一种基于特征递增的混合型个性化音乐推荐方法与流程
本发明涉及一种基于特征递增的混合型个性化音乐推荐方法,属于社交网络和推荐系统领域。
背景技术:
现有音乐推荐系统中有基于内容的推荐方法,例如sánchez-moreno等人在2016年发表的文章中,通过基于歌曲的歌手来实现歌曲属性的表示,因为每个歌手都有自己的一个曲风,然后再使用knn算法基于歌手实现对相似用户的选取,然后将相似用户常听的歌曲而目标用户未听的歌曲进行推荐;有基于模型的推荐方法,例如pacula在2009年发表的文章中,使用矩阵分解基于用户的隐式反馈来实现音乐推荐;有基于用户的推荐方法,例如deng等人在2015年发表的文章中,通过基于在相同情感下喜欢听相同歌曲的特征,找到相似用户,再根据从博客文本中挖掘出用户的情感,从相似用户的听歌记录中找到推荐项;有基于混合模型的推荐方法,例如bu等人在2010年发表的文章中,通过将基于内容的推荐和协同过滤结合构建混合型的推荐方法,利用音乐音频信息与用户社交关系来实现的推荐。
目前在音乐推荐系统中有些利用用户的社交关系和音乐音频信息进行混合型的推荐,但是这种方法没有考虑到音乐的另一重要属性,即歌词文本信息,这种方法只是考虑到了音乐的曲风,而没有考虑到音乐的情感;其中也有利用音乐的歌词文本来进行情感分析,将音乐进行基于情感倾向的分类,但是这种方法没有考虑到用户在听完歌曲后的一些感想,即忽略了评论文本中的情感,而评论文本中的情感往往可以帮助挖掘出歌曲中隐藏的情感,进而影响到歌曲情感倾向的准确度;其次是没有对用户的社交关系进行考虑,即忽略了用户社交关系图中用户感兴趣的人群,从而导致难以发现用户具有潜在兴趣的歌曲(比如,用户可能对感兴趣的人所喜欢的歌曲有好感)。
名词解释:
thulac:由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。其是由目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,在标准数据集chinesetreebank(ctb5)上分词的f1值可达97.3%,词性标注的f1值可达到92.9%,且每秒可处理约15万字。
senticnet:该知识库提供了一组语义、情感、极性关联的100000个自然语言概念,其中情感指的是四个情感维度pleasantness(愉悦度),attention(注意力),sensitivity(灵敏度),andaptitude(倾向性)上的情感值。
scorevj值:该值跟用户v在一段时间内对歌曲j的聆听次数有关,表示用户v对歌曲j的喜好程度值,0≤scorevj≤100,计算方法(1)如下:
技术实现要素:
为解决上述问题,本发明提供了一种基于特征递增的混合型个性化音乐推荐方法。本发明首先对歌词和评论文本进行情感分析,得到歌曲的情感向量;然后使用聚类算法对目标用户的听歌记录进行分类,得出目标用户的听歌喜好类别;再结合目标用户的社交关注关系,综合计算出目标用户对候选推荐歌曲的一个喜好程度值,最终实现个性化音乐推荐,本专利考虑目标用户的社交关注关系更易发现目标用户不太熟悉但具有潜在兴趣的歌曲,提高音乐推荐的准确率。
为达到上述技术效果,本发明的技术方案是:
一种基于特征递增的混合型个性化音乐推荐方法,包括如下步骤:
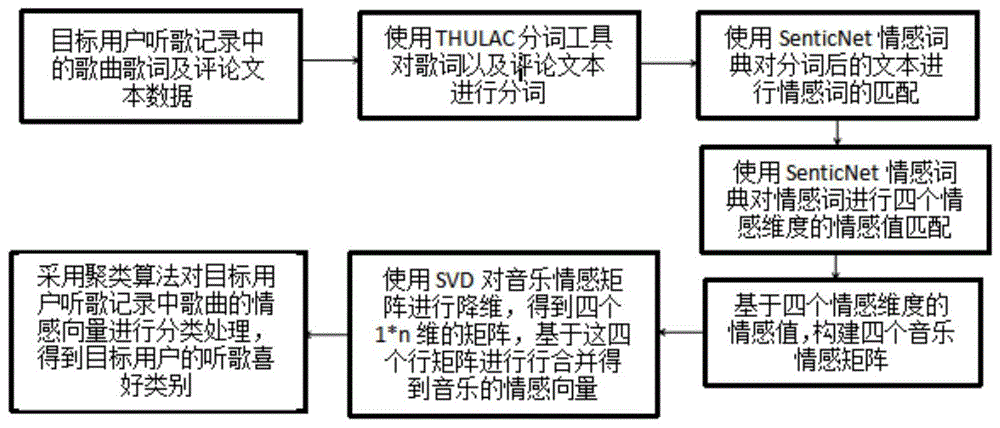
步骤一、数据收集与预处理:收集歌曲的歌词以及评论文本、用户的听歌记录和用户关注关系数据,并进行预处理;
步骤二、文本分词:使用词法分析工具对歌词l和评论c文本进行分词,得到词语表示的文本;
步骤三、音乐情感矩阵构建:首先用情感词典对分词后的歌词l和评论c文本进行情感词匹配,找到情感词;再根据情感词在四个情感维度上对应的情感值,构建四个情感矩阵edj,其中d表示情感维度,j表示歌曲;
步骤四、音乐情感向量构建:使用svd奇异值分解算法对情感矩阵edj进行降维处理,得到歌曲j在情感维度上的四个情感矩阵edj,并将基于情感维度上的四个情感矩阵edj进行合并得到歌曲j的情感向量ej,其中d表示情感维度,j表示歌曲;
步骤五、计算目标用户的听歌喜好类别以及权重:首先采用聚类算法对目标用户u的听歌记录r中歌曲的情感向量ej进行分类处理,得到目标用户u的听歌喜好类别cui;然后根据类别cui中的样本个数mui与目标用户u的样本总数mu的比值计算每个类别cui的权重wui;其中u表示目标用户,i表示第几个类别,j表示歌曲;
步骤六、候选推荐歌曲的选取以及相似度的计算:首先基于目标用户u的关注关系,找到目标用户感兴趣的其他用户v,从用户v的听歌记录中选取用户v喜好但目标用户u未听的歌曲作为候选推荐歌曲h;然后对候选推荐歌曲基于歌词以及评论文本进行情感分析,得到候选推荐歌曲的情感向量eh;再结合目标用户u的听歌记录r的分类结果,使用高斯函数计算候选推荐歌曲h与目标用户u的听歌喜好类别cui之间的相似度shcui;
步骤七:推荐歌曲的计算:基于候选推荐歌曲h与目标用户u的听歌喜好类别cui之间的相似度shcui和目标用户u的听歌喜好类别cui的权重wui计算目标用户u对候选推荐歌曲h的喜好程度值guh,当guh大于阈值t时,就将候选推荐歌曲h加入推荐列表cl中,否则放弃候选推荐歌曲h,
步骤八、重复步骤六和步骤七直到寻找到音乐推荐项或设定数量的音乐推荐项。
进一步的改进,所述步骤一中数据收集与预处理为:
首先从网易云音乐平台上爬取音乐信息以及评论信息、用户的听歌记录和用户关注关系;然后使用sql语句对数据进行处理,整理形成数据集,数据集含有三张数据表,三张数据表分别为歌曲信息表、用户听歌记录表和用户关注关系表;所述歌曲信息表包括歌曲id、歌名、歌手、歌词和评论文本、用户听歌记录表包括用户id、用户名、歌曲id、歌名和歌曲score值,用户关注关系表包括用户一id、用户二id、关注关系。
进一步的改进,所述词法分析工具为thulac工具;所述情感词典为senticnet情感词典。
进一步的改进,所述步骤三中音乐情感矩阵的构建方法为:
首先每首歌取频率最高的前n-1条评论加歌词文本作为一个文本就为n个文本;然后将分词后的歌词和评论文本分别与情感词典进行情感词匹配;再将匹配到的情感词较大的数目作为标准,设为k,情感词数目不足k的,使用0进行填充;然后根据每个文本中的情感词在四个情感维度上的情感值构建四个情感矩阵edj;其中四个情感维度分别为愉悦度、注意力、灵敏度、倾向度,这四个情感维度来源于senticnet情感词典,edj为k*n维的矩阵,d表示情感维度,j表示歌曲。
进一步的改进,所述步骤四中音乐情感向量构建方法为:
首先使用svd奇异值分解算法对情感矩阵edj进行矩阵降维,将k*n维的矩阵降维成1*n维的矩阵,公式(1)和(2)如下:
edj=udjσdj(vdj)t(1)
其中edj为k*n维的音乐情感矩阵,udj为k*k维的酉矩阵,即udj(udj)t=i,i为单位矩阵;σdj为k*n维的奇异值矩阵,奇异值矩阵即除主对角线上的其余元素都为0,主对角线上的元素是奇异值,奇异值是按大到小排列的,如σ11>σ22>σ33>...;vdjt为n*n维的酉矩阵;σuu表示奇异值;
edj=(udj(1))tedj(2)
由于σ11是最大的奇异值,所以取左奇异矩阵udj的第一列作为代表,即udj(1),udj(1)为k*1维的矩阵,转置得到1*k维的矩阵,即(udj(1))t,再将(udj(1))t与原始音乐情感矩阵edj相乘得到1*n维的音乐情感矩阵edj,然后将基于情感维度上的四个音乐情感矩阵edj进行合并构建音乐情感向量ej;其中d表示情感维度,j表示歌曲。
进一步的改进,所述步骤五中目标用户听歌喜好类别以及权重值的计算处理为:
首先采用聚类中的dbscan聚类算法,结合目标用户u听歌记录r中的歌曲的情感向量ej,构建分类模型,将情感倾向相似的歌曲组成聚类簇,即目标用户听歌喜好类别cui;然后计算每个类别cui相对于目标用户u的一个权重wui,权重wui由公式(3)计算:
wui=mui/mu(3)
其中mui表示类别cui中的样本数,mu表示目标用户u所有类别的总样本数,i表示第几个类别。
进一步的改进,所述步骤六中候选推荐歌曲的选取以及相似度的计算处理步骤如下:
(6.1)候选推荐歌曲的选取
基于目标用户u的关注关系,找到目标用户感兴趣的其他用户v;再挖掘出用户v的听歌记录,将用户v喜好而目标用户u未听过的歌曲作为候选推荐歌曲h;其中用户v喜好的歌曲通过其对歌曲j的scorevj值来进行判别,scorevj值的计算公式(4)如下:
其中scorevj表示用户v对歌曲j的喜好程度值,0≤scorevj≤100;而判别方法(5)如下:
即当用户v对歌曲j的scorevj值不小于用户v已听歌曲的scorevj值的均值的a倍,则认为该歌曲j是用户v所喜好的歌曲;其中num表示用户v已听歌曲的数目,a表示一个常数权重,1<a<2;目标用户u未听的歌曲表示目标用户听歌记录r中没有的歌曲。
(6.2)计算候选推荐歌曲h与类别cui的相似度shcui
首先对候选推荐歌曲h进行基于歌曲歌词以及评论文本的情感分析,得到候选推荐歌曲的情感向量eh;再结合目标用户u的听歌记录r的分类结果,使用高斯函数计算候选推荐歌曲h与目标用户u听歌喜好类别cui之间的相似度shcui,相似度shcui由高斯函数(6)计算如下:
其中kg表示一个常数权重,σcui2表示类别cui的方差,
进一步的改进,所述步骤七中推荐歌曲的计算为:
基于候选推荐歌曲h与目标用户听歌喜好类别cui之间的相似度shcui和目标用户听歌喜好类别cui的权重wui,计算目标用户u对该候选推荐歌曲h的喜好程度值guh,其由公式(7)计算如下:
其中c为目标用户听歌喜好的类别数;
当目标用户u对候选推荐歌曲h的喜好程度值guh大于阈值t时,就将该候选推荐歌曲作为推荐项,加入到推荐列表cl中,否则放弃该候选推荐歌曲。
附图说明:
图1为目标用户听歌喜好类别处理示意图
图2为候选推荐歌曲的选取示意图
图3为推荐项的生成过程示意图
图4为个性化音乐推荐方法的完整过程示意图
具体实施方式
下面通过具体实施以及附图对本发明做进一步的详述。
本发明主要有以下创新点:
1.基于歌曲歌词以及评论文本进行情感分析,得到音乐的情感倾向。
2.考虑目标用户的社交关注关系,发现目标用户不太熟悉但具有潜在兴趣的歌曲。
本发明具体技术方案说明如下:
一、数据预处理
本发明使用的数据集是从网易云音乐平台上爬取的音乐信息以及评论信息、用户的听歌记录和用户关注关系等数据整理而成,该数据集含有三张数据表分别为歌曲信息表(歌曲id、歌名、歌手、歌词、评论文本)、用户听歌记录表(用户id、用户名、歌曲id、歌名、歌曲score值)、用户关注关系表(用户一id、用户二id、关注关系)。本发明使用sql语句对数据进行处理,整理形成数据集;借助thulac中文分词算法来实现对文本信息的分词处理,该分词算法相比于其他分词算法如jieba、nlpir,在分词的准确率和效率上都是更好的选择,利用情感词典senticnet找到文本中的情感词以及相对应的情感值,用情感值来表示文本,实现文本特征的数值化。
二、音乐情感向量的构建
1.情感矩阵构建算法
1.1情感词的提取
由于歌词和评论文本信息中不是所有的词语都具有情感,有些词语只是起到一个连接作用,为了更加精准有效的预估文本的情感,本发明使用senticnet情感词典,该情感词典相较于其他情感词典(如nrc、dutir)有更加细粒度的情感分析,该情感词典包含的情感词也较丰富,其不仅仅包含情感词的极性,且包含情感词在四个情感维度上的情感值,使得情感分析更加的细粒。通过将分词后的歌词和评论文本与情感词典senticnet进行词语匹配,提取出歌词和评论文本中的情感词,从而实现用情感词对歌词和评论文本的表示。
1.2四个情感维度上的情感值计算
在情感词典senticnet中就包含了每一个情感词在四个情感维度上的情感值,由于歌词和评论文本经过情感词的提取后,就用情感词来进行表示,于是将情感词与情感词典senticnet进行匹配,从情感词典senticnet中找到相对应的四个情感维度上的情感值,分别存于四个数组中,从而得到用情感值表示的文本,实现文本的数值化。
1.3情感矩阵
首先每首歌取频率最高的前n-1条评论加1(歌词文本作为一个文本)就为n个文本;再根据每个文本中的情感词在四个情感维度上的情感值构建四个情感矩阵edj;由于音乐的歌词和评论中的情感词的数目不全会相同,但是为了方便表示和处理,于是将歌词或评论文本中与情感词典senticnet匹配到的情感词个数最大作为标准,设为k,情感词数目不足k的,使用0进行填充;其中四个情感维度分别为愉悦度(pleasantness)、注意力(attention)、灵敏度(sensitivity)、倾向度(aptitude),这四个情感维度来源于senticnet情感词典,edj为k*n维的矩阵,d表示四个情感维度,j表示歌曲,n表示评论条数+1(歌词文本作为1条)。
2.音乐情感向量的构建
首先使用svd奇异值分解算法对情感矩阵edj进行矩阵降维,将k*n维的矩阵降维成1*n维的矩阵,公式(1)和(2)如下:
edj=udjσdj(vdj)t(1)
其中edj为k*n维的音乐情感矩阵,udj为k*k维的酉矩阵,即udj(udj)t=i,i为单位矩阵;σdj为k*n维的奇异值矩阵,奇异值矩阵即除主对角线上的其余元素都为0,主对角线上的元素是奇异值,奇异值是按大到小排列的,如σ11>σ22>σ33>...;vdjt为n*n维的酉矩阵;σuu表示奇异值;
edj=(udj(1))tedj(2)
由于σ11是最大的奇异值,所以取左奇异矩阵udj的第一列作为代表,即udj(1),udj(1)为k*1维的矩阵,转置得到1*k维的矩阵,即(udj(1))t,再将(udj(1))t与原始音乐情感矩阵edj相乘得到1*n维的音乐情感矩阵edj,然后将基于情感维度上的四个音乐情感矩阵edj进行合并构建音乐情感向量ej。
三、推荐项的生成
1.目标用户听歌喜好类别以及权重值的计算
首先采用聚类中的dbscan聚类算法,结合目标用户u的听歌记录r中的歌曲的情感向量ej,构建分类模型,将情感倾向相似的歌曲组成聚类簇,即目标用户听歌喜好类别cui;然后计算每个类别cui相对于目标用户u的一个权重wui,权重wui由公式(3)计算:
wui=mui/mu(3)
其中mui表示类别cui中的样本数,mu表示目标用户u所有类别的总样本数,i表示第几个类别。
2.候选推荐歌曲的选取以及相似度的计算
(2.1)候选推荐歌曲的选取
基于目标用户u的关注关系,找到目标用户感兴趣的其他用户v;再挖掘出用户v的听歌记录,将用户v喜好而目标用户u未听过的歌曲作为候选推荐歌曲h;其中用户v喜好的歌曲通过其对歌曲j的scorevj值来进行判别,scorevj值的计算公式(4)如下:
其中scorevj表示用户v对歌曲j的喜好程度值,0≤scorevj≤100;而判别方法(5)如下:
即当用户v对歌曲j的scorevj值不小于用户v已听歌曲的scorevj值的均值的a倍,则认为该歌曲j是用户v所喜好的歌曲;其中num表示用户v已听歌曲的数目,a表示一个常数权重,1<a<2;目标用户u未听的歌曲表示目标用户听歌记录r中没有的歌曲。
(2.2)计算候选推荐歌曲h与类别cui的相似度shcui
首先对候选推荐歌曲h进行基于歌曲歌词以及评论文本的情感分析,得到候选推荐歌曲的情感向量eh;再结合目标用户u的听歌记录r的分类结果,使用高斯函数计算候选推荐歌曲h与目标用户u听歌喜好类别cui之间的相似度shcui,相似度shcui由高斯函数(6)计算如下:
其中kg表示一个常数权重,σcui2表示类别cui的方差,
3.目标用户u对候选推荐歌曲h的喜好程度值guh的计算
基于候选推荐歌曲h与目标用户听歌喜好类别cui之间的相似度shcui和目标用户听歌喜好类别cui的权重wui,计算目标用户u对该候选推荐歌曲h的喜好程度值guh,其由公式(7)计算如下:
其中c为目标用户听歌喜好的类别数。
当目标用户u对候选推荐歌曲h的喜好程度值guh大于阈值t时,就将该候选推荐歌曲作为推荐项,加入到推荐列表cl中,否则放弃该候选推荐歌曲。
上述仅为本发明的一个具体导向实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明的保护范围的行为。
- 还没有人留言评论。精彩留言会获得点赞!