基于蜜罐系统的结构化查询语言注入检测方法及装置与流程
本发明涉及通信安全
技术领域:
,特别是指一种基于蜜罐的结构化查询语言(structuredquerylanguage,sql)注入入侵检测方法及装置。
背景技术:
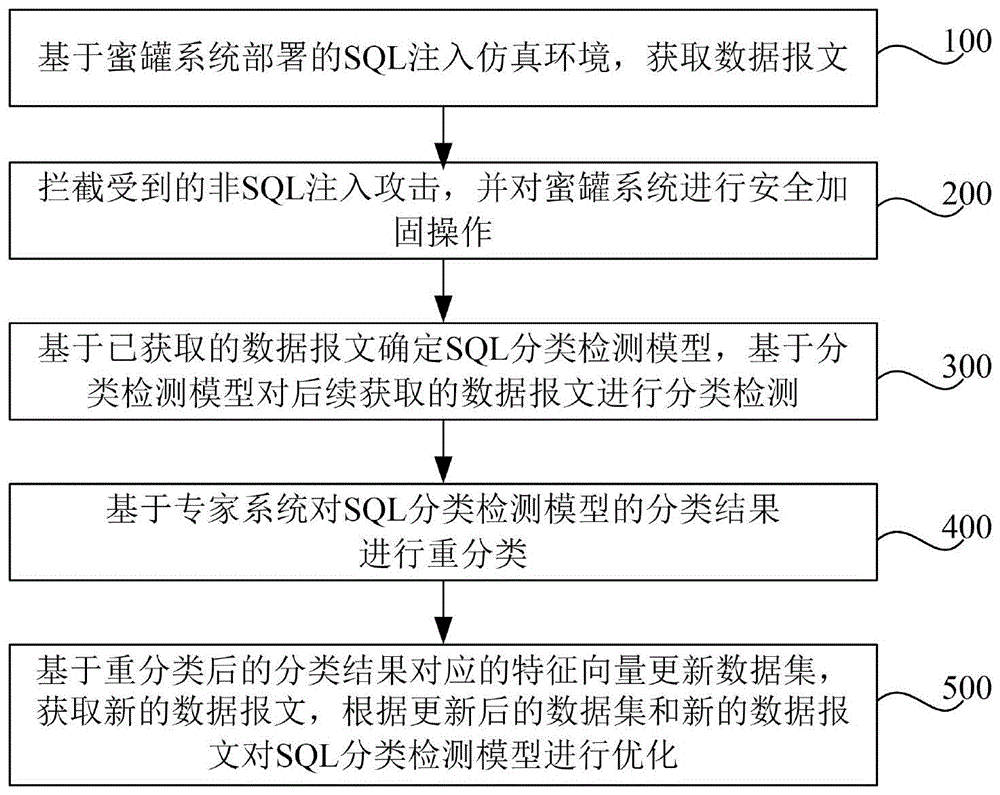
:目前,关于sql注入入侵和检测技术的研究越来越多,相关的开源软件主要包括:sqlmap、modsecurity、x-waf等。国内外在访问流量的sql注入安全性分析领域做了大量的研究,提出了一些可行的静态、动态等安全性分析方法,并且构造了相应的软件安全性分析工具。目前主流的安全性分析方法包括:词法分析、语法分析、动态分析、机器学习等算法分析。现有技术一中,基于词法分析的静态扫描方法将超文本传输协议(hypertexttransferprotocol,http)数据包作为输入,并将每个数据包按照协议格式进行解析,对关键字段中的内容进行词法标记,比较记号流中的标识符和预先定义的安全性漏洞字典,从而找出流量中潜在的攻击向量。例如一旦发现数据流量中存在union,select等非法数据库操作函数,即认为存在sql注入入侵。目前主流的静态代码分析引擎基本都是以可疑语法、词法规则匹配为主,既然是有限的规则集,就不可避免会存在误报和漏报的情况。误报即拦截存在符合非法规则集条件的正常用户请求,这将极大影响正常用户的消费体验。漏报即总会找到非法规则之外的攻击向量并成功发起攻击,一旦攻击者找到这样的一类攻击向量,那么整个防火墙就会因为短板效应而形同虚设。尤其随着攻击手段的多样化,变种攻击或者0day攻击向量势必会对传统的静态检测技术产生强大的冲击。现有技术二中,基于语法分析的安全性检查以语法分析和语义规则为基础,构造对应的sql查询语法树,因此这种方法具有较高的分析效率和可扩展性,但是对于运行时的环境具有先决性要求,故一般应用于数据库端的防火墙。基于动态分析的算法在程序运行时执行,通过大量攻击向量的构造和测试,依据其动态运行返回的状态结果来判断异同。由于http响应包中不一定能够体现带外注入等漏洞类型,故容易造成漏报,因此该方法一般用于漏洞利用环节。如常规的漏洞扫描器则是采用的动静结合方式进行。近年来,基于rasp等的运行时安全检测技术在上下文关联上做了不少工作,但对于运行时性能具备较高的要求,因此需要具体案例具体分析,通用性较差;此外,动态分析对于带外注入等漏洞类型的检测效果较差。现有技术三中,基于机器学习的算法以其强大的自适应性、自学习能力为安全领域提供了一系列有效的分析决策工具,完美的契合了sql注入流量大、变种多、检测规则维护难的设计诉求。通过将http流量以特征向量的方式诠释给分类模型,进一步训练优化生成具有较强分类效果的分类器,进而解决实际应用问题。云网站应用级入侵防御系统(webapplicationfirewall,waf)的设计模式为基于机器学习的检测模型提供了卓越的应用场景,既满足现代云计算环境下大规模复杂系统的网络访问控制要求,又能提升网络的总体安全性。目前,针对sql注入攻击没有公开的数据源,对于有限样本的调参优化,虽然可以达到较好的测试效果,但是对于全网的大样本集可能存在一定的局限性。技术实现要素:有鉴于此,本发明的目的在于提出一种基于蜜罐系统的sql注入检测方法及装置。基于上述目的本发明提供的一种基于蜜罐系统的sql注入检测方法,包括:基于所述蜜罐系统部署的sql注入仿真环境,获取数据报文;基于所述数据报文,通过机器学习算法生成sql分类检测模型,并通过所述sql分类检测模型对后续获取的数据报文进行分类检测;基于专家系统对所述sql分类检测模型的分类检测结果进行重分类;基于所述重分类的结果更新所述sql分类检测模型的数据集,并获取新的数据报文;基于所述更新的数据集和所述新的数据报文对所述sql分类检测模型进行优化。在一实施例中,所述方法还包括:拦截收到的非sql注入攻击,并对所述蜜罐系统进行安全加固操作。所述基于所述数据报文,通过机器学习算法生成sql分类检测模型,包括:获取来访的超文本传输协议http协议数据包;提取所述http协议数据包的关键字段,得到目标分析文本;对所述目标分析文本进行特征提取,得到第一特征;对所述目标分析文本进行解码操作,得到可识别解码;对所述可识别解码进行特征提取,得到第二特征;对所述可识别解码进行降噪处理;对所述降噪处理之后的可识别解码进行特征提取,得到第三特征;基于所述第一特征、所述第二特征及所述第三特征合成得到特征向量;将所述特征向量作为数据集,通过所述机器学习算法对所述数据集进行训练,生成所述sql分类检测模型。在一实施例中,所述对所述可识别解码进行降噪处理,包括:对所述可识别解码进行贪婪删除内联注释处理;删除所述贪婪删除内联注释处理后的可识别解码中的非字母和非数字的字符。在一实施例中,所述基于专家系统对所述sql分类检测模型的分类结果进行重分类,包括:对所述sql分类检测模型的分类结果进行语法分析和词法分析;判断分析结果是否能够构成sql语法树;如果判断为是,则确定对应的分类结果为黑样本;如果判断为否,则对应的分类结果为白样本;判断分析结果是否存在非法指令;如果判断为是,则确定对应的分类结果为黑样本;如果判断为否,则确定对应的分类结果为白样本。本发明实施例还提供了一种基于蜜罐系统的sql注入检测装置,包括:获取模块,被配置为基于所述蜜罐系统部署的sql注入仿真环境,获取数据报文;分类检测模块,被配置为基于所述数据报文,通过机器学习算法生成sql分类检测模型,并通过所述sql分类检测模型对后续获取的数据报文进行分类检测;重分类模块,被配置为基于专家系统对所述sql分类检测模型的分类检测结果进行重分类;更新模块,被配置为基于所述重分类的结果更新所述sql分类检测模型的数据集,并获取新的数据报文;优化模块,被配置为基于所述更新的数据集和所述新的数据报文对所述sql分类检测模型进行优化。在一实施例中,所述装置还包括:拦截模块,被配置为拦截收到的非sql注入攻击,并对所述蜜罐系统进行安全加固操作。在一实施例中,所述分类检测模块包括:获取子模块,被配置为获取来访的超文本传输协议http协议数据包;第一提取子模块,被配置为提取所述http协议数据包的关键字段,得到目标分析文本;第二提取子模块,被配置为对所述目标分析文本进行特征提取,得到第一特征;解码子模块,被配置为对所述目标分析文本进行解码操作,得到可识别解码;第三提取子模块,被配置为对所述可识别解码进行特征提取,得到第二特征;处理子模块,被配置为对所述可识别解码进行降噪处理;第四提取子模块,被配置为对所述降噪处理之后的可识别解码进行特征提取,得到第三特征;合成子模块,被配置为基于所述第一特征、所述第二特征及所述第三特征合成得到特征向量;模型生成子模块,被配置为将所述特征向量作为数据集,通过所述机器学习算法对所述数据集进行训练,生成所述sql分类检测模型。在一实施例中,所述处理子模块包括:降噪子模块,被配置为对所述可识别解码进行贪婪删除内联注释处理;删除子模块,被配置为删除所述贪婪删除内联注释处理后的可识别解码中的非字母和非数字的字符。在一实施例中,所述重分类模块包括:分析子模块,被配置为对所述sql分类检测模型的分类结果进行语法分析和词法分析;第一判断子模块,被配置为判断分析结果是否能够构成sql语法树;如果判断为是,则确定对应的分类结果为黑样本;如果判断为否,则确定对应的分类结果为白样本;第二判断子模块,被配置为判断分析结果是否存在非法指令;如果判断为是,则确定对应的分类结果为黑样本;如果判断为否,则确定对应的分类结果为白样本。从上面所述可以看出,本发明提供的基于蜜罐系统的sql注入检测方法及装置,通过基于蜜罐系统获取的数据报文来生成sql分类检测模型,并进一步对分类检测结果进行重分类,根据重分类的结果来更新sql分类检测模型的数据集,并根据不短更新的数据集和新获取的数据报文来优化sql分类检测模型,矫正误报、漏报等负面影响,提高分类检测的精确度,并有效避免了基于规则的传统检测的弊端。附图说明图1为本发明实施例提供的基于蜜罐系统的sql注入检测方法的流程图;图2为本发明实施例提供的特征向量转换方法的流程图;图3为本发明实施例提供的基于专家系统的重分类方法的流程图;图4为本发明实施例提供的基于蜜罐系统的sql注入检测装置的结构示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。需要说明的是,本发明实施例中所有使用“第一”和“第二”的表述均是为了区分两个相同名称非相同的实体或者非相同的参量,可见“第一”“第二”仅为了表述的方便,不应理解为对本发明实施例的限定,后续实施例对此不再一一说明。图1为本发明实施例提供的一种基于蜜罐系统的sql注入检测方法的流程图,如图1所示,该方法实施于蜜罐系统中,可以包括如下步骤:步骤100、基于蜜罐系统部署的sql注入仿真环境,获取数据报文。在一实施例中,蜜罐是一个特殊的系统环境,通过域名系统(domainnamesystem,dns)解析等方式,搭建一些作为诱饵的主机、网络服务或者信息,构成多服务器集群的高交互sql注入仿真环境,从而能够诱使攻击方,例如网络空间的黑客,或者搜索爬虫等,对其发起入侵行为,包括攻击或深度探测。本实施例中的蜜罐主要包括web蜜罐,配置在公网环境中。在一实施例中,蜜罐系统所获取的数据报文包括攻击者对蜜罐系统进行攻击的恶意数据报文以及正常数据报文。例如,在谷歌蜜罐(googlehackhoneypot,ghh)中,通过暗链等形式,例如<ahref=http://yourdomain.com/honeypot.php?id=1>.</a>,设置“.”的颜色与网页背景相同,从而保证普通用户不会察觉,但是谷歌等搜索引擎爬虫会主动索引这些暗链,即达到了增强谷歌等搜索引擎索引该网站页面的效果,从而诱骗更多通过搜索引擎语法搜集攻击目标的攻击者对谷歌蜜罐发起攻击。在一实施例中,蜜罐系统获取数据报文的方式主要包括两种,一种是通过日志进行收集,一种是通过数据库进行收集,收集的数据项如表1所示。表1字段简介id记录日志条数data_allhttp协议待检测项(url+header属性值+数据体)vectordata_all对应的特征向量flag_white是否为sql注入样本flag_binary是否错误分类x_ip客户端ip地址time流量访问时间步骤200、拦截受到的非sql注入攻击,并对蜜罐系统进行安全加固操作。本实施例中,为保护蜜罐系统自身的安全性,可以对蜜罐系统进行安全加固与防御工作。一方面,可以通过防火墙等工具从流量层面进行拦截,以禁止非sql注入之外的恶意攻击流量流入蜜罐系统,防止sql注入仿真环境沦陷,并保证后期样本集的纯净度;另一方面,可以对蜜罐系统自身web服务及其相关组件进行权限加固、补丁升级等安全操作。该安全操作可包括对蜜罐的操作系统、网络设备、服务器、数据库进行安全加固,确保正确的访问控制权限及服务配置的安全性,并升级相关组件为最新版本,及时更新漏洞补丁,以免受历史漏洞的侵害。步骤300、基于已获取的标准数据报文确定sql分类检测模型,基于分类检测模型对后续获取的数据报文进行分类检测。本实施例中,通过http协议对数据报文进行解析,将获取的标准http数据报文转换为机器学习算法可识别的特征向量,然后通过标准化的训练和测试,形成基于机器学习算法的sql分类检测模型,并将该检测模型部署到线上,进行sql注入黑白样本的分类检测操作,从而识别出恶意sql注入攻击。在一实施例中,分类检测依靠机器学习算法来执行,首先对蜜罐系统的来访流量进行文本筛选、特征工程的预处理操作,然后通过sql分类检测模型对流量对应的特征向量进行分类操作,分类结果为是否是sql注入恶意攻击流量。具体而言,本实施例通过下述步骤将标准http数据报文转换为机器学习算法可以识别的特征向量,如图2所示,为本发明实施例提供的特征向量转换方法的流程图,包括以下步骤:步骤301、获取来访的http协议数据包。在一实施例中,获取的http协议数据包,不仅包含get、post类型的数据包,还包括通过head方法、options等方法获取的数据包。步骤302、对获取的http协议数据包进行关键字段的提取和处理。其中,所提取的关键字段可以包括数据体和部分可携带攻击载荷的httpheader值,例如cookie等,所提取的关键字段构成字符串,或者可以称为目标分析文本。步骤303、对目标分析文本进行特征提取,得到第一特征。在一实施例中,提取的第一特征如表2所示。表2步骤304、对上一步骤中提取的目标分析文本进行循环url解码,得到可识别解码。在一实施例中,由于所获取的http协议数据包流量是默认经过url编码的,因而需要进行url解码的操作。另外对于部分变种文本采取多重url编码,为避免编码干扰,故采取循环url解码对其进行解码,经过解码操作之后,得到可识别的解码,例如hex、asc2、bin、mid、char、base64。步骤305、对可识别解码进行特征提取,得到第二特征。在一实施例中,第二特征如表3所示。表3步骤306、对可识别解码进行降噪处理。在一实施例中,降噪处理即贪婪删除内联注释,通过采用正则匹配的贪婪模式对可识别解码进行数据清洗工作。进一步地,可以对可识别解码进行再次降噪处理。该步骤的降噪处理主要包括删除所有非字母和非数字的字符,例如%等,以便排除特殊字符对特征提取的干扰。步骤307、对两次降噪处理之后的可识别解码进行特征提取,得到第三特征。在一实施例中,第三特征如表4所示。表4步骤308、对第一特征、第二特征和第三特征进行特征差异值的计算,得到对应于http协议数据包的特征向量。由于对可识别解码进行的降噪处理有可能将关键字清洗掉,而该关键字对构建分类检测模型又至关重要,因而在一实施例中,将第一特征、第二特征以及第三特征进行混合,从而得到机器学习算法可以识别的特征向量。该特征向量一部分作为数据集中的训练集,用于通过基于机器学习算法的训练生成sql分类检测模型,另一部分特征向量作为数据集中的测试集,用于对生成的sql分类检测模型进行测试。步骤400、基于专家系统对sql分类检测模型的分类结果进行重分类。由于sql分类检测模型是基于已获取的数据报文来构建的,而蜜罐系统还在继续获取数据报文,因而sql分类检测模型对于后续获取的数据报文不能够保证分类精度。因而本实施例中,一方面,可以通过蜜罐系统自身的作用,不断收集新的数据报文样本;另一方面则通过蜜罐系统中的专家系统,对分类检测模型的分类结果进行斧正的错分类样本的迭代更新。本实施例中,通过专家系统的重分类,能够优化sql分类检测模型,以矫正误报、漏报等负面影响,通过专家系统的又一轮的鉴别,重点将错分的数据进行重新归类,并基于重分类结果,收集更多此类样本,从而能够丰富sql分类检测模型的数据集。如图3所示,为本发明实施例提供的基于专家系统的重分类方法的流程图,本发明通过下述步骤进行重分类:步骤401、对黑样本和白样本进行语法分析和词法分析。其中,黑样本即被sql分类检测模型分类为恶意sql注入攻击的样本,白样本即被sql分类检测模型分类为正常的样本。步骤402、判断分析结果是否构成sql语法树,如果判断为是,执行步骤403,如果判断为否,执行步骤404。在一实施例中,可以基于词法分析的基础,从整个语句的结构着手分析,判断输入序列是否符合文法规则,如果判断为是,则构成sql语法树。步骤403、判断该分类结果为黑样本。步骤404、判断该分类结果为白样本。步骤405、判断分析结果是否存在非法指令,如果判断为存在非法指令,则执行步骤403;如果判断为否,则执行步骤404。在一实施例中,非法指令包括诸如union,select等,可以通过比对的方式判断是否存在非法指令。举例而言,专家系统首先遍历数据库日志记录,对于flag_white被标记为白样本的data_all字段重点进行词法分析,排查是否存在非法sql注入指令,诸如union,select等等,如判断为存在非法sql注入指令,则重新标记flag_white为黑样本,并标注错分类标志flag_binary为true;对于flag_white被标记为黑样本的data_all字段重点进行语法分析,即基于词法分析的基础,从整个语句的结构着手分析,若输入序列全部符合文法规则,即可生成对应的语法树结构,即为黑样本,如发现不构成sql语法树结构,则将flag_white重新标记为白样本,并标注分类标志flag_binary为true,将数据归入线下迭代增量训练的数据集中。步骤500、基于重分类后的分类结果对应的特征向量更新数据集,获取新的数据报文,根据更新后的数据集和新的数据报文对sql分类检测模型进行优化。在一实施例中,通过线下特征工程处理以及对于机器学习算法的调参优化,训练生成各性能指标更优的分类检测模型,替换之前的sql分类检测模型,循环迭代,以实现长期优化。图4为本发明实施例提供的基于蜜罐系统的sql注入检测装置的结构示意图,如图4所示,该装置包括:获取模块110、分类检测模块120、重分类模块130、更新模块140以及优化模块150。其中,获取模块110,被配置为基于所述蜜罐系统部署的sql注入仿真环境,获取数据报文;分类检测模块120,被配置为基于所述数据报文,通过机器学习算法生成sql分类检测模型,并通过所述sql分类检测模型对后续获取的数据报文进行分类检测;重分类模块130,被配置为基于专家系统对所述sql分类检测模型的分类检测结果进行重分类;更新模块140,被配置为基于所述重分类的结果更新所述sql分类检测模型的数据集,并获取新的数据报文;优化模块150,被配置为基于所述更新的数据集和所述新的数据报文对所述sql分类检测模型进行优化。在一实施例中,该装置还可以包括:拦截模块,被配置为拦截收到的非sql注入攻击,并对所述蜜罐系统进行安全加固操作。在一实施例中,分类检测模块可以包括:获取子模块,被配置为获取来访的超文本传输协议http协议数据包;第一提取子模块,被配置为提取所述http协议数据包的关键字段,得到目标分析文本;第二提取子模块,被配置为对所述目标分析文本进行特征提取,得到第一特征;解码子模块,被配置为对所述目标分析文本进行解码操作,得到可识别解码;第三提取子模块,被配置为对所述可识别解码进行特征提取,得到第二特征;处理子模块,被配置为对所述可识别解码进行降噪处理;第四提取子模块,被配置为对所述降噪处理之后的可识别解码进行特征提取,得到第三特征;合成子模块,被配置为基于所述第一特征、所述第二特征及所述第三特征合成得到特征向量;模型生成子模块,被配置为将所述特征向量作为数据集,通过所述机器学习算法对所述数据集进行训练,生成所述sql分类检测模型。在一实施例中,处理子模块可以包括:降噪子模块,被配置为对所述可识别解码进行贪婪删除内联注释处理;删除子模块,被配置为删除所述贪婪删除内联注释处理后的可识别解码中的非字母和非数字的字符。在一实施例中,重分类模块包括:分析子模块,被配置为对所述sql分类检测模型的分类结果进行语法分析和词法分析;第一判断子模块,被配置为判断分析结果是否能够构成sql语法树;如果判断为是,则确定对应的分类结果为黑样本;如果判断为否,则确定对应的分类结果为白样本;第二判断子模块,被配置为判断分析结果是否存在非法指令;如果判断为是,则确定对应的分类结果为黑样本;如果判断为否,则确定对应的分类结果为白样本。本实施例提供的基于蜜罐系统的sql注入检测方法及装置,从数据集和模型调参两个方面进行优化:一方面通过不断更新的数据集可重新调参,能够训练生成性能更优的分类检测模型;二方面通过专家系统斧正的错分类数据集进行增量训练,从而能够生成性能更优的分类检测模型,提高分类检测的精确度,并有效避免了基于规则的传统检测的弊端。所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明的不同方面的许多其它变化,为了简明它们没有在细节中提供。另外,为简化说明和讨论,并且为了不会使本发明难以理解,在所提供的附图中可以示出或可以不示出与集成电路(ic)芯片和其它部件的公知的电源/接地连接。此外,可以以框图的形式示出装置,以便避免使本发明难以理解,并且这也考虑了以下事实,即关于这些框图装置的实施方式的细节是高度取决于将要实施本发明的平台的(即,这些细节应当完全处于本领域技术人员的理解范围内)。在阐述了具体细节(例如,电路)以描述本发明的示例性实施例的情况下,对本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下或者这些具体细节有变化的情况下实施本发明。因此,这些描述应被认为是说明性的而不是限制性的。尽管已经结合了本发明的具体实施例对本发明进行了描述,但是根据前面的描述,这些实施例的很多替换、修改和变型对本领域普通技术人员来说将是显而易见的。例如,其它存储器架构(例如,动态ram(dram))可以使用所讨论的实施例。本发明的实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1