基于无监督学习的诈骗呼叫序列检测方法与流程
本发明属于数据挖掘与机器学习和商务智能等领域,本发明具体涉及一种无监督学习的诈骗呼叫序列检测方法,。
背景技术:
电信欺诈检测是目前国内外电信行业中一个重要的问题,它威胁到人们的财产安全,同时对电信正常运营带来巨大的困扰。因此,运营商、政府部门都试图采取各种手段和技术进行电信欺诈的检测和识别。在实际中,每天呼叫的数据量非常大,涉及的被叫用户达到了亿级以上。而且,传统依靠用户标记进行诈骗电话的判断需要大量用户标记数据或网络举报投诉数据,上述数据的获得存在较高的难度,因此在现实环境中往往缺乏有效的主叫号码风险标签。因此,亟需设计一种能够一定程度克服上述缺陷的诈骗呼叫序列检测方法。
技术实现要素:
有鉴于欺诈主叫用户一般会掩饰自己的行为在大量的正常行为中,并在较短的时间内隐藏他们的真实意图,而且欺诈行为通常是在连续的时间中发生,以获取非法利益,因此通过考虑主叫节点的完整行为序列为检测欺诈行为提供了独特的线索。本发明提供了一种基于无监督学习的诈骗呼叫序列检测方法,构建主叫呼叫序列,同时构造主叫节点和被叫节点的有向序列二部图;利用受限随机游走和skip-gram方法学习主叫节点的低维嵌入表示向量;利用lstm模型进行预测下一个目标节点;利用平均交叉熵构建损失函数并利用adam进行优化并求解参数,能够更准确地进行主叫的异常检测。本发明便于处理大量呼叫数据,并无需使用用户标记或投诉数据。
本发明提供了基于无监督学习的诈骗呼叫序列检测方法,具体包括:
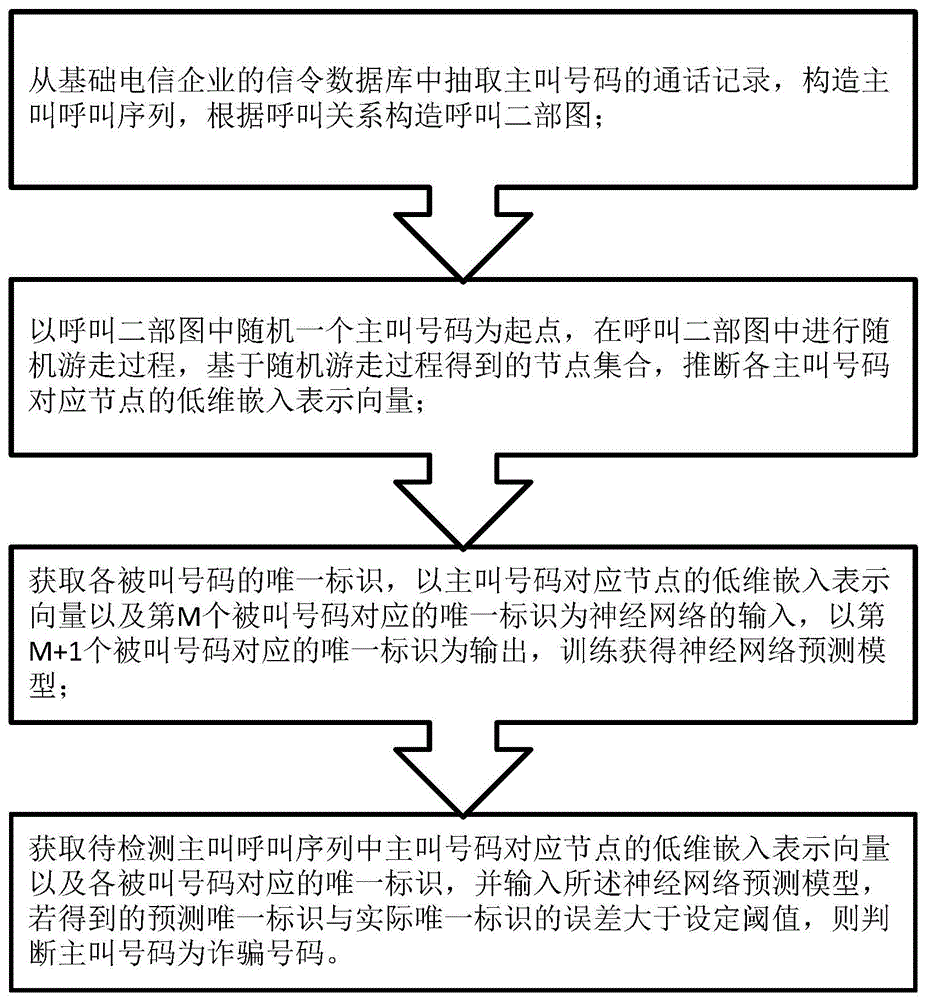
从基础电信企业的信令数据库中抽取主叫号码的通话记录,构造主叫呼叫序列,根据呼叫关系构造呼叫二部图;
以呼叫二部图中随机一个主叫号码为起点,在呼叫二部图中进行随机游走过程,基于随机游走过程得到的节点集合,推断各主叫号码对应节点的低维嵌入表示向量;
获取各被叫号码的唯一标识,以主叫号码对应节点的低维嵌入表示向量以及第m个被叫号码对应的唯一标识为神经网络的输入,以第m+1个被叫号码对应的唯一标识为输出,训练获得神经网络预测模型;
获取待检测主叫呼叫序列中主叫号码对应节点的低维嵌入表示向量以及各被叫号码对应的唯一标识,并输入所述神经网络预测模型,若得到的预测唯一标识与实际唯一标识的误差大于设定阈值,则判断主叫号码为诈骗号码。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,所述主叫呼叫序列中被叫号码的数量不小于设定阈值。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,在随机游走过程中,在到达一目标节点后,查看当前目标节点与上一目标节点之间的通话时长,若通话时长大于预设时间窗口,则随机游走过程结束。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,采用skip-gram方法推断各主叫号码对应节点的低维嵌入表示向量。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,被叫号码的唯一标识通过将被叫号码转化为独热编码向量得到。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,将低维嵌入表示向量和独热编码向量连接,形成输入向量输入神经网络。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,所述神经网络为lstm神经网络。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,还包括:
在训练神经网络过程中选择lq为损失函数;
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,采用adam算法训练神经网络。
优选的是,所述的基于无监督学习的诈骗呼叫序列检测方法,计算预测唯一标识与实际唯一标识之间的损失函数数值,若损失函数数值大于设定阈值,则判断主叫号码为诈骗号码。
本发明至少包括以下有益效果:
本发明的优势在于通过构建主叫呼叫序列,利用受限随机游走过程限制了游走范围,并且利用skip-gram学习主叫节点的低维嵌入表示向量,将被叫的唯一标识和低维嵌入表示向量输入到lstm模型中。此外,该发明中提出的方法容易实现并行化计算,可以实现较高的检测效率。
本发明鉴于当前的电信诈骗活动往往存在着某种特定的序列特征和通联特征的行为模式,例如部分诈骗电话采用连续呼叫手法、诈骗主叫往往倾向于呼叫更多的被叫用户,以提高其诈骗的成功率。而且欺诈主叫用户一般会掩饰自己的行为在大量的正常行为中,并在较短的时间内隐藏他们的真实意图,并且欺诈行为通常是在连续的时间中发生,以获取非法利益,因此通过考虑主叫节点的完整行为序列来检测欺诈行为提供了独特的线索。
本发明从大量呼叫数据中提取主叫呼叫序列,并训练获得神经网络预测模型,然后根据神经网络预测模型预测待检测主叫呼叫序列的被叫号码的唯一标识,最后根据预测唯一标识与实际唯一标识间的误差判断风险值,在此过程中无需使用用户标记或投诉数据。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
图1为本发明一个实施例的流程图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
本发明提供了基于无监督学习的诈骗呼叫序列检测方法,具体包括:
从基础电信企业的信令数据库中抽取主叫号码的通话记录,构造主叫呼叫序列,根据呼叫关系构造呼叫二部图;
以呼叫二部图中随机一个主叫号码为起点,在呼叫二部图中进行随机游走过程,基于随机游走过程得到的节点集合,推断各主叫号码对应节点的低维嵌入表示向量;
获取各被叫号码的唯一标识,以主叫号码对应节点的低维嵌入表示向量以及第m个被叫号码对应的唯一标识为神经网络的输入,以第m+1个被叫号码对应的唯一标识为输出,训练获得神经网络预测模型;
获取待检测主叫呼叫序列中主叫号码对应节点的低维嵌入表示向量以及各被叫号码对应的唯一标识(即id),并输入所述神经网络预测模型,若得到的预测唯一标识与实际唯一标识的误差大于设定阈值,则判断主叫号码为诈骗号码。
鉴于当前的电信诈骗活动往往存在着某种特定的序列特征和通联特征的行为模式,例如部分诈骗电话采用连续呼叫手法、诈骗主叫往往倾向于呼叫更多的被叫用户,以提高其诈骗的成功率。而且欺诈主叫用户一般会掩饰自己的行为在大量的正常行为中,并在较短的时间内隐藏他们的真实意图,并且欺诈行为通常是在连续的时间中发生,以获取非法利益,因此通过考虑主叫节点的完整行为序列为检测欺诈行为提供了独特的线索。
在上述技术方案中,主叫呼叫序列为主叫号码在一段时间内的呼叫记录,包括多个被叫号码1、2、3……m、m+1……,按呼叫时间点排序。利用主叫节点(对应主叫号码)和被叫节点(对应被叫号码)构建二部图,具体为有向二部图,并将呼叫时间作为描述主被叫节点连接的属性,例如二部图g=(u;v;e;a;p),u为sourcenodes、v是targetnodes、e是edges、a是呼叫行为属性,p是特征向量(calleeid,areacodeid,durationtime,andcallingtime等)。对呼叫二部图进行随机游走,获得游走节点集合,进而获得各主叫节点和被叫节点的低维嵌入表示向量。被叫号码的唯一标识承载着被叫号码的信息,包括被叫号码本身,还可以包含被叫号码的归属地等其它信息。在训练神经网络时,主叫号码对应节点的低维嵌入表示向量为其中一个输入,被叫号码的唯一标识是另一个输入,被叫号码的唯一标识在使用之前可以进行适当地处理以便于输入,如向量化等。选取主叫呼叫序列作为训练集,以主叫号码对应节点的低维嵌入表示向量和第m个被叫号码的唯一标识为输入,以第m+1个被叫号码的唯一标识为输出,经过多次训练即可得到神经网络预测模型。最后,便可以利用神经网络预测模型来检测待测主叫呼叫序列,将待测主叫呼叫序列利用与上述相同的方法进行处理,即获得待测主叫呼叫序列的主叫节点的低维嵌入表示向量以及各被叫号码的唯一标识,并输入至神经网络预测模型,获得下一个被叫号码的预测唯一标识,将预测唯一标识与实际唯一标识进行比较,当误差大于设定阈值,即可判断待测主叫呼叫序列的主叫号码为诈骗号码。设定阈值可以根据经验确定,也可以根据统计手段获得。可以看出,本技术方案以大量主叫呼叫序列为研究对象,进行适当地处理后,训练获得神经网络模型,利用神经网络的预测值与实际值的误差来判断是否存在诈骗,在此过程中无需使用用户标记或投诉数据。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,所述主叫呼叫序列中被叫号码的数量不小于设定阈值。这里,提供了选取主叫呼叫序列的选取方式,当主叫呼叫序列的被叫号码数量过少,一方面该主叫号码序列成为诈骗呼叫序列的可能性较小,另一方面能够获得的有用信息也较少。设定阈值可以根据经验或统计调查获得。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,在随机游走过程中,在到达一目标节点后,查看当前目标节点与上一目标节点之间的通话时长,若通话时长大于预设时间窗口,则随机游走过程结束。这里,提供了随机游走的优选方式,即受限随机游走,当通话时长大于预设时间窗口,则停止游走,通话时长越长,主叫号码为诈骗的可能性越小,通过这种方式的游走,使得得到的每个游走集合尽可能较好地反应诈骗特征信息,进而使得主叫节点的低维嵌入表示向量也能够涵盖较多诈骗特征信息,提高后续检测准确度。预设时间窗口可以根据经验或统计调查获得。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,采用skip-gram方法推断各主叫号码对应节点的低维嵌入表示向量。这里,提供了推断主叫号码对应节点的低维嵌入表示向量的优选方法,该方法的目标是最大化一定时间窗口内的节点之间的共现概率,其中的共现概率定义如下:
φ(vi)是节点vi的表示向量。skipgram方法利用节点vi的表示向量来预测在随机游走过程中的邻居节点。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,被叫号码的唯一标识通过将被叫号码转化为独热编码向量得到。这里,提供了提供了被叫号码的唯一标识的获取方式,即将被叫号码转化为独热编码向量,独热编码向量也便于输入神经网络。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,将低维嵌入表示向量和独热编码向量连接,形成输入向量输入神经网络。这里,将低维嵌入表示向量和独热编码向量连接,比如低维嵌入表示向量为a维向量,独热编码向量为b维向量,连接后形成a+b维向量。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,所述神经网络为lstm神经网络。这里,提供了优选的神经网络,lstm是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,还包括:
在训练神经网络过程中选择lq为损失函数;
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,采用adam算法训练神经网络。这里,提供了优选的神经网络训练方法,相比于其它训练方法更适合。
在另一种技术方案中,所述的基于无监督学习的诈骗呼叫序列检测方法,计算预测唯一标识与实际唯一标识之间的损失函数数值,若损失函数数值大于设定阈值,则判断主叫号码为诈骗号码。这里,利用损失函数表示预测唯一标识与实际唯一标识之间的误差,相比于其它表示方式更优。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!