基于NvidiaTX2的CPU、GPU联合调频节能优化方法与流程
本发明涉及嵌入式平台的功耗优化技术领域,具体地涉及一种基于nvidiatx2的cpu、gpu联合调频节能优化方法。
背景技术:
由于嵌入式平台所处的工作环境中各种资源往往都受限,所以人们在使用嵌入式平台时通常需要额外关注其功耗情况。现有的嵌入式平台的功耗优化技术主要有两类:
动态功耗管理(dynamicpowermanagement,简称dpm);
动态电压频率调节技术(dynamicvoltageandfrequencescaling,简称dvfs)。
dpm技术的出发点是在满足系统实时性的要求下,根据系统的动态负载,尽可能地让系统进入睡眠模式,以减小系统静态功耗。一般而言,处理器可以有normal、idle、sleep这三种工作模式,3个工作模式对应的功耗分别为pn、pi、ps,并且有pn>pi>ps,当系统有任务需要处理时,系统处于normal状态并全速处理任务,否则处于idle或者sleep状态以达到节能的目的。
dvfs技术则是降低嵌入式系统功耗的另一个手段。通过动态监控系统负载,在满足实时约束的条件下,可以适当降低时钟频率并延长任务执行时间,从而达到降低系统功耗的目的。在实时系统中,dvfs技术是通过任务的紧迫程度来动态调节处理器的运行电压和频率,在保证任务完成的时间不低于其截止时间的前提下,使得处理器不总是以最高频率运行,从而有效地减少cpu的能量消耗。
下面主要对dvfs技术进行介绍。
dvfs技术即动态电压频率调整,是减低系统功耗的一种技术。dvfs技术实际上是一种功耗与性能的折衷的方法,即在不影响性能和用户体验的情况下,尽量降低工作频率。dvfs技术主要是用来降低系统的动态功耗,这项技术基于的基本理论基础是cmos电路的动态功耗,coms电路的动态功耗可以由式1-1表示:
要想降低系统的动态功耗,我们可以降低cl负载电容,降低vdd供电电压,降低f电路工作频率。在工艺因素一致的情况下,调整供电电压和工作频率可以降低功耗,事实上,如果单纯的降低频率,系统的相应时间会变大,理想情况下,f*t是一个定值,其中t是执行时间。但是,由于频率的降低往往会伴随着电压的降低,电压与频率成正比关系,频率的降低导致的供电电压的降低与动态功耗成二次方的影响关系,所以总体上系统的动态功耗会降低,这既是称为动态电压频率调整的原因,供电电压和工作频率是相互联系的。dvfs技术中选择合适的工作频率是非常重要的,在这个频率工作下应该满足最低的性能需求。
传统的dvfs技术主要针对cpu进行调频。不过现在嵌入式计算平台为了满足深度神经网络计算的需要,往往在平台上增加了gpu来进行深度神经网络的推理工作。这部分工作需要的资源非常大,以至于gpu的功率可能会超过cpu,成为嵌入式计算平台上功耗消耗最大的部件。
nvidiajetsontx2是一款高速高效的嵌入式ai计算平台。这款7.5w的嵌入式ai计算平台带来了真正的边缘计算能力。它具有一个nvidiapascal系列gpu、一个8gb内存和速度高达59.7gb/s的内存带宽。同时它也有两个cpu,分别为双核的dever架构以及四核的arm架构。
tx2主要用于边缘计算领域,而资源受限是边缘计算的一大特征。通过对tx2执行ai运算任务时的功耗进行优化,可以让tx2在实际使用时发挥更大的作用。
不过,现有的面向多核异构嵌入式平台的功耗优化主要还是对cpu的调频,没有考虑到gpu本身的功耗可能会超过cpu称为嵌入式系统中功耗消耗最大的部件。作为一个嵌入式ai计算平台的tx2,其主要任务是利用深度神经网络来进行各种ai推理工作,主要的执行部件为gpu。本发明因此而来。
专利文献cn106258011a公开了一种用于降低图形帧处理中的功耗的cpu/gpudcvs协同优化方法,接收cpu活动数据和gpu活动数据;确定gpu和所述cpu的可用的动态时钟和电压/频率缩放(dcvs)水平的集合;以及基于cpu和gpu活动数据,从可用的dcvs水平的集合中选择gpudcvs水平和cpudcvs水平的最优组合,使得cpu和所述gpu的组合功耗最小化。该方法计算量大,无法让所有部件都工作在最高效的状态,不能适用于nvidiatx2嵌入式ai计算平台。
技术实现要素:
为了解决上述技术问题,本发明提出了一种基于nvidiatx2的cpu、gpu联合调频节能优化方法,对已有的dvfs动态调频技术做拓展,将gpu的运行频率也纳入调频的范围,根据任务量,推算出当前gpu任务的结束时间,在满足时限要求的前提下,调整cpu、gpu频率,使得所有部件都工作在最高效的状态,从而降低整个任务执行所需要的功耗。
本发明所采用的技术方案是:
一种基于nvidiatx2的cpu、gpu联合调频节能优化方法,包括nvidiatx2嵌入式计算平台的gpu部件,具体执行以下步骤:
s01:获取一段时间的gpu使用率,并与设定的阈值比较,若大于设定阈值,则判断gpu处于计算状态;
s02:若判断gpu处于计算状态,根据gpu处理对象信息,设定任务完成的最迟时间tlimit;
s03:根据当前频率下的处理速度计算任务完成需要的时间;
s04:将估算时间与设定的最迟时间tlimit进行比较,若大余tlimit,增加cpu、gpu工作频率,执行步骤s03;
s05:若小于最迟时间tlimit,计算实时功率,将实时功率与最高效功率设定范围比较,若实时功率小于最高效功率设定范围最小值,增加cpu、gpu工作频率,执行步骤s03,直到实时功率处于最高效功率设定范围内;
s06:若实时功率大于最高效功率设定范围最大值,降低cpu、gpu工作频率,执行步骤s03,直到实时功率处于最高效功率设定范围内。
优选的技术方案中,所述步骤s03中处理速度通过将gpu最大处理速度vmax按照比例转换,得到当前频率组合下的处理速度vn。
优选的技术方案中,所述步骤s04还包括,在调频达到动态稳定后,当gpu计算结束时,降低cpu、gpu频率至低功耗状态。
本发明还公开了一种基于nvidiatx2的cpu、gpu联合调频节能优化系统,包括nvidiatx2嵌入式计算平台的gpu部件,还包括:
gpu状态计算模块,获取一段时间的gpu使用率,并与设定的阈值比较,若大于设定阈值,则判断gpu处于计算状态;
阈值设定模块:若判断gpu处于计算状态,根据gpu处理对象信息,设定任务完成的最迟时间tlimit;
时间估算模块,根据当前频率下的处理速度计算任务完成需要的时间;
调频模块,将估算时间与设定的最迟时间tlimit进行比较,若大余tlimit,增加cpu、gpu工作频率;
动态若调频模块,若小余于最迟时间tlimit,计算实时功率,将实时功率与最高效功率设定范围比较,若实时功率不在最高效功率设定范围内,增加或降低cpu、gpu工作频率,直到实时功率在最高效功率设定范围内。
优选的技术方案中,所述时间估算模块中处理速度方法包括,通过将gpu最大处理速度vmax按照比例转换,得到当前频率组合下的处理速度vn。
优选的技术方案中,所述动态若调频模块还包括,在调频达到动态稳定后,当gpu计算结束时,降低cpu、gpu频率至低功耗状态。
与现有技术相比,本发明的有益效果是:
本发明针对具有gpu部件的nvidiatx2嵌入式计算平台,对已有的dvfs动态调频技术做拓展,将gpu的运行频率也纳入调频的范围,根据任务量,推算出当前gpu任务的结束时间,在满足时限要求的前提下,调整cpu、gpu频率,使得所有部件都工作在最高效的状态,从而降低整个任务执行所需要的功耗。可以提升该嵌入式平台在执行专用gpu运算任务时的能效比。
附图说明
下面结合附图及实施例对本发明作进一步描述:
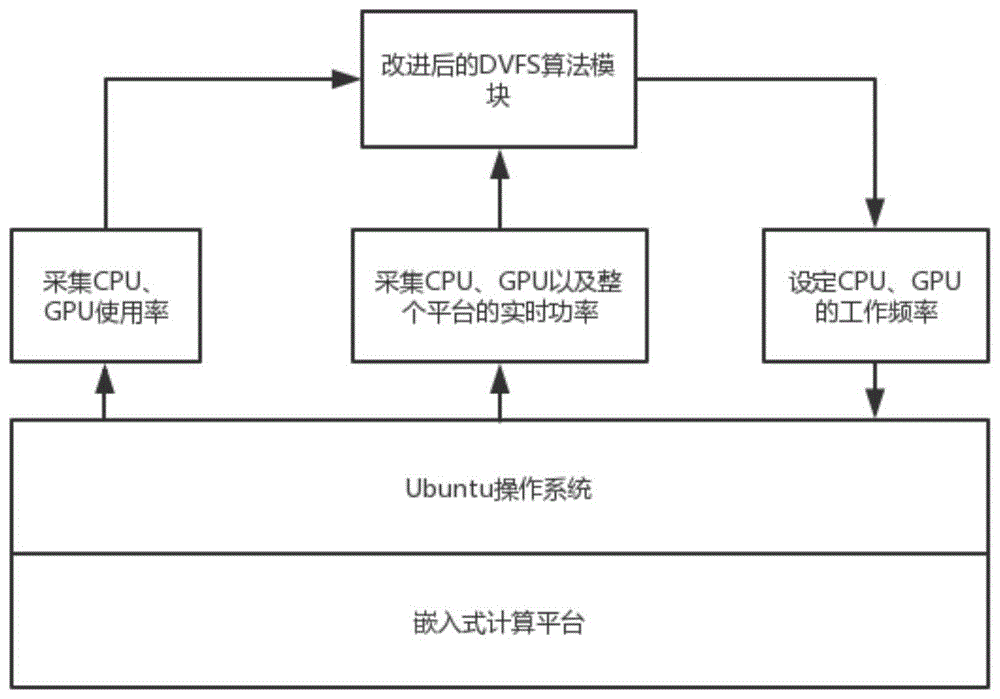
图1为本发明基于nvidiatx2的cpu、gpu联合调频节能优化系统的功能结构图;
图2为本发明基于nvidiatx2的cpu、gpu联合调频节能优化方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
实施例
如图1所示,本发明对已有的dvfs动态调频技术做拓展,将gpu的运行频率也纳入调频的范围,根据任务量,推算出当前gpu任务的结束时间,在满足时限要求的前提下,调整cpu、gpu频率,努力让所有部件都工作在最高效的状态,从而降低整个任务执行所需要的功耗。
nvidiajetsontx2自带ubuntu16.04操作系统。通过linux操作系统的虚文件系统,可以得到cpu、gpu以及整个计算平台的输入功耗。同样,对cpu、gpu的调频工作也可以通过虚文件系统提供的接口来实现。本实施例中的方案,用户算法和操作系统的接口是通过linux操作系统的虚文件系统来完成的。
如图2所示,在本实施例中,我们选择整片dvfs。dvfs技术最重要的是调频策略的选择。在本方案中,gpu上运行的任务是整个计算平台的核心任务。因此在制定调频策略时,需要首先保证gpu上的计算任务能够在要求的时限内完成。我们将gpu在过去某段时间内使用率作为一个触发调频策略的起点。当gpu使用率低于一个明显的标志着gpu处于运行作业状态的下限时,我们降低cpu以及gpu的工作频率,让这两个部件处于低功耗状态。当gpu使用率持续上升,达到预先设置的阶梯值时,则提高频率以满足性能要求。
频率的提高意味着功耗的提高,根据英伟达的官方文档,当tx2系统的整体功耗在7.5w时,平台的处理效率最高。因此我们可以指定如下的调频策略:
1、当前功耗低于7.5w,并且任务预估完成时间点提前于所要求的最迟完成点tlimit时,可以将cpu、gpu频率进一步提高,到接近7.5w的最高效率点;本实施例中的接近7.5w的最高效率点为,处于最高效功率点设定范围内,例如,以7.5w的上下5%范围内为例进行说明。
2、当功耗接近7.5w,而当前任务预估完成时间无法满足时限要求时,可以进一步提升cpu、gpu工作频率,直到能够满足时限要求。
对于任务完成时间的预估,我们采取下述原理:
对于某一个ai应用来说,处理的对象总是一组数据,只不过数据的组织形式可能不同,有的是图片数据有的是文本数据。gpu在处理数据时,总是按照程序设定的要求,每次读入固定量的数据到gpu显存中。我们设处理的数据总量为s,设gpu在最高频率时的处理速率为vmax,因此可以事前计算出处理s数据量时需要的最少时间
再根据实际测量出的tmin反算出vmax,这样,知道了gpu的最大处理速度,我们就可以将vmax转换为当前频率组合下的处理速度v,根据这个v来预估所需要的处理时间。
总结该算法的流程:
1、读取最近一段时间的gpu使用率p;
2、根据p的大小是否大于某个门槛值,来判断gpu是否在执行运算任务;
3、若判断gpu在执行任务,则读取当前gpu处理对象的信息,得到待处理文件的大小s,记录任务开始时间t0,设定任务最迟完成时间tlimit;
4、将gpu最大处理速度vmax按照比例转换为当前频率下的处理速度vn,判断以当前速率是否能在tlimit之前完成任务;
5、若不能满足时限要求,则增加cpu、gpu工作频率,再次执行步骤4;
6、若能满足时限要求,但是整体功耗小于7.5*0.95=7.125w(nvidia官方手册中说明当全局功耗为7.5w时gpu效率最高),则增加cpu、gpu频率,直到达到7.5w上下5%;
7、若整体功耗大于7.5*1.05=7.875w,则降低cpu、gpu频率,直到达到7.5w上下5%;
8、在调频达到动态稳定之后,等待gpu任务结束,降低cpu、gpu频率至低功耗状态。
在算法的每一步都需要检查以下的边界条件:
1、频率不得超过最大限定值;
2、频率不得低于最小正常运行频率;
3、功率不得超过最大功率。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!