基于高性能可重构弹性计算的AI超级计算机的制作方法
本说明书实施例涉及一种超级计算机,尤其涉及一种基于高性能可重构弹性计算(hec)的ai(人工智能,artificialintelligence)超级计算机(aisc)。
背景技术:
人工智能(ai)的发展突飞猛进,但它的运行平台大部分还是基于cpu、gpu、fpga和asic及其组合形成的平台。这些运行平台在ai产品部署的时候给开发者和用户造成很多困扰:
(1)cpu灵活性最高,但对于ai等需要大量并行计算的场景下其能效比非常低;gpu和fpga解决了一部分并行计算的问题,但功耗和成本一直是影响其部署的重要因素;asic具有很好的能效比,但其只能适应固定的算法,对算法演进无能为力。
(2)由cpu、gpu、fpga和asic的一种或几种组成的平台在系统架构的复杂性,算力的可扩充性、系统的功耗、成本等方面都难如人意。
技术实现要素:
本说明书实施例提出一种基于高性能可重构弹性计算的ai超级计算机,该计算机可根据产品需求和使用环境弹性地部署算力,可支持边缘计算、大规模计算以及极大规模计算,可支持无需指令驱动的各种神经网络计算、支持在线训练与在线算法迭代、并且具备极高的通用性、灵活性和能效比。
本说明书实施例的基于高性能可重构弹性计算的ai超级计算机,包括:机器感知机,用于提供环境感知信息或设备输入信息作为可重构数据;可重构计算单元rpu阵列;机器行为器,用于输出ai超算计算或者推理的结果或者执行ai超算相关的指令;基于可重构计算的高性能弹性计算主控系统hec;基于可重构计算的高性能弹性连接系统hec_link;基于可重构弹性计算的ai超算编译系统,用于将应用程序编译生成主控制器的控制码、hec_link的控制信息、rpu阵列的各项配置信息,以便主控系统在控制码的控制下连接机器感知机和机器行为器,hec_link在控制信息的控制下连接高性能弹性计算主控系统hec和rpu阵列,rpu阵列在配置信息的控制下,基于可重构数据执行ai超算的可重构数据计算。
在可能的实施方式下,所述hec包括:由多层系统总线、配置总线、片上dma控制器、片上存储器、片上存储控制器、外设控制器和片外存储器中的至少一个组成的系统级可重构数据通路。
在可能的实施方式下,所述高性能弹性连接系统(hec_link)在控制信息的控制下实现rpu和rpu之间以及rpu与主控制芯片系统之间的高速数据传输,以及主控制芯片与rpu之间的配置状态与配置信息通信。
在可能的实施方式下,rpu阵列包括一个或多个rpu,rpu之间通过hec_link连接在一起;各rpu均通过hec_link获取配置信息。
在可能的实施方式下,ai超级计算机包括基于可重构弹性计算的ai超算操作系统,用于管理ai超算的软件和硬件资源以及外设资源,用于执行编译系统输出的编译文件,用于获取从机器感知机获取的信息,用于在控制机器行为器执行ai计算的结果,用于执行在线编译。
在可能的实施方式下,编译系统根据神经网络的特点进行适配。
在可能的实施方式下,所述编译系统编译用于根据hec_link和rpu阵列特点,利用hec_link对rpu阵列进行列和/或行的扩展的控制信息。
在可能的实施方式下,所述编译系统编译用于通过hec_link改变rpu的连接关系的控制信息。
在可能的实施方式下,所述编译系统编译的控制信息使得一个或多个rpu:同时执行一个或多个不同的训练任务;同时执行一个或多个不同的推理任务;同时执行多个训练任务和多个推理任务;或者,将同一数据同时输入到训练网络和推理网络。
在可能的实施方式下,在hec_link采用分布式部署或云部署时,所述编译系统根据hec_link连接信息进行编译,部署主控系统、hec_link和以及各个rpu的任务。
在可能的实施方式下,所述编译系统是离线编译模式,输出编译文件直接传递给操作系统执行;或者运行在操作系统上的在线编译模式,编译完毕之后,根据需要直接由操作系统执行。
在可能的实施方式下,ai超级计算机包括:编译系统将在线训练的网络结构通过在线编译实时部署下去,实现神经网络的在线实时更新。
本说明书实施例可以实现更强的算力部署、更多的并行计算、以及同时执行多种不同的任务。
附图说明
为了使本说明书实施例中的技术方案及优点更加清楚明白,以下结合附图对本说明书的示例性实施例进行进一步详细的说明,显然,所描述的实施例仅是本说明书的一部分实施例,而不是所有实施例的穷举。
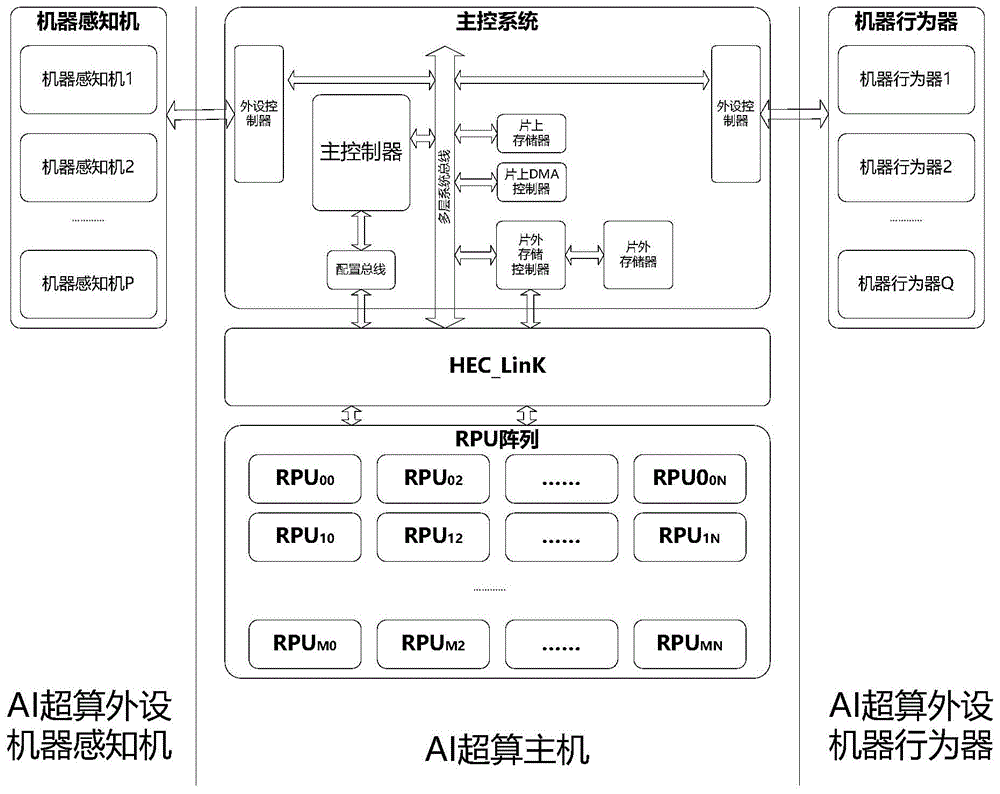
图1是基于高性能可重构弹性计算的ai超级计算机系统架构图;
图2(a)和图2(b)示意了ai超级计算机的算力扩展图;图2(a)是扩展前的算力图,图2(b)是扩展后的算力图。
图3是ai超算弹性调节算力,并行执行两个任务的示意图。
具体实施方式
下面结合附图,对本说明书提供的方案进行描述。
图1是基于高性能可重构弹性计算的ai超级计算机系统架构图。如图1所示,基于高性能可重构弹性计算的ai超级计算机(aisc)包括基于可重构计算的高性能弹性计算主控系统(hec)、基于可重构计算的高性能弹性连接系统(hec_link)、可重构计算单元阵列(rpu阵列)、至少一个机器感知机1-p、机器行为器1-q、和基于可重构弹性计算的ai超算编译系统。p、q为自然数。
基于可重构计算的高性能弹性计算主控系统(hec)用于在控制码的控制下连接机器感知机和机器行为器,连接可重构计算单元(rpu)阵列。hec是ai超算(aisupercomputer,aisc)的中央处理单元,为在线编译系统运行提供硬件运行平台;是连接可重构计算单元(rpu)阵列的控制平台;是连接机器感知机和机器行为器的外设控制平台。
在一个例子中,hec可以包括由多层系统总线、配置总线、外设控制器、片上dma控制器、片上存储器、片上存储控制器、片外存储器、片外存储器控制器中的一个或多个组成的系统级可重构数据通路。在系统级可重构数据通路的运行中,dma控制器在被系统中的主控制器设置后,可以通过片外存储控制器访问片外存储器,将数据(计算对象)从片外存储器读出并写入到片上存储器,或者数据(计算结果)从片上存储器读出并写入到片外存储器。
在一个例子中,hec可以包括由主控制器、配置总线组成的系统级可重构控制器;该系统级可重构控制器发布系统级控制任务,以便通过多层系统总线对系统中的外设控制器、dma控制器和片外存储控制器进行控制,以完成系统级控制。
在一个例子中,主控制器还可承担通用cpu处理器的部分功能。
基于可重构计算的高性能弹性连接系统(hec_link)用于在控制信息的控制下连接高性能弹性计算主控系统和rpu阵列。hec_link是ai超算实现算力弹性配置的辅助控制单元与主要实现载体,可根据算力扩展的不同模式以及不同应用场景配置相应的hec_link。hec_link是可通过主控系统对rpu阵列的连接关系进行配置的,控制信息就是用来定义连接关系的。
在一个例子中,hec_link用于连接高性能弹性计算主控系统和可重构计算单元rpu阵列,实现rpu和rpu之间以及rpu与主控制芯片系统之间的高速数据传输,以及主控制芯片与rpu之间的配置状态与信息通信。
在一个例子中,所述hec_link可以根据需要,对已经确定的rpu阵列,通过改变连接关系,让各个rpu之间以不同的方式进行组合。组合包括但不限于对rpu进行分组,分别输入不同的可重构数据并执行不同任务、输入不同的数据执行同样的任务,以及输入同样的数据执行不同的任务,以及输入同样的数据并高效地执行同一个任务等等。
在一个例子中,所述hec_link可用于根据算力需求对rpu进行计算深度和计算宽度的扩展,获得执行更大程序或更多任务的能力。
在一个例子中,所述hec_link,可用于根据算力需求对rpu阵列进行阵列部署、分布式部署或云部署。
在一个例子中,hec_link有多种形态,在各种形态中均包括:协议控制器(用于协议转换)和/或桥接控制器、桥接电路。这些控制器或电路可以存在于主控芯片、独立芯片、rpu芯片中、或以其它形态存在。
可重构计算单元阵列(rpu阵列)用于在配置信息的控制下,基于可重构数据执行ai超算的可重构数据计算。rpu阵列是ai超算弹性计算的核心运算单元,ai超算的可重构数据计算可以全部在rpu阵列上完成;可根据需求增删rpu或者改变rpu阵列的排列方式与网络架构,实现可重构计算的算力配置。
在一个例子中,可重构计算单元阵列(rpu阵列)包括按m行n列排列的多个rpu,rpu和rpu之间通过hec_link连接在一起,各rpu均可通过hec_link获取相应的配置信息。
在一个例子中,输入到rpu的可重构数据来自其他rpu或通过hec_link来自主控系统,rpu的计算结果输出到其他rpu或通过hec_link输出到主控系统,输入来源和输出目的取决于主控系统和hec_link的控制。
rpu阵列内的可重构数据通路可以通过片外存储器交换数据。该rpu阵列内的可重构数据通路和系统级可重构数据通路与两者共同构成ai超算的可重构数据通路的主体。
rpu阵列中各rpu内可设置可重构控制器。系统级可重构控制器和hec_link控制器、rpu阵列中各rpu内的可重构控制器共同构成ai超算的可重构控制器的主体。
至少一个机器感知机1-n,用于提供环境感知信息或设备输入信息作为可重构数据。机器感知机是ai超算的外设,用于为ai超算提供视觉、听觉、触觉、味觉、地理位置、位姿变化等环境感知信息或设备输入信息。
在一个例子中,机器感知机包括终端传感器,完成终端周边环境及自身状态的信息采集。终端传感器包括但不限于图像传感器(camera)、毫米波雷达(radar)、超声波雷达(ultrasonic)、激光雷达(lidar)、惯性测量单元(imu)、麦克风(mic)、全球卫星导航系统(gnss)、触摸屏(touchpanel)、应力感应器等。
在一个例子中,机器感知机还包括:具备感知分析和计算能力的传感器模组,对终端传感器采集的数据进行二次分析计算生成新的环境感知信息。传感器模组包括但不限于rgb-d深度相机、双目深度相机、vio三维重建相机等;其感知分析和计算能力可以基于cpu、gpu、fpga或dsp,也可以基于rpu。
至少一个机器行为器1-p是ai超算的外设,用于输出ai超算计算或者推理的结果或者执行ai超算的指令。
在一个例子中,基于可重构弹性计算的机器行为器包括但不限于通讯单元、人机接口、伺服机构、控制单元等中的一个或多个。
基于可重构弹性计算的ai超算编译系统,用于将应用程序编译生成主控制器的控制码、hec_link的控制信息、rpu阵列的各项配置信息。
具体来说,ai超算编译系统可以将应用程序进行标记与预处理,分解成主控系统执行代码和rpu执行代码,然后根据rpu阵列对rpu执行代码进行代码变换与优化,任务时域划分、任务rpu划分、任务配置信息生成,最终编译生成主控制器的控制码、hec_link的控制信息、rpu阵列的各项配置信息。
在一个例子中,ai超算的编译系统的输入是高级编程语言编写的应用程序,如c、python等。编译系统还包括高级语言依托的应用框架,如tensorflow、caffe等。所述编译系统输出的是可重构计算的主控制器的控制码、hec_link的控制信息、rpu阵列的各项配置信息,以及主控系统的通用执行程序等编译任务的处理状态信息。
进一步地,所述编译系统支持无指令驱动神经网络。
在一个例子中,所述支持无指令驱动神经网络,包括:
(1)无需指令驱动神经网络执行任务。神经网络在完成编译之后形成的编译文件,包括主控制器的控制码、hec_link的控制信息、rpu阵列的各项配置信息。这些文件在执行时,不需要指令控制,就可以实现从可重构数据的输入到输出,主控系统获得的结果就是神经网络的端到端的结果。
(2)可通过扩展编译系统支持各种神经网络。神经网络的训练和推理过程中包括大量并行计算与重复计算,编译系统可根据各种神经网络的特点进行适配。
进一步地,所述编译系统,可在编译时,配合hec_link实现对rpu阵列的多模式弹性部署。多模式弹性部署模式包括但不限于:
(1)根据hec_link和rpu阵列特点,利用hec_link对rpu阵列进行列和行的扩展。rpu阵列的列扩展有利于支撑更多的并行计算,rpu阵列的行扩展有利于加速较长计算序列的pipeline速度。hec_link为开放式结构,可以根据ai超算的算力需求和环境需求扩展rpu阵列。
图2(a)和图2(b)示意了一种ai超算的算力扩展图。图2(a)是扩展前的算力图。在图2(a)中,rpu阵列包括6个rpu。来自主控系统的配置信息经配置总线传送到hec_link和rpu阵列,使得rpu阵列形成如下结构:6个rpu排成彼此并联的2列3行,每行之间的rpu不能相互交换可重构数据,crossbar根据配置信息或者协议将上一行的任意一个rpu输出的可重构数据传递给下一行中的任意一个rpu,crossbar根据配置信息或者协议将最后一行的任意一个rpu输出的可重构数据返回给第一行中的任意一个rpu。
图2(b)是扩展后的算力图。在图2(b)中,rpu阵列扩展为16个rpu,分为并联的4列4列,每行之间的rpu不能相互交换可重构数据,crossbar根据配置信息或者协议将上一行的任意一个rpu输出的可重构数据传递给下一行中的任意一个rpu,crossbar根据配置信息或者协议将最后一行的任意一个rpu输出的可重构数据返回给第一行中的任意一个rpu。
(2)可以在编译时做如下设置,通过hec_link改变rpu的连接关系,对于已经确定的rpu阵列,进行宽度或者深度的调整,以分别适应更多并行计算或者更长计算周期的任务。
(3)在编译时做如下设置,通过hec_link改变rpu的连接关系,协调rpu阵列中的一个或几个rpu形成一个独立的rpu组,一个rpu阵列中可形成多个rpu组,分别异步并行执行多任务,且相互之间不干扰,以实现mimd和misd的多任务、高度并行化且高效运行的计算目标。
图3是ai另一种超算弹性调节算力,并行执行两个任务的示意图。如图3的上半图所示,在主控系统经配置总线传送的配置信息的控制下,hec_link的交叉桥路crossbridge形成如此的结构:任务a的数据经hec_link的接口然后经a节点和hec_link接口输入rpu0,rpu0的运算结果经hec_link接口以及crossbridge进入rpu1。rpu1的运算结果同样经hec_link接口以及crossbridge进入rpu2。由此,实现任务a的运算。
同样,任务b的数据流转包括rpu3,rpu4,rpu5,rpu6,最后到rpu7。实现了任务b的运算。
从图3可见,任务a和任务b基本并行进行。图3的下半图简要示意了两个任务的进行情况。
再进一步地,各个独立的pru组可同时执行一个或多个不同的训练任务;也可以同时执行一个或多个不同的推理任务;还可以同时执行多个训练任务和多个推理任务,以及将同一数据同时输入到训练网络和推理网络。
(4)在hec_link采用分布式部署或云部署时,可以根据hec_link连接信息进行编译,部署主控系统、hec_link和以及各个rpu的任务,以适应极大规模的算力部署与并行计算。
进一步地,在rpu阵列发生变化时,包括但不限于rpu数量变化、rpu连接方式变化等,可通过重新编译,实现局部或者全局重新部署任务。
进一步地,所述编译系统,可支持多模式编译。
在一个例子中,编译过程可以是离线编译模式,输出编译文件直接传递给操作系统执行;
在一个例子中,也可以是运行在操作系统上的在线编译模式,编译完毕之后,根据需要直接由操作系统执行。
在一个例子中,在线编译系统可以将在线训练的网络结构通过在线编译实时部署下去,实现神经网络的在线实时更新。
可选地,ai超级计算机包括基于可重构弹性计算的ai超算操作系统,用于管理ai超算的硬件和软件资源,管理ai超算的外设资源,并根据编译系统的输出结果,执行控制码,并将配置信息和可重构数据输出到rpu阵列,控制执行可重构计算程序并返回结果。主控系统hec为ai超算的操作系统运行提供硬件运行平台。
在一个例子中,所述操作系统用于获取从机器感知机获取的信息,用于在控制机器行为器执行ai计算的结果。
在一个例子中,所述操作系统用于执行在线编译。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!