基于改进灰狼算法的Android恶意应用检测方法与流程
本发明涉及软件安全领域,尤其涉及一种基于改进灰狼算法的android恶意应用检测方法。
背景技术:
随着移动互联网的飞速发展,android已经成为当今最受欢迎的移动操作系统之一。android因其开放性吸引了无数的开发人员在其上开发制作自己的应用程序,但其巨大的发展空间也同时吸引着广大骇客,骇客利用恶意应用侵犯android系统使用者的财产安全和隐私安全。进行android恶意应用检测成为防止此类威胁的重要手段。
随着机器学习的发展,很多学者开始将机器学习方法应用到android恶意检测上。但是,在使用基于机器学习的检测方法时,为了获取尽可能多的分类信息,通常提取大量细粒度的特征,使得特征维度非常高,给机器学习分类器带来巨大工作量,并降低分类器的分类精度。另外,在现实世界中,android恶意应用与良性应用的分布是不平衡的,良性应用的数量远远大于恶意应用的数量,而不平衡数据集会使机器学习分类器偏向大类样本,即良性应用,易造成恶意样本被错分。
技术实现要素:
本发明的目的在于针对现有技术中存在的不足,提供了一种基于改进灰狼算法的android恶意应用检测方法。该方法能够有效提高android恶意应用检测的检测效率和检测精度。
为了实现上述目的,本发明采用了以下技术方案:
一种基于改进灰狼算法的android恶意应用检测方法,包括下列步骤:
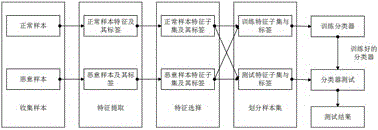
1)收集样本集,也就是android应用程序(简称apk),包括良性apk和恶意apk;
2)对良性apk和恶意apk分别进行反编译,提取出样本特征形成样本特征集;
3)基于k折交叉验证方法,将样本特征集分成k份,取其中一份为测试集,其余k-1份为训练集;
4)使用改进后灰狼算法进行包裹式特征选择,选择出最优特征子集,使用常见机器学习分类器(如朴素贝叶斯、支持向量机或者决策树等)进行分类检测,采用fitness(x)作为灰狼算法的适应度函数;
5)对分类器使用选择出的特征子集进行训练,得到训练好的分类器。
6)根据步骤2)提取待检测apk特征,将其映射到最优特征子集中得到特征向量,用训练好的分类器判断该特征向量是否恶意,即完成检测。
本发明进一步说明,所述步骤2)中提取样本特征的方法为:
2a)使用反编译工具apktool对收集到的apk进行反编译,得到*.smali文件,依次扫描各个smali文件中的“invoke-virtual”语句,得到该apk的api调用信息;
2b)使用androidsdk中的工具——appt提取出apk申请的权限,得到该apk的权限信息;
2c)取所有apk的api调用信息和权限信息的全集作为特征集合;每一行表示一个apk文件,每一列表示一个特征,0表示不存在该特征,1表示存在该特征,并在最后一列加入类别标签,良性表示为0,恶意表示为1。
本发明进一步说明,所述步骤3)的k折交叉验证方法中k是任意大于1的常数。常见k取值为5或10。
本发明进一步说明,所述步骤4)中改进后灰狼算法的包裹式特征选择,具体为:
4a)初始化:初始化灰狼算法的种群规模nop,个体维度nov(nov等于特征集合中特征的个数),于是得到一个nop×nov的01矩阵,矩阵每一行表示一个个体,具体为:xi=(xi1,xi2,…,xinov),行中的每一列对应着一个特征,其值为0表示不选择该特征,其值为1表示选择该特征;另外设置算法搜索的最大迭代次数为max_iteration;
4b)对灰狼种群中每一个个体所表示的特征集合,分别用训练集训练分类器,并用测试集测试分类效果,得到tp、fn和fp;使用fitness(x)计算灰狼个体的适应度值,将适应度值较大的前三个个体确定为:
为了在高维不平衡数据集中高效正确检测出android恶意应用,需要综合考虑检测出g-mean、小类(在此处指恶意样本类)的f-value、选择的特征数量占总特征数量的比例,所以设计灰狼算法的适应度函数fitness(x)为:
其中,f-value和g-mean的计算公式分别为:
其中,tp表示恶意应用软件被正确识别的数量,fp表示良性应用软件被误识别为恶意应用软件的数量,fn表示恶意应用软件被误识别的数量;使用k折交叉验证训练分类器可以得到tp、fp、fn,再根据公式计算得到f-value和g-mean;|x|表示个体中1的个数,n是所有特征的数量,等于nov;
4c)判断是否达到最大迭代次数,若是,输出
4d)采用改进后的位置更新策略更新灰狼种群中各个个体的位置:
在这里,
4e)计算改变位置后的各个个体的适应度,更新
本发明的技术创新相关说明:
特征选择作为机器学习的关键环节,通过去除冗余特征实现数据集精简,提高机器学习分类器的分类效率和分类正确率。根据在特征选择过程中是否需要机器学习算法的参与可将特征选择算法分为过滤式方法(filter)和包裹式方法(wrapper)。过滤式方法依赖于一些特定的指标,而不需要某个具体的机器学习算法的参与。包裹式方法需要依赖于特定的机器学习算法,根据该算法的分类性能(例如,正确率)来评价选择的特征子集的优劣。
寻找最优特征子集是特征选择的首要任务。如果一个特征集合中包含n个特征,那么它将有2n个子集,要从这2n个子集中找到最优特征子集是np难题。特征选择的目标就是在选择尽可能少的特征数量的同时最大化分类器的正确率,故可以将特征选择看作是一个优化问题。而智能算法在处理优化问题上效果良好,所以可以将智能算法应用到特征选择上。
因此,在本发明中发明人的技术思路是从位置更新公式方面提高灰狼算法的寻优能力,并设计新的适应度函数,使其更适合解决高维不平衡数据集下的特征选择。使用改进后的灰狼算法进行包裹式特征选择得到最优特征子集,再使用最优特征子集进行分类器训练以进行android恶意应用检测。
本发明与现有技术相比具有如下优点:
1.本发明从位置更新公式方面提高了灰狼算法的寻优能力,能够高效快速地在高维数据集中寻找最优特征子集。
2.本发明提出了新的适应度函数,综合考虑了小类的f-value和g-mean,最终选择的特征数量为三个要素,使得在使用机器学习分类器进行android恶意应用检测时具有更高的f-value和g-mean,更少的特征数量。
附图说明
图1为本发明一实施例的实现流程图;
图2为本发明一实施例中基于改进灰狼算法的包裹式特征选择的实现流程图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
实施例:
基于改进灰狼算法的android恶意应用检测方法,包括下列步骤:
步骤一:收集样本集,也就是android应用程序(简称apk),包括良性apk和恶意apk;
步骤二:对apk进行反编译,提取出其api调用信息和权限申请信息作为特征,并将其向量化为特征集合,形成样本特征集;具体为:
2a)使用反编译工具apktool对收集到的apk进行反编译,得到*.smali文件,依次扫描各个smali文件中的“invoke-virtual”语句,得到该apk的api调用信息;
2b)使用androidsdk中的工具——appt提取出apk申请的权限,得到该apk的权限信息;
2c)取所有apk的api调用信息和权限信息的全集作为特征集合;每一行表示一个apk文件,每一列表示一个特征,0表示不存在该特征,1表示存在该特征,并在最后一列加入类别标签,良性表示为0,恶意表示为1;
步骤三:使用k折交叉验证法将样本集划分为训练集和测试集;k是任意大于1的常数;常见k取值为5或10;
步骤四:使用改进的灰狼算法进行包裹式特征选择,得到最优特征子集,使用常见机器学习分类器(如朴素贝叶斯、支持向量机或者决策树等)进行分类检测,采用改进后的适应度函数fitness(x)作为灰狼算法的适应度函数;具体为:
4a)初始化:初始化灰狼算法的种群规模nop,个体维度nov(nov等于特征集合中特征的个数),于是可以得到一个nop×nov的01矩阵,矩阵每一行表示一个个体,为:xi=(xi1,xi2,…,xinov),行中的每一列对应着一个特征,其值为0表示不选择该特征,其值为1表示选择该特征;另外设置算法搜索的最大迭代次数为max_iteration;
4b)对灰狼种群中每一个个体所表示的特征集合,分别用训练集训练分类器,并用测试集测试分类效果,可以得到tp、fn和fp,使用fitness(x)计算灰狼个体的适应度值,将适应度值较大的前三个个体确定为:
为了在高维不平衡数据集中高效正确检测出android恶意应用,需要综合考虑检测出g-mean、小类的f-value,小类在此处指恶意样本类,选择的特征数量占总特征数量的比例,所以设计灰狼算法的适应度函数为:
其中,f-value和g-mean的计算公式分别为:
其中,tp表示恶意应用软件被正确识别的数量,fp表示良性应用软件被误识别为恶意应用软件的数量,fn表示恶意应用软件被误识别的数量;使用k折交叉验证训练分类器可以得到tp、fp、fn,再根据公式计算得到f-value和g-mean;|x|表示个体中1的个数,n是所有特征的数量,等于nov;
4c)判断是否达到最大迭代次数,若是,输出
4d)更新灰狼种群中各个个体的位置:
在这里,
4e)计算改变位置后的各个个体的适应度,更新
步骤五:使用最优特征子集训练分类器,得到训练好的分类器;
步骤六:提取待检测apk的特征,将其对应到最优特征子集中形成特征向量,用训练好的分类器对该特征向量进行分类。
以上描述仅是本发明的一个具体实例,并未构成对本发明的任何限制。显然对于本领域的专业人员来说,在了解了本发明内容和原理后,都可能在不背离本发明原理、结构的情况下,进行形式和细节上的各种修正和改变,但是这些基于本发明思想的修正和改变仍在本发明的权力要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!