基于中医古籍文献的中医命名实体识别方法及识别系统与流程
本发明属于信息处理与中医文献领域,具体涉及一种基于中医古籍文献的中医命名实体识别方法及识别系统。
背景技术:
传统中医学博大精深,中医的传播一方面通过老一辈医疗工作者的直接经验传递,另一方面是文献。在中医文献中,保存了大量的中医古籍医案,其中包含了众多的名老中医经验和诊疗方法。这里提到的中医古籍医案就是指古代中医治疗疾病时对病人有关的症状、病因、方剂、用药等做的连续记录。其中,中医命名实体就是指中医古籍医案中对病人疾病进行阐述重现的症状、方剂、用药等信息实体。为了更好的利用包括中医古籍医案在内的中医文献,中医命名实体识别是中医领域相关研究的重要前提。
当前命名实体识别在一些常见的实体类型(如人名、地名、机构名等)上的研究已经获得了很好的结果,基本都接近了人工标注水平。然而,中医古籍文献与其他文献在用词和语法上都有很大的不同,具有自己的特色,现有技术中的命名实体识别方法应用到中医古籍医案上,无法得到理想的效果。同时中医古籍医案中存在很多比较棘手的文法现象,导致人工标注也变得困难与昂贵,进一步加大了中医命名实体识别的难度。
技术实现要素:
本发明要解决的技术问题针对现有技术中尚无有效的中医命名实体的识别方法,提供一种基于中医古籍文献的中医命名实体识别方法及识别系统,结合现有的语言训练模型,如google提出的语言模型预训练方法bert,得到面向中医古籍文献的命名实体识别方法,实现对中医古籍文献,尤其是中医古籍医案的有效利用。
为解决上述技术问题,本发明实施例提供一种基于中医古籍文献的中医命名实体识别方法,所述方法包括如下步骤:
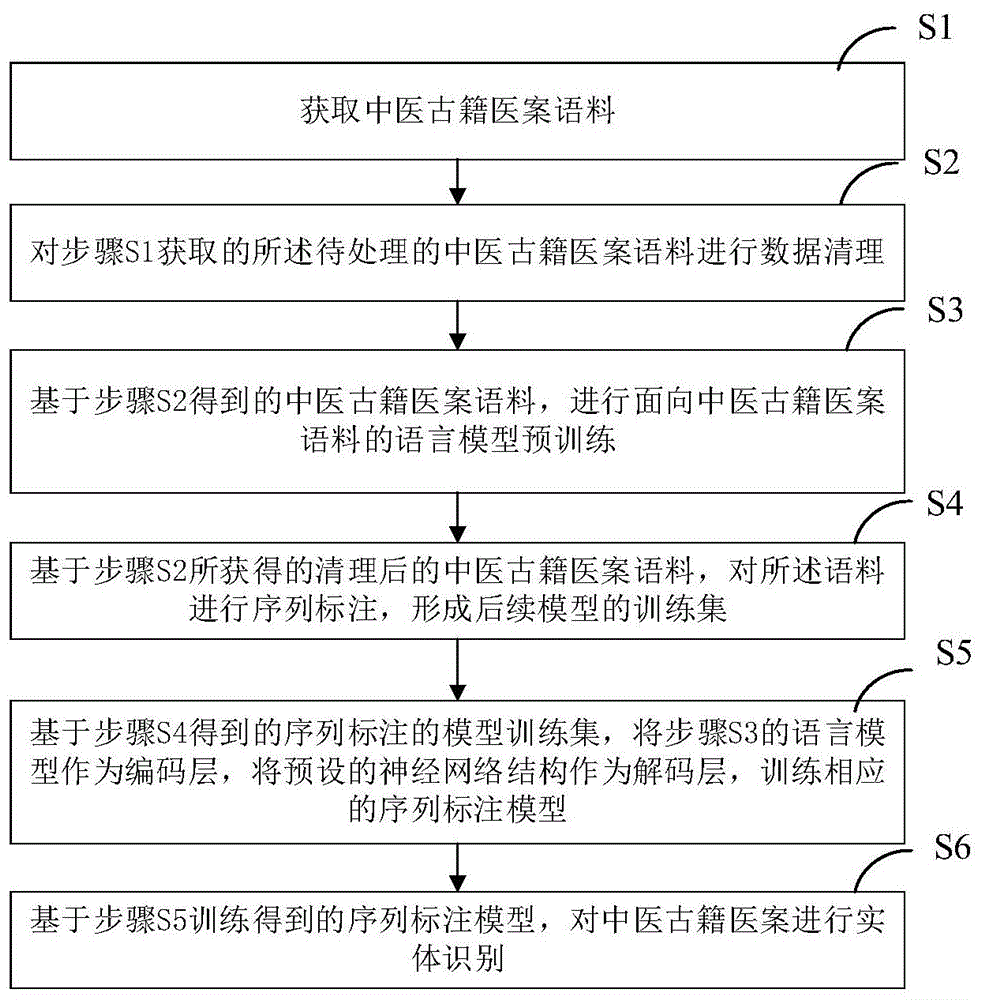
步骤s1,获取中医古籍医案语料;
步骤s2,对步骤s1获取的所述待处理的中医古籍医案语料进行数据清理;
步骤s3,基于步骤s2得到的中医古籍医案语料,进行面向中医古籍医案语料的语言模型预训练;
步骤s4,基于步骤s2所获得的清理后的中医古籍医案语料,对所述语料进行序列标注,形成后续模型的训练集;
步骤s5,基于步骤s4得到的序列标注的模型训练集,将步骤s3的语言模型作为编码层,将预设的神经网络结构作为解码层,训练相应的序列标注模型;
步骤s6,基于步骤s5训练得到的序列标注模型,对中医古籍医案进行实体识别。
上述方案中,所述步骤s1获取中医古籍医案语料,具体包括以下步骤:
步骤s11,利用光学字符识别对已有的纸质版中医古籍医案书籍进行扫描识别,形成电子文本语料;
步骤s12,利用开源网络爬虫从网络上抓取没有纸质版书籍的中医古籍医案语料;
步骤s13,将步骤s11和步骤s12获取到的语料文本进行对比、合并,最终形成统一的待处理的中医古籍医案语料。
上述方案中,所述步骤s2对待处理的中医古籍医案语料进行数据清理,具体包括以下步骤:
步骤s21,校正错别字;
步骤s22,过滤无关语句。
上述方案中,步骤s3中所述语言模型预训练,具体包括以下步骤:
步骤s31,下载语言模型预训练中文语言训练的源码;
步骤s32,人工整理中医古籍医案涉及到的字表,与源码中的中文字表对比,切分出中医领域的生僻字表;
步骤s33,以生僻字表中的字符代替源码中使用频率低的字符的方式,将所述生僻字表与中文字表合并,并保证中文字表的长度不变;
步骤s34,对步骤s2清理后的中医古籍医案语料中的段落进行分段,预设段落长度阈值和/或段落包含句子数量阈值,将大于所述段落长度阈值和/或段落包含句子数量阈值的段落文本,作为语言训练模型的训练语料;
步骤s35,利用按字符分隔的分词规则替换源码中的分词方法,基于中文语言训练模型,以所下载的语言模型预训练方法在所述步骤s34中的语言训练模型的训练语料上进行面向中医古籍医案的语言模型预训练。
上述方案中,步骤s3,所述语言模型预训练,采用google的语言模型预训练方法bert。
上述方案中,所述语言模型预训练,具体包括:
步骤s31,下载google开源的基于bert训练的中文语言模型chinese_l-12_h-768_a-12以及bert的源码;
步骤s32,与google开源的中文字表对比,切分出中医领域独特的生僻字表;
步骤s33,将google开源的中文字表与所述生僻字表合并,合并时以生僻字表替换中文字表中使用频率低的字符,以保证字表长度不变;
步骤s34,对步骤s2清理后的中医古籍医案语料中的段落进行分段,预设段落长度阈值和/或段落包含句子数量阈值,将大于所述段落长度阈值和/或段落包含句子数量阈值的段落文本,作为语言训练模型的训练语料;
步骤s35,利用按字符分隔的分词规则替换bert源码中的分词方法,基于google开源的中文语言模型,利用bert预训练方法在步骤s34切分出的训练语料上进行面向中医古籍医案的语言模型预训练。
上述方案中,步骤s4中所述形成后续模型训练集,通过对所述中医古籍医案语料进行bioes形式的序列标注而形成。
上述方案中,所述对中医古籍医案语料进行bioes形式的序列标注,具体包括以下步骤:
步骤s41,选取实体识别类型;
步骤s42,约定标注规则;
步骤s43,从清理后的语料中随机选取预定规模的句子集合,按字符分隔写入待标注文件,句子间以一空行分隔;
步骤s44,基于选取的实体识别类型及约定的标注规则,对选取的预定规模的句子集合进行人工标注。
上述方案中,所述实体类型分别为:症状zz、脉象mx、舌象sx、中药zy、剂量jl、方剂fj。
本发明实施例还提供了一种基于中医古籍文献的中医命名实体识别系统,所述系统包括:语料获取模块、数据清理模块、语言模型预训练模块、训练集标注模块、序列标注模型训练模块、实体识别模块;其中,
所述语料获取模块用于获取中医古籍医案语料;
所述数据清理模块用于对获取的所述待处理的中医古籍医案语料进行数据清理;
所述语言模型预训练模块用于基于中医古籍医案语料,进行面向中医古籍医案语料的语言模型预训练;
所述训练集标注模块用于基于清理后的中医古籍医案语料,对所述语料进行序列标注,形成后续模型的训练集;
所述序列标注模型训练模块用于基于序列标注的模型训练集,将语言模型作为编码层,将预设的神经网络结构作为解码层,训练相应的序列标注模型;
所述实体识别模块用于基于的序列标注模型,对中医古籍医案进行实体识别。
本发明上述技术方案的有益效果如下:
上述方案中,所述基于中医古籍文献的中医命名实体识别方法及识别系统,结合现有的语言训练模型,如google提出的语言模型预训练方法bert基于小样本的训练集进行训练,训练集中的标注数据较少,极大的节省了人工标注成本;得到了面向中医古籍文献的命名实体识别方法,可以更加有效的利用中医古籍文献,得到了面向中医古籍文献的命名实体识别方法,易操作,效率高,实现对中医古籍文献,尤其是中医古籍医案的有效利用,更加全面的利用古籍文献,提升了中医领域命名实体识别的效果,使中医领域命名实体的识别更加准确,为中医领域后续应用打下了良好的数据基础。
附图说明
为了更加清晰的阐述本发明的实施例和现有的技术方案,下面将本发明的技术方案说明附图做简单的介绍,显而易见的,在不付出创造性劳动的前提下,本领域普通技术人员可通过本附图获得其他的附图。
图1为本发明实施例基于中医古籍文献的中医命名实体识别方法流程示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
为解决包括中医古籍医案在内的中医古籍文献的中医命名实体识别问题,本发明提供了一种基于中医古籍文献的中医命名实体识别方法及识别系统,结合现有的语言训练模型,如google提出的语言模型预训练方法bert,得到了面向中医古籍文献的命名实体识别方法,可以更加有效的利用中医古籍文献,为中医领域的相关研究打下了良好的基础。
下面结合附图,通过具体的实施例,对本发明作进一步详细的说明。
第一实施例
本实施例提供了一种基于中医古籍文献的中医命名实体识别方法,图1所示为所述中医命名实体识别方法流程示意图。
本实施例中所述命名实体,针对中医古籍文献中的医案文献,但是本发明并不局限于医案,也可应用于其他中医古籍文献。
如图1所示,所述基于中医古籍文献的中医命名实体识别方法,包括如下步骤:
步骤s1,获取中医古籍医案语料。
进一步地,所述获取中医古籍医案语料,具体包括以下步骤:
步骤s11,利用光学字符识别(opticalcharactersrecognition,ocr)对已有的纸质版中医古籍医案书籍进行扫描识别,形成电子文本语料。
步骤s12,利用开源网络爬虫从网络上抓取没有纸质版书籍的中医古籍医案语料。
步骤s13,将步骤s11和步骤s12获取到的语料文本进行对比、合并,最终形成统一的待处理的中医古籍医案语料。
步骤s2,对步骤s1获取的所述待处理的中医古籍医案语料进行数据清理。
进一步地,对待处理的中医古籍医案语料进行数据清理,具体包括以下步骤:
步骤s21,校正错别字。
本步骤中,所述错别字是指医生在记录时写错或获取语料时识别错误导致的错误字符现象。例如,“一医见腹泻「」渴”,实际上应该是“一医见腹泻口渴”。
步骤s22,过滤无关语句。
本步骤中,所述无关语句包括:
22.1,由于原始语料中有一部分来自整理成册的书籍,其中包含了很多标题、作者等信息,如“《两都医案》”、“程从周”等。
22.2,由于医生记录医案时具有较强的主观随意性或者历史比较久的医案保存不完备,其中包含了一些意义不明或仅表达医生个人感情的句子,如“附。”、“某。”、“哀哉!”等。
进一步地,所述过滤无关语句,包括以下步骤:
步骤s221,人工整理需要过滤的无关语句的特征。
优选地,所述特征包括:
221.1,标题、作者等信息基本是绑定在一起出现的;
221.2,标题中基本都包含书名号;
221.3,另外一些意义不明或表述医生情感的句子,基本形式固定,诸如“哀哉!”、“某。”等;
221.4,需要过滤的无关语句长度大多较短,优选地,不超过10~15。
步骤s222,根据步骤s221整理的特征,设计相应的正则表达式,按句子分割的规则对句子进行分割,再结合长度限制,将待处理语料中的相关语句过滤掉。
优选地,所述句子分割的规则为:
222.1,以句号、问号、感叹号结尾的字符串视为句子;
222.2,若不包含句号、问号、感叹号,但单独成一行,也视为句子。
步骤s3,基于步骤s2得到的中医古籍医案语料,进行面向中医古籍医案语料的语言模型预训练。
优选地,本步骤中所述语言模型预训练,采用google的语言模型预训练方法bert。
进一步地,所述面向中医古籍医案语料的语言模型预训练,具体包括以下步骤:
步骤s31,下载语言模型预训练中文语言训练的源码。
例如,以google的bert训练为例,下载google开源的基于bert训练的中文语言模型chinese_l-12_h-768_a-12以及bert的源码。
步骤s32,人工整理中医古籍医案涉及到的字表,与源码中的中文字表对比,切分出中医领域的生僻字表。
例如,以google的bert训练为例,与google开源的中文字表对比,切分出中医领域独特的生僻字表。表1为所切分出的部分生僻字表的示例。
表1基于google开源的生僻字表
步骤s33,以生僻字表中的字符代替源码中使用频率低的字符的方式,将所述生僻字表与中文字表合并,并保证中文字表的长度不变。
以google开源的bert训练为例,将google开源的中文字表与所述生僻字表合并,合并时以生僻字表替换中文字表中使用频率低的字符,以保证字表长度不变。
步骤s34,对步骤s2清理后的中医古籍医案语料中的段落进行分段,预设段落长度阈值和/或段落包含句子数量阈值,将大于所述段落长度阈值和/或段落包含句子数量阈值的段落文本,作为语言训练模型的训练语料。
优选地,所述对中医古籍医案语料中的段落进行分段,依照222.1、222.2的规则进行。优选地,所述段落长度阈值为150,段落包含句子数量阈值为3。
步骤s35,利用按字符分隔的分词规则替换源码中的分词方法,基于中文语言训练模型,以所下载的语言模型预训练方法在所述步骤s34中的语言训练模型的训练语料上进行面向中医古籍医案的语言模型预训练。
以google的bert训练为例,本步骤为利用按字符分隔的分词规则替换bert源码中的分词方法,基于google开源的中文语言模型,利用bert预训练方法在步骤s34切分出的训练语料上进行面向中医古籍医案的语言模型预训练。
步骤s4,基于步骤s2所获得的清理后的中医古籍医案语料,对所述语料进行序列标注,形成后续模型的训练集。
进一步地,所述形成后续模型训练集,通过对所述中医古籍医案语料进行bioes形式的序列标注而形成。这里的标注为人工标注。
更进一步地,所述对中医古籍医案语料进行bioes形式的序列标注,所述序列标注的标签形式为bioes,其中:b,即begin,表示实体的开始字符;i,即intermediate,表示实体的中间字符;e,即end,表示实体的结尾字符;s,即single,表示单个字符组成的实体;o,即other,表示其他,用于标记无关字符。具体地,包括以下步骤:
步骤s41,选取实体识别类型。
中医古籍医案中涉及到的命名实体种类繁多,本实施例中优选的实体类型分别为:症状(zz)、脉象(mx)、舌象(sx)、中药(zy)、剂量(jl)、方剂(fj)。在实际应用中,可以根据中医古籍医案的具体文本或其他需要对上述实体类型进行相应的增加或删除,上述示例并不构成对实体类型选取的限制。
步骤s42,约定标注规则。
中医古籍医案中的命名实体具有鲜明的领域特征,尤其以“症状”实体最为突出,所以在标注过程中,需要针对其特征对一般的标注规则进行改造。在中医古籍医案中,症状名一般由病位、病势和病性三部分组成,如“舌黑唇焦”等。然而由于医生记录时的随意性,症状名出现的形式多种多样,包括:
42.1,几种症状并列出现,并无标点符号分隔,对这种情况我们约定如果症状间属于并列关系则分开标注,如“口苦耳聋”,则将“口苦”、“耳聋”分别当做独立的症状名;如果症状间属于递进关系则将其标注成一个症状,如“腹痛作泻”,则将其当做一个症状名。
42.1,几种病位并列出现,但病位间有标点符号分隔,对这种情况我们约定仅保留最后一个病位,如“胸、腹疼”,则仅将“腹疼”认定为症状。
步骤s43,从清理后的语料中随机选取预定规模的句子集合,按字符分隔写入待标注文件,句子间以一空行分隔。
优选地,所述预定规模的句子集合,为每个集合包含5000条句子,占全部语料文本的5%。
步骤s44,基于选取的实体识别类型及约定的标注规则,对选取的预定规模的句子集合进行人工标注。
以优选的实体类型-症状(zz)、脉象(mx)、舌象(sx)、中药(zy)、剂量(jl)、方剂(fj)-为例,人工标注如表2所示:
表2对选定句子集合的人工标注示例
步骤s5,基于步骤s4得到的序列标注的模型训练集,将步骤s3的语言模型作为编码层,将预设的神经网络结构作为解码层,训练相应的序列标注模型。
优选地,所述预设的神经网络结构,为bilstm、和/或crf、和/或softmax。
进一步地,本步骤基于序列标注的模型训练集,进行序列标注模型的训练,具体包括以下步骤:
步骤s51,划分训练集、验证集、测试集。
优选地,本步骤中,将步骤s4中标注的训练集均匀划分为10份,其中保证每份包含六种实体类型的句子的数量基本一致。每次训练选取其中1份数据作为验证集,1份作为测试集,剩余8份作为训练集。
步骤s52,训练序列标注模型,形成模型的自动标注结果。
优选地,本步骤中,将步骤s3基于预训练方法训练的语言模型作为编码层,将“bilstm+crf”形式的神经网络结构作为解码层,结合步骤s51划分的训练集、验证集、测试集进行模型训练,其中选取不同的数据作为测试集重复训练模型,直至训练集覆盖过全部的人工标注集合,最终将模型的标注结果汇总形成模型的自动标注结果。
步骤s53,将模型的自动标注结果与人工标注结果对比,将不一致的标注序列过滤出来,然后人工对过滤出来的标注结果进行校对,最后将校对后的结果写回训练集。
步骤s54,判断是否满足标注要求,若满足,则输出最终的标注结果;若不满足,则返回步骤s51。
进一步地,所述判断是否满足标注要求,包括:模型的精度是否达到预设阈值或模型自动标注的结果与人工标注结果完全一致。这里的预设阈值,可以为精度的峰值。
步骤s6,基于步骤s5训练得到的序列标注模型,对中医古籍医案进行实体识别。
进一步地,基于训练好的序列标注模型,对中医古籍医案进行实体识别,具体包含以下步骤:
步骤s61,基于训练好的序列标注模型,对待识别的中医古籍医案语料进行自动标注。
步骤s62,依据bioes标注模式的一般规则,将字级别标注转换成词级别标注形式,即将实体从标注结果中分离出来。
还是以优选的实体类型-症状(zz)、脉象(mx)、舌象(sx)、中药(zy)、剂量(jl)、方剂(fj)-为例,表3所示为标注结果的分离示例。
表3分离的标注结果示例
由本实施例技术方案可以看出,本实施例的所述基于中医古籍医案的中医命名实体识别方法,与现有的语言训练模型相结合,如google的bert训练模型,基于小样本的训练集进行训练,训练集中的标注数据较少,极大的节省了人工标注成本;得到了面向中医古籍文献的命名实体识别方法,可以更加有效的利用中医古籍文献,提升了中医领域命名实体识别的效果,使中医领域命名实体的识别更加准确,为中医领域后续应用打下了良好的数据基础。第二实施例
本实施例提供了一种基于中医古籍文献的中医命名实体识别系统,所述系统包括:语料获取模块、数据清理模块、语言模型预训练模块、训练集标注模块、序列标注模型训练模块、实体识别模块;其中,
所述语料获取模块用于获取中医古籍医案语料;
所述数据清理模块用于对获取的所述待处理的中医古籍医案语料进行数据清理;
所述语言模型预训练模块用于基于中医古籍医案语料,进行面向中医古籍医案语料的语言模型预训练;
所述训练集标注模块用于基于清理后的中医古籍医案语料,对所述语料进行序列标注,形成后续模型的训练集;
所述序列标注模型训练模块用于基于序列标注的模型训练集,将语言模型作为编码层,将预设的神经网络结构作为解码层,训练相应的序列标注模型;
所述实体识别模块用于基于的序列标注模型,对中医古籍医案进行实体识别。
本实施例的所述基于中医古籍文献的中医命名实体识别系统与第一实施例的所述中医命名实体识别方法是相对应的,因此,对于第一实施例的相应描述,同样适用于本实施例的所述命名实体识别系统,在此不再赘述。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!