型,transe将头部实体与尾部实体的关系解释为平移操作在一个低维的向量空间中。它的energy函数被写为e(h,r,t)=||h+r-t||,表示尾部实体所表示的向量应该是最接近头部实体与r的向量和。transe模型进行知识图谱向量化的目标是通过训练集中的三元组集合来最小化e,进而提高向量化表示的效果。本步骤中,知识图谱向量化的实体维度与单词向量化的维度相同,缺陷之间的关系所表示的维度是前者的两倍。对一个给定的cwe三元组(h,r,t)∈t,其中h,t∈v,h,t表示头部实体和尾部实体,v表示头部实体和尾部实体的集合;r∈r,r表示关系,r表示关系的集合;t表示所有三元组的集合。transe的energy函数被定义如下:e(h,r,t)=||h+r-t||(3)这个模型的一般概念是被r标记的边引起的功能性函数关系对应于向量化的平移,即h+r≈t。几何解释是尾部矢量t应该是矢量h+r相加的最近邻。步骤4、通过基于结构的表示es和基于描述的表示ed,构建最终的软件缺陷模型transcat模型:步骤5、transcat模型优化处理,优化目标是得到最小化的基于奖励的损失函数:最小化的基于奖励的损失函数的表达式如下:其中,γ表示奖励超参数,e(h,r,t)表示能源函数,t'表示t的负样本集合,即h′+r≠t′,h′和t′同样表示头部实体和尾部实体。并且t'的表达式如下:t'={(h',r,t)|h'∈e}∪{(h',r,t')|t'∈e}(5)从公式(5)可以看出头部实体和尾部实体被随机的用另一个cwe实体替换,但不是同时被替换。公式(4)是一个经典的损失函数,它要求正样本的能源函数值与负样本的能源函数值之间的差距不应该超过参数γ。即,希望正样本分数越高越好,负样本分数越低越好,但二者得分之差最多到γ就足够了,差距增大并不会有任何奖励。最后,利用adam优化算法去优化transcat模型的损失函数,使其向量化效果更好。具体的优化算法过程详细介绍如下:(1)首先对关系的集合r中的每一个关系r,进行uniform函数转换确定其均匀分布的均匀标准在[-1,1]之间,本模型中维度k=36;(2)对关系所表示的向量进行归一化处理||r||是向量的模运算;(3)对于实体集e中的每一个实体e,对其进行uniform函数转换确定其均匀分布的均匀标准在[-1,1]之间;(4)对实体集合中的每一个集合e进行如下操作:(5)对e进行归一化(6)让实体e所表示的向量与基于描述所表示的向量连接形成维度加倍的向量;(7)从训练集中的三元组初始化一个minibatchtbatch←φ,并与负样本的三元组做并操作tbatch←tbatch∪{((h,r,t),(h',r,t'))},其中φ表示训练集合;(8)通过minibatch训练更新参数,进而提高向量化的表示;(9)不断修改损失函数的值;(10)最终得到transcat模型(knowledgegraphembeddingmodel)。整个过程中4个超参数的优化问题,以关系预测任务作为调节超参数的标准,关系预测指的是对三元组中头部实体/关系/尾部实体去掉后以此用数据集中的实体来替换形成待评价的三元组,对构造出来的三元组使用损失函数进行计算相似度,以相似度来对所有替换进去的实体/关系进行排序,相似度越高排名越靠前,找到正确的实体/关系在所有三元组的排名,以正确的实体/关系排名进1%的比例(hits@1(%))来评估参数,hits@1(%)越高,性能越好。四个超参数分别是embeddingdimension(词向量的维度)、γsize(奖励超参数)、batchsize(批处理的大小)、thenumberoftrainingiterations(训练的次数)。thenumberoftrainingiterations参数对训练集的迭代次数调优,当迭代次数是150时,损失函数值很小,时间花费400秒,当迭代次数在增加时,损失函数的值基本不在减小,但是时间持续增加,因此选择迭代次数为150。其余几个参数在上述过程中已经有所提到,这里只列出调优效果表如表1所示:表1batchsizehits@1(%)γsizehits@1(%)embeddingdimensionhits@1(%)160.8532.00.811320.832320.8245.00.853640.853640.8298.00.8241280.826至此,超参数调优过程结束,结果也是显而易见。下面通过三个实验来验证transcat模型的性能,作为对比的方法分别是wordembedding+svm(方法1)、transe(onlystructure)(方法2)、transe(structure+description)(方法3)。方法1仅提取语音信息,之后使用svm分类器进行分类,因此这种方法只能进行关系预测;方法2是传统的transe方法,仅仅提取cwe实体与cwe实体间关系的结构信息;方法3将结构信息和语义信息添加在一起是并列的关系,而本发明的模型是将其连接在一起形成新的向量。对比试验1:cwe关系预测评估模型好坏的依据按照meanrank和hits的值。meanrank表示正确实体/关系平均排名,hits表示正确实体/关系排名的比例,在这里采用排名进入1%来评判,即hits@1(%),结果如下:表2从表1中可以看出,与三种基线方法相比,本发明的transcat在两种评估指标上都达到了最佳性能。本发明方法的hits@1(%)分别比对比方法1,对比方法2和对比方法3分别高出7%,23%和9.1%。因为对比方法1是一个分类,而不是基于排序的方法,无法求得meanrank,本发明在平均等级上分别胜过对比方法2和对比方法3,分别为0.391和0.132。对比试验2:三元组的分类对构成知识图谱的所有三元组进行分类,其实本质是一个二分类,即判断<头部实体,关系,尾部实体>是否正确。对比试验1并不适合此分类任务,所以实验结果如下展示:表2从表2中可以看出,本发明比方法2和方法3分别高出0.116和0.093。对比试验2:commonconsequencepredictioncommonconsequence指的是缺陷被攻击之后所产生的负面的技术影响,总共包括8个类别,所以这个任务本质是一个多标签的分类任务,通过macrof1以及microf1这个两个标准来对实验结果进行评价,对比试验1仍然不适用,结果如下:表3从表3中可以看出,本发明的microf1比方法2和方法3分别高12.2%和3.9%。macrof1也比方法2和方法3的方法优于12.9%和5%。实验表明,transcat模型可以捕获关于常见软件弱点的文本和结构性知识,从而有效地支持软件弱点上的各种推理任务。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1