一种基于用户偏好的个性化评论推荐方法与流程
本发明涉及网络评论筛选推相关技术领域,具体为一种基于用户偏好的个性化评论推荐方法。
背景技术:
电子商务网站或app上用户对产品的评论可以帮助其他潜在消费者了解该产品的全貌,帮助潜在消费者进行购买决策。许多农场app例如农场世界,一乙农场等都采用了线上操作、线下收货的模式。为了吸引新用户,巩固老用户的信任,需要给潜在消费者提供收货展示,即用户收到货物的产品图以及对其的评价。因此,研究如何从大量的产品评价中发现有价值的评论并推荐给其他用户十分重要。
推荐算法可以根据用户信息,针对用户的喜好筛选用户可能感兴趣的产品,从而推荐该产品的相关评论,可以使收货展示模块更加个性化,达到引导用户选择,增加用户信任度的效果。
推荐算法可以分为基于内容(cb),基于协同过滤的(cf)和基于混合方法的。cb通过内容来计算两个产品之间的相似度,而cf是通过对两件产品进行了评分的用户的评分计算两个产品的相似度。在最近的推荐系统里cf更受欢迎,也得到了更广泛的应用,是最主流的推荐算法。目前,矩阵因子分解(mf)成为最受欢迎的cf算法之一。经证明,mf胜过现有大多数工艺水平的算法。
目前,国内外面向用户的产品评论的推荐方法与技术的研究尚不深入,特别是挖掘用户喜好和感兴趣的评论,评论的自动评估以及相关评论识别、匹配、组织与推荐方面的研究尚属空白。
基于特征的评论推荐方法能够有效地反映评论的质量,预测消费者对评论的打分来进行推荐。在“automaticallyassessingreviewhelpfulness”,“exploitingsocialcontextforreviewqualityprediction”,“learningtorecommendhelpfulhotelreviews”等文中,研究者试图利用评论中的文字和社会特征预测消费者对评论的打分,从而向消费者推荐预测打分高的那些评论。但这类方法忽略了消费者的个性化问题,没有考虑消费者的兴趣,可能会把相同的评论推荐给关注点和兴趣点不一样的用户。
技术实现要素:
本发明的目的在于提供一种基于用户偏好的个性化评论推荐方法,以解决上述背景技术中提出的问题。
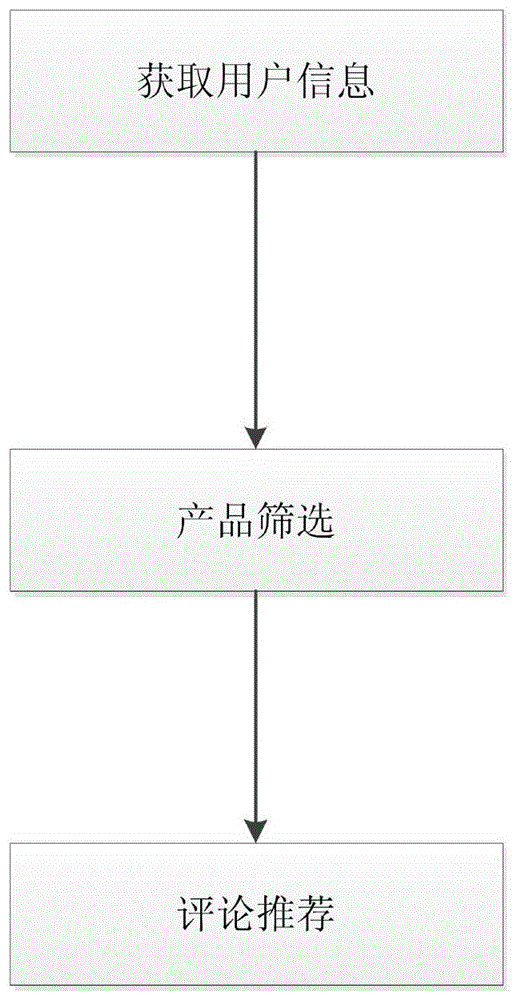
为实现上述目的,本发明提供如下技术方案:一种基于用户偏好的个性化评论推荐方法,该种基于用户偏好的个性化评论推荐方法包括以下基本步骤:
步骤一,获取用户信息:对首次登录的新用户提供个性化问答,对老用户获得其信息,尤其是用户感兴趣的产品以及关注的游戏内容。所述用户信息包括用户的地区,性别以及大量的农场用户历史行为数据。
步骤二,产品筛选:根据步骤一所获取的用户信息,采用协同过滤算法推荐用户可能感兴趣的产品。
步骤三,评论推荐:根据步骤二推荐的产品,采用基于奇异值分解的个性化评论推荐方法,预测用户对评论的打分,向用户推荐具有高分的评论。
优选的,所述步骤二中,还包括以下具体过程:构建用户—评分矩阵,首先构建用户—产品项目评分矩阵:将评分信息表中的数据具体化为一个矩阵cm×n,行表示用户,列表示项目,元素cu,a代表用户u对标号为a的项目的评分,分数采取五分制,最小值为1,最大值为5。数值越大说明用户对该项目认可度越高。
寻找邻居用户:依据相似度大小,由高到低来确定当前用户相似度最高的n个邻居。采用如下公式计算相似度:
其中ap,q集合包含的是用户p,q同时评分过的项目,
生成推荐项目:取用户p评分过的项目对应的评分集合为h,
同理,
优选的,所述步骤三中,找到步骤二中推荐产品的产品评论,采用基于奇异值分解的个性化评论推荐方法,预测用户对评论的打分,向用户推荐具有高分的评论。
优选的,所述步骤三中,包括以下主要过程:找出用户感兴趣的产品特征,并根据用户感兴趣的产品特征为用户构建用户模型;根据评论对用户感兴趣的产品特征(即用户模型)的描述程度预测用户对该评论的打分;根据评论的预测得分,由高到低向用户进行评论推荐。
优选的,所述步骤三的主要过程中,基于奇异值分解将原始的用户-特征矩阵压缩到一个新的向量空间并由两个矩阵的点乘拟合:用户-隐因子矩阵和特征-隐因子矩阵。隐因子是显因子(商品特征)的抽象表示。
用户-特征矩阵(p)是指所有用户对所有产品特征的平均打分组成的矩阵,其中第a行第b列的元素pa,b,代表用户a对特征b的平均打分,m代表集合u中的用户数量,n代表集合r中所有评论一共提及的商品特征数量。
用户-隐因子矩阵表示每个用户对各个隐因子的感兴趣程度,特征-隐因子矩阵则表示各个特征与各个隐因子的语义联系程度。整个拟合的过程如下:
其中,vm,k表示用户隐因子矩阵;sm,k表示特征隐因子矩阵;k代表压缩后的向量空间的维度。用户a对各个隐因子的感兴趣程度会由向量va,1,va,2,…va,k表示。对于每个特征b而言,b与各个隐因子之间的语义联系会由向量sb,1,sb,2,…,sb,k表示。
优选的,所述步骤三的主要过程中,首先利用评论和特征之间的关系,把评论也映射到由隐因子组成的向量空间中。评论和特征之间的关系可以用如下评论-特征矩阵表示。
其中ci,j代表用户i对特征j的平均打分,n表示集合r中评论数量,n代表集合r中所有评论一共提及的商品特征数量。ci,j的值越高说明特征j出现在评论i中的概率越高,即两者之间的关联程度越高。
然后把评论映射到由隐因子组成的向量空间中:
ln,k是评论-隐因子矩阵;ln,k的值越高就代表了评论l和隐因子k之间的关系越紧密。
优选的,所述步骤三的主要过程中,在把评论也映射到隐因子向量空间后,只需把用户-隐因子矩阵和评论-隐因子矩阵进行点乘,就能得到每个用户对每个评论的预测打分。
gm,n就是用户对评论的预测打分矩阵,矩阵中的元素gm,n表示用户m对评论n的预测打分。最后,根据用户对每条未读评论的预测打分对评论进行排序,并返回其中得分最高的n条评论推荐给用户。
与现有技术相比,本发明的有益效果是:
注重用户偏好,克服了传统方法中缺乏个性化的缺点,能向用户展示他们感兴趣的,具有价值的优质评论,达到吸引用户,帮助潜在消费者进行购买决策的效果。在推荐产品的同时推荐评论,增加用户的信任感,更加丰富且利于潜在消费者购买。
附图说明
图1是涉及一种基于用户偏好的个性化评论推荐方法的总体流程示意图;
图2是涉及一种基于用户偏好的个性化评论推荐方法的具体流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-2,本发明提供一种技术方案:一种基于用户偏好的个性化评论推荐方法,包括以下具体步骤:
步骤一,获取用户信息:对用户进行个性化问答,对首次登录的新用户提供个性化问答,对老用户收集其信息,尤其是用户感兴趣的产品以及关注的游戏内容。所述用户信息包括用户的地区,性别以及大量的农场用户历史行为数据。
步骤二,生产品筛选:根据步骤一所获取的用户信息,采用协同过滤算法推荐用户可能感兴趣的产品。包括以下具体过程:
构建用户—评分矩阵,将评分信息表中的数据具体化为一个矩阵cm×n,行表示用户,列表示项目,元素cu,a代表用户u对标号为a的项目的评分,分数采取五分制,最小值为1,最大值为5。数值越大说明用户对该项目认可度越高。
寻找邻居用户:依据相似度大小,由高到低来确定当前用户的top-n个邻居。采用如下公式计算相似度:
其中cp,q集合包含的是用户p,q同时评分过的项目,
生成推荐项目:取用户p评分过的项目对应的评分集合为h,
同理,
步骤三,评论推荐:根据步骤二推荐的产品,采用基于奇异值分解的个性化评论推荐方法,预测用户对评论的打分,向用户推荐具有高分的评论。主要过程为:找出用户感兴趣的产品特征,并根据用户感兴趣的产品特征为用户构建用户模型;根据评论对用户感兴趣的产品特征(即用户模型)的描述程度预测用户对该评论的打分;根据评论的预测得分,由高到低向用户进行评论推荐。
基于奇异值分解将原始的用户-特征矩阵压缩到一个新的向量空间并由两个矩阵的点乘拟合:用户-隐因子矩阵和特征-隐因子矩阵。隐因子是显因子(商品特征)的抽象表示。
用户-特征矩阵(p)是指所有用户对所有产品特征的平均打分组成的矩阵,其中第a行第b列的元素pa,b,代表用户a对特征b的平均打分,m代表集合u中的用户数量,n代表集合r中所有评论一共提及的商品特征数量。
用户-隐因子矩阵表示每个用户对各个隐因子的感兴趣程度,特征-隐因子矩阵则表示各个特征与各个隐因子的语义联系程度。整个拟合的过程如下:
其中,vm,k表示用户隐因子矩阵;sm,k表示特征隐因子矩阵;k代表压缩后的向量空间的维度。用户a对各个隐因子的感兴趣程度会由向量va,1,va,2,…va,k表示。对于每个特征b而言,b与各个隐因子之间的语义联系会由向量sb,1,sb,2,…,sb,k表示。
利用评论和特征之间的关系,把评论也映射到由隐因子组成的向量空间中。评论和特征之间的关系可以用如下评论-特征矩阵表示。
其中ci,j代表用户i对特征j的平均打分,n表示集合r中评论数量,n代表集合r中所有评论一共提及的商品特征数量。ci,j的值越高说明特征j出现在评论i中的概率越高,即两者之间的关联程度越高。
然后把评论映射到由隐因子组成的向量空间中:
ln,k是评论-隐因子矩阵;ln,k的值越高就代表了评论l和隐因子k之间的关系越紧密。
把评论也映射到隐因子向量空间后,只需把用户-隐因子矩阵和评论-隐因子矩阵进行点乘,就能得到每个用户对每个评论的预测打分。
gm,n就是用户对评论的预测打分矩阵,矩阵中的元素gm,n表示用户m对评论n的预测打分。最后,根据用户对每条未读评论的预测打分对评论进行排序,并返回其中得分最高的n条评论推荐给用户。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!