一种基于通道分离型卷积的快速人脸检测模型的制作方法
本发明涉及人脸识别技术领域,尤其涉及一种基于通道分离型卷积的快速人脸检测模型。
背景技术:
人脸检测常应用于视频监控,机器人视觉等领域。它要求算法实时性强,并且要有较高的准确率和较低的内存占用率。传统的人脸检测算法一般是基于boosting算法或者dpm模型。近年来,随着深度学习在计算机视觉领域的成功,基于卷积神经网络的方法也渐渐地被应用于人脸检测的任务中。现存人脸检测算法大多数要么准确率高,但是速度慢,要么速度快,但是准确率低。且大多数基于深度学习模型的人脸检测算法结构过于复杂。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种基于通道分离型卷积的快速人脸检测模型,以解决现有技术的不足。
为实现上述目的,本发明提供了一种基于通道分离型卷积的快速人脸检测模型,包括以下步骤:
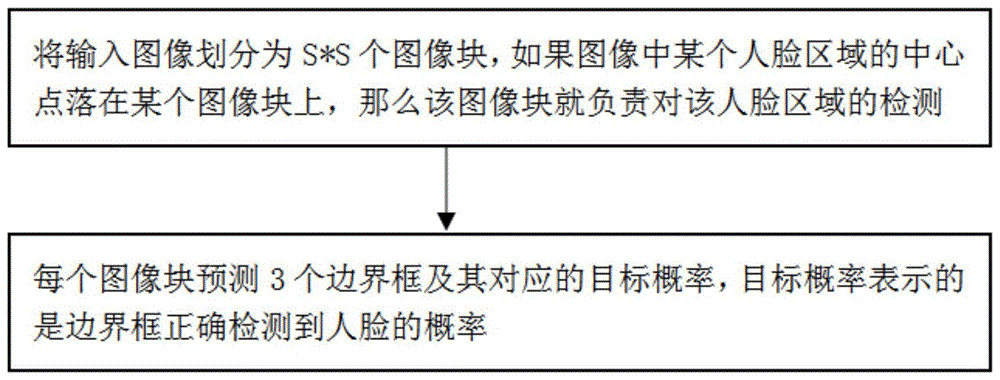
步骤1、将输入图像划分为s*s个图像块,如果图像中某个人脸区域的中心点落在某个图像块上,那么该图像块就负责对该人脸区域的检测;
步骤2、每个图像块预测3个边界框及其对应的目标概率,目标概率表示的是边界框正确检测到人脸的概率,将目标概率定义为p(目标)*iou,若人脸区域的中心点落在预测边界框内,则p(目标)=1,否则为0;iou表示的是预测边界框与真值边界框的交并比。
进一步地,所述每个预测边界框要预测的的内容包括:x,y,w,h和目标概率c,其中(x,y)表示的是预测边界框的相对中心坐标,而w和h表示的是边界框的相对宽和高,目标概率表示的是预测边界框与真值边界框的交并比。
进一步地,所述3个边界框中,与真值边界框交并比最大的那个边界框负责对人脸的检测。
进一步地,所述与真值边界框交并比最大的那个边界框负责对人脸的检测采用的损失函数如下:
其中,当第i个图像块中的第j个边界框负责对人脸的检测时,
进一步地,所述模型利用通道分离型卷积,通道分离型卷积中卷积核的深度为1,卷积核分别对输入特征图的每个通道进行卷积,得到输出特征图对应的通道,之后再用卷积核对得到的输出特征图进行各通道信息的融合。
进一步地,所述模型包括20个卷积层和4个最大池化层。
本发明的有益效果是:
本发明所提人脸检测模型利用通道分离型卷积的设计大大减少了整个检测网络的参数量和计算复杂度,从而提升了网络的人脸检测速度。此外,本发明提出的人脸检测模型基于全局信息进行预测,并且利用多个3*3和1*1的卷积层的组合对输入图片进行特征提取,因此能够提升人脸检测的精度。总之,本发明所提人脸检测模型在提升人脸检测速度的同时能够保证较高的人脸检测准确率。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
图1是本发明的流程图。
具体实施方式
如图1所示,本发明的一种基于通道分离型卷积的快速人脸检测模型通过整幅图像的特征来实现对人脸边界框的预测。首先该人脸检测方法将输入图像划分为s×s个图像块,如果图像中某个人脸区域的中心点落在某个图像块上,那么该图像块就负责对该人脸区域的检测。每个图像框预测3个边界框及其对应的目标概率。目标概率表示的是边界框正确检测到人脸的概率。一般来说,将目标概率定义为p(目标)*iou(truth,predict)。若人脸区域的中心点落在预测边界框内,则p(目标)=1,否则为0。iou(truth,predict)表示的是预测边界框与真值边界框的交并比。
每个预测边界框要预测的的内容包括:x,y,w,h和目标概率c。其中(x,y)表示的是预测边界框的相对中心坐标。而w和h表示的是边界框的相对宽和高。而目标概率在之前已经提过,表示的是交并比。
本发明提出的模型最终预测的结构为一个s×s×(3*5)维度的向量。其中3表示的是边界框的数量,5指的是x,y,w,h和目标概率这5个值。
本发明提出的模型结合了全卷积网络与通道分离型卷积的结构,使得网络整体参数大大减少,检测速度提高,与此同时保持较高的人脸检测的精确度。
一般的基于深度学习的人脸检测网络最后两层采用的是全连接层做位置预测,这使得输出特征图中的每一个神经元与输入特征图所有神经元相连,因此参数量大大增加,网络计算花费大,运行速度慢。本发明提出的模型将最后两层全连接层用一个1x1的卷积层代替,从而大大减少网络的参数量,提升模型运行速度。
此外,本发明提出的模型还利用通道分离型卷积来减少模型的计算复杂度。一般来说,标准型卷积中卷积核的深度与输入特征图的通道数是一致的,而通道分离型卷积中卷积核的深度为1,卷积核分别对输入特征图的每个通道进行卷积,得到输出特征图对应的通道。之后,再用1×1的卷积核对前面得到的输出特征图进行各通道信息的融合。
本发明提出的深度人脸检测网络结构如下表所示,它包括20个卷积层和4个最大池化层。当输入图片的尺寸为448×448×3时,最后一层卷积层输出的是一个7×7×15的张量。其中7*7对应的是输入图片划分的7*7个图像块,15对应的是每个图像块预测的3个边界框的x,y,w,h和目标概率c。
在训练检测网络时,通过求出损失函数的梯度,利用梯度下降法对网络参数进行更新,从而求出最优的网络模型。
在本发明提出的人脸检测模型中,输入图像会被划分为s×s个图像块,每个图像块中设定3个待预测的边界框。而这3个边界框中,与真值边界框交并比最大的那个边界框负责对人脸的检测。
本发明所使用的损失函数如下:
1、
其中,当第i个图像块中的第j个边界框负责对人脸的检测时,
当通过损失函数、梯度下降和训练样本对检测网络完成训练,使得其参数最优化时,就可以实现对人脸的快速检测。将一张含有人脸的图片输入训练好后的检测模型,即可得到预测的人脸边界框的中心坐标,长和宽度的大小及其目标概率值。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!