一种基于自编码神经网络的相似法律案例检索方法与流程
本发明属于自然语言处理领域,涉及一种基于自编码神经网络的相似法律案例检索方法。
背景技术:
文档相似度计算是相似文档检索的重要环节,旨在比较文档对的相似程度。文档相似度计算的研究成果可以应用到很多自然语言处理任务中,例如信息检索、机器翻译、自动问答、复述问题以及对话系统等。在一定程度上,这些自然语言处理任务都可以抽象为文档相似度计算问题。例如,信息检索可以归结为查询项与数据库中文档的相似度计算问题。目前各种法律数据库已经存储了大量电子格式数据,但是现有的数据库仅能做简单的文档分类,所以通过数据库查询相似文档费时费力。如何从海量文档数据中更快、更方便地查询相似文档,是一项值得探讨的工作。当前法律领域下文档相似度计算存在以下难点:1、文档之间具有较强关联性,2、文档篇幅较长导致计算复杂,3、文档较长存在一词多义。
法律领域存在文档之间具有较强关联性的问题,单纯通过词级检索得不到相似文档推荐,文档相似度计算可以帮助人们准确地从数据库中查询到最相似的文档。一些学者已经在研究与机器学习相关的文档相似度计算方法,例如采用向量空间模型,最近邻算法,基于词频的贝叶斯统计方法等,这些方法均基于关键词(特征)和统计信息进行文档相似度计算,由于特征是根据特定任务人工设计的,因此在很大程度上限制了模型的泛化能力,同时提取的特征不够丰富全面。随着深度学习的发展,基于深度学习的文档相似度计算方法可以自动地从原始数据中抽取特征,根据训练数据的不同,方便地适配到其他文档相似度的相关任务中,已经取得了巨大的成功。但是值得注意的是,由于目前基于深度学习的文档相似度计算方法往往依赖于大型监督型数据集,存在数据标注过程的高成本与很多任务很难获得全部真值标签这样的强监督信息的问题。
随着文档数据的大量产生,人们针对文档相似度计算做了大量探索和实践。专利申请号cn201811161158.1提出了一种文档相似度计算方法、装置、设备及介质,该方法基于预设规则将文档进行向量化表示,有效减少了较长文档相似度的计算复杂度,但是该方法提取的特征不够丰富,不能完全体现文本的语义信息;专利申请号cn201410348547.0提出了一种文档语义相似度计算方法,该方法采用设定阈值的方法,分区间计算相似度,减小了文档检索工作量,提高了工作效率,但是该方法存在构建数据库的高人工成本问题。现有的文档相似度计算方法数据标注成本高,提取的特征不够全面。
技术实现要素:
为了克服现有技术存在的数据标注成本高、提取的特征不够全面的问题,本发明提供一种基于自编码神经网络的相似法律案例检索方法,利用无监督学习方法省去数据标注过程的高成本,采用的编解码网络结构共享上下文语义,丰富文本的特征,提高相似法律案例的检索效率。
本发明采用的技术方案是:
一种基于自编码神经网络的相似法律案例检索方法,包括以下步骤:
i)输入待检索的法律案例;
ii)利用法律案例特征向量模型获得待检索的法律案例和数据库中法律案例的特征向量;
iii)采用逼近最近邻ann算法计算待检索的法律案例与数据库中法律案例的相似度;
iv)输出相似度满足要求的数据库中法律案例;
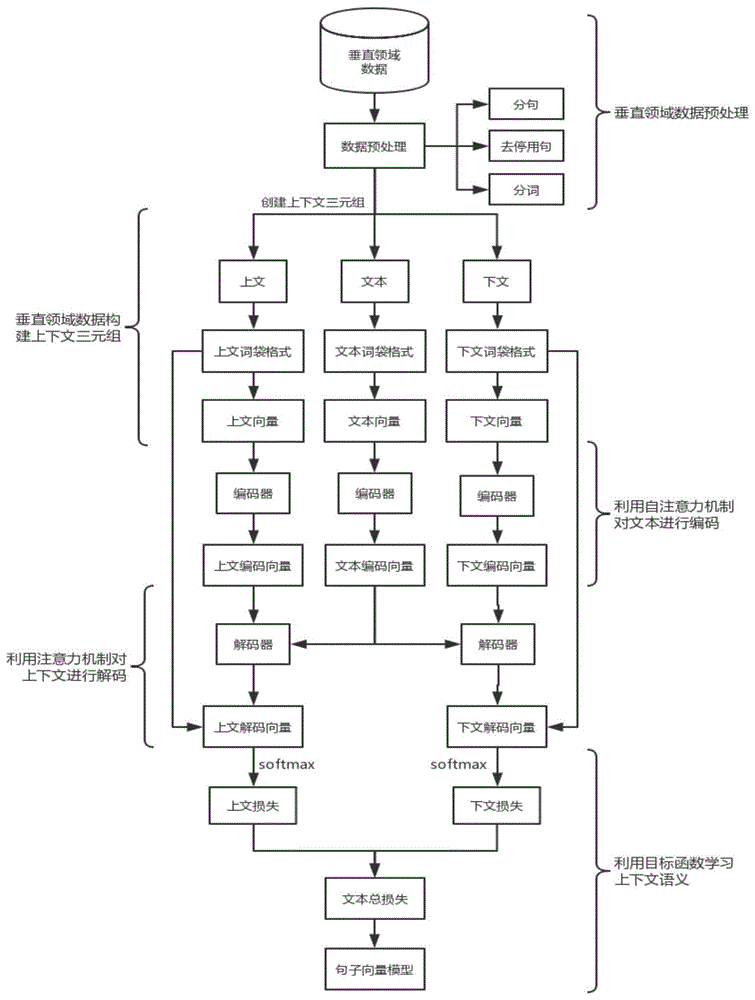
所述步骤ii)中,所述法律案例特征向量模型的生成步骤如下:
2.1)采集法律案例数据,进行数据预处理,获得法律案例数据集e;
2.2)根据法律案例创建[上文,文本,下文]三元组,根据词汇表字典中对应三元组的位置,生成三元组序列,并根据bow模型、one-hot模型、wordembedding模型分别生成三元组对应的三元组词袋序列、三元组独热序列、三元组词嵌入序列;
2.3)利用自注意力机制构成编码器对文本进行编码,输出文本编码向量;
2.4)利用自注意力机制构成解码器对上文、下文进行解码;
2.5)以总损失最小为目标函数,训练编码器和解码器,生成法律案例特征向量模型。
进一步地,所述步骤2.1)中,数据预处理包括以下步骤:
2.1.1)文本分句处理,用正则方法提取法律案例的正文,按句号分割;
2.1.2)停用句处理,统计句子频率,去除停用句,所述停用句为句子频率超出阈值的句子;
2.1.3)文本分词处理,利用有用词典进行分词操作,去除停用词。
进一步地,所述步骤2.2)中,词汇表字典的第一个词为结束标志词,第二个词为未知标志词,第三个到第vocab_size个词,获取方法为:
统计法律案例数据集e的词汇频率,按照词频率从高到低的排序,截取vocab_size-2个词汇,其中vocab_size为预设的词汇表字典的词汇数量。
进一步地,所述步骤2.2)的过程为:
根据法律案例创建(上文,文本,下文)三元组,其中上文包含预设的sent_pre_size个句子,文本包含预设的sent_size个句子,下文包含预设的sent_post_size个句子,一个法律案例可以形成text_size-2个三元组,其中text为法律案例包含的句子数量,一个三元组可以表示为([p1,p2,…,pp],[c1,c2,…,cc],[s1,s2,…,ss]),其中,pp为上文中第p个词汇,cc为文本中第c个词汇,ss为下文中第s个词汇;
根据词汇表字典中对应三元组的位置,生成三元组序列([p’1,p’2,…,p’p,0],[c’1,c'2,…,cc',0],[s’1,s'2,…,s’s,0]),其中p’p=vocab_dict[pp]、c'c=vocab_dict[cc]、s’s=vocab_dict[ss],vocab_dict[pp]表示上文中第p个词汇对应词汇表中的位置;
并根据bow模型、one-hot模型、wordembedding模型分别生成三元组对应的三元组词袋序列(decode_pre_ids,encode_ids,decode_post_ids)、三元组独热序列(decode_pre_mask,encode_mask,decode_post_mask)、三元组词嵌入序列(decode_pre_emb,encode_emb,decode_post_emb),其中三元组词嵌入序列的输入是三元组词袋序列,如下:
[p’1,p’2,…,p’p,0]=[2,5,1,2,5,3,0]
decode_pre_ids=[1,1,2,1,0,2,0,…,0]
decode_pre_mask=[1,1,1,1,0,1,0,…,0]
进一步地,所述步骤2.3)中,利用自注意力机制构成编码器对三元组词嵌入序列中的encode_emb进行编码,输出文本编码向量,过程为:
第一个编码器以encode_emb作为输入值,输出值通过输入值乘以权重值直接得到,输出值带着第一个编码器学习的信息传递给下一个编码器,作为下一个编码器的输入,共encoder_num个编码器,输出文本编码向量encode_output;
所述权重值利用自注意力机制获得,包括以下步骤:
2.3.1)创建q,k,v三个矢量,初始化三个变量wq,wk,wv,
wq_=[wq_1wq_2…wq_t]
wk_=[wk_1wk_2…wk_t]
wv_=[wv_1wv_2…wv_t]
q=[q1q2…qt]
k=[k1k2…kt]
v=[v1v2…vt];
q,k,v根据encode_mask为零的对应索引上替换为同维度的零向量;
2.3.2)计算自注意力,根据(q1,k1,v1)计算文本中第一个词的自注意力,第一个得分
2.3.3)keymasking:对k进行求和为key_mask,记录key_mask为0时的索引,根据步骤2.3.2)输出的score在相同索引处替换为有区分度的小数字,保持关注的词或字的值不变并淹没不相关的词或字;
2.3.4)通过softmax将步骤2.3.3输出的分数标准化,由softmax分数乘以v1为z1,即第一个词的注意力向量,以此类推文本的注意力向量z1=[z1z2…zvocab_size],将第二头注意力至第t头注意力(q2,k2,v2)-(qt,kt,vt)重复步骤3.2至步骤3.3,得到注意力z'=[z1z2…z8],初始化权重wo,文本的编码向量为:encode_output=z'wo。
进一步地,所述步骤2.4)中,利用自注意力机制构成解码器对上文、下文进行解码,过程为:
第一个解码器以decode_pre_emb作为输入值,输出值通过输入值乘以权重值直接得到,输出值带着第一个解码器学习的信息传递给下一个解码器,作为下一个解码器的输入,共decoder_num个解码器,输出上文解码向量decode_pre_output;
所述权重值利用自注意力机制获得,包括以下步骤:
2.4.1)利用自注意力机制对上文进行解码,根据步骤2.2.3输出的decode_pre_emb输入到一个编码器中得到上文编码向量decode_pre_output;创建q',k',v'三个矢量,初始化三个变量wq',wk',wv',
wq’_=[wq’_1wq’_2…wq’_t]
wk’_=[wk’_1wk’_2…wk’_t]
wv’_=[wv’_1wv’_2…wv’_t]
q’1=decode_pre_output×wq_1
k’1=encode_output×wk_1
v’1=encode_output×wv_1
q'=[q’1q’2…q’t]
k’=[k’1k'2…k’t]
v’=[v’1v’2…v’t]
根据公式
2.4.2)同上步骤,获得下文解码向量decode_post_output。
进一步地,所述步骤2.5)中,以总损失最小为目标函数,训练编码器和解码器,生成法律案例特征向量模型,过程为:
上文损失,将上文解码向量重构为一维上文解码向量,利用全连接将一维上文解码向量转为与上文词袋序列decode_pre_ids维数相同的形式,利用softmax将维数相同的上文解码向量和上文词袋序列decode_pre_ids对齐,通过交叉熵函数得到上文损失,
同上步骤,获得下文损失losspost;
总损失为上文损失和下文损失之和:loss=losspre+losspost;
训练编码器和解码器中的变量(wq,wk,wv,wq',wk',wv')反复迭代训练网络至总损失值不再减小为止。
所述步骤2.5)包括以下步骤:
2.5.1)解码后的上文对齐:将步骤2.4.1更新的上文解码向量decode_pre_output∈r20000×200重构为decode_pre_output∈r1×4000000,利用全连接将decode_pre_output转为decode_pre_output∈r1×20000,利用softmax将decode_pre_output与步骤2.2.3输出的decode_pre_ids对齐,通过交叉熵函数得到上文损失
losspre=lossespre×decode_pre_mask(9)
2.5.2)解码后的下文对齐:同步骤2.5.1将步骤2.4.2更新的下文解码向量decode_post_output与步骤2.2.3输出的decode_post_ids对齐,并屏蔽干扰信息得到下文损失losspost。
2.5.3)损失更新优化:根据步骤2.5.1与步骤2.5.2输出的上文损失与下文损失,得到总损失loss=losspre+losspost,根据总损失更新编码器与解码器中的变量(wq,wk,wv,wq’,wk’,wv’)反复迭代训练网络至总损失值不再减小为止,保存网络模型为m。
进一步地,所述步骤i)中,输入待检索的法律案例的过程为:
用正则方法提取待检索的法律案例的正文,按句号分割,根据停用句词典去除停用句,利用有用词典进行分词操作,去除停用词,获得文档doc=[a1,a2,…,an],其中
创建[上文,文本,下文]三元组,根据词汇表字典中对应三元组的位置,生成三元组序列,并根据bow模型、one-hot模型、wordembedding模型分别生成三元组对应的三元组词袋序列(doc_encode_ids)、三元组独热序列(doc_encode_mask)、三元组词嵌入序列(doc_encode_emb)
所述步骤ii)中,将doc_encode_emb,doc_encode_mask输入法律案例特征向量模型,获得待检索的法律案例编码向量doc_encode_output。
进一步地,所述步骤iii)中,采用逼近最近邻ann算法计算待检索的法律案例与数据库中法律案例的相似度,过程为:
将待检索的法律案例在数据库中的法律案例里进行搜索,为了加快查找的速度,ann算法通过对数据库中的法律案例空间进行分割,将其分割成很多小的子空间,在搜索的时候,通过基于树的方法、哈希方法或者矢量量化方法,快速锁定在某一(几)子空间,该(几个)子空间里的数据即近邻集合,通过归一化的欧氏距离:vectors=sqrt(2-2*cos(u,v))计算待检索的法律案例与近邻集合中的数据的距离并进行排序;
所述步骤iv)中,相似度从大到小排序,输出前m个数据库中法律案例。
进一步地,所述多个编码器和多个解码器之间的信息传递为前馈神经网络。
本发明与现有技术相比,其显著优点包括:(1)本发明采用的自编码神经网络是一种无监督学习算法,省去了监督学习数据标注过程的高成本,同时提高模型的泛化能力。(2)本发明采用的编码器与解码器为自注意力机制,将序列中的任意两个位置之间的距离缩小为一个常量,其次它不是类似rnn的顺序结构,因此具有更好的并行性,同时丰富了文本词语间的特征。(3)本发明采用的编解码网络结构共享上下文语义,能更准确的表示文档信息,使文档之间具有显著差异。(4)本发明采用的目标函数从句子级别上抽象了skip-gram模型,消除了词级上存在的一词多义问题,使用一个句子来预测它的上下句,精确地捕获了编码后句子的语义和结构,得到高质量的句子表示。
附图说明
图1为本发明实施例提供的法律案例特征向量模型生成的流程图。
图2为本发明实施例提供的相似法律案例检索的流程图。
图3为本发明实施例提供的法律案例特征向量模型的网络结构图。
具体实施方式
下面结合具体实施例来对本发明进行进一步说明,但并不将本发明局限于这些具体实施方式。本领域技术人员应该认识到,本发明涵盖了权利要求书范围内所可能包括的所有备选方案、改进方案和等效方案。
参照图1~图3,一种基于自编码神经网络的相似法律案例检索方法,所述方法包括以下步骤:
i)输入待检索的法律案例;
ii)利用法律案例特征向量模型获得待检索的法律案例和数据库中法律案例的特征向量;
iii)采用逼近最近邻(ann)算法计算待检索的法律案例与数据库中法律案例的相似度;
iv)输出相似度满足要求的数据库中法律案例;
所述步骤ii)中,所述法律案例特征向量模型的生成步骤如下:
2.1)采集法律案例数据,进行数据预处理,获得法律案例数据集e;
2.2)根据法律案例创建[上文,文本,下文]三元组,根据词汇表字典中对应三元组的位置,生成三元组序列,并根据bow模型、one-hot模型、wordembedding模型分别生成三元组对应的三元组词袋序列、三元组独热序列、三元组词嵌入序列;
2.3)利用自注意力机制构成编码器对文本进行编码,输出文本编码向量;
2.4)利用自注意力机制构成解码器对上文、下文进行解码;
2.5)以总损失最小为目标函数,训练编码器和解码器,生成法律案例特征向量模型。
所述步骤2.1中,法律领域数据预处理过程为:
2.1.1)文本分句处理:本实施例采集了1000万裁判文书(法律领域数据),根据裁判文书数据的特点,用正则提取了裁判文书的正文,去掉首尾无关数据(首:原告、被告、代理人等,尾:相关法律条文),提取的正文按句号分割,依次保存在列表中。
2.1.2)文本去高频句:本实施例根据步骤1.1输出的列表统计句子频率,删除频率大于p=0.1%的句子,并保存为停用句。
2.1.3)文本分词:本实施例根据步骤1.2输出的文本用jieba加载腾讯公开语料中的800万有用词典进行分词操作,同时去停用词(非汉字、单字),得到法律领域数据集e。
所述步骤2.2中,法律领域数据构建上下文三元组,包括以下步骤:
2.2.1)构建词汇表:根据步骤1.3输出的法律领域数据集e统计词频率,按照词频率从高到低的排序,预设的vocab_size=20000,截取前vocab_size-2=19998,大小的词保存到vocab.txt文件,在此文件的第一行添加词<eos>(每句话结束标志),第二行添加词<unk>(未知词标志)并保存,生成词汇表字典如下:
vocab_dict={<eos>:0,<unk>:1,企业:2,…,公司:19999}(1)
2.2.2)构建上下文三元组:根据步骤2.1.3输出的文本构建三元组(上文,文本,下文),第一个三元组为文本的(第一句,第二句,第三句),第二个三元组为文本的(第二句,第三句,第四句),以此类推文本可构造(文本句子数-2)个三元组。假设一个三元组的单词序列为([p1,p2,…,pp],[c1,c2,…,cc],[s1,s2,…,ss]),pp为上文中第p个单词,cc为文本中第c个单词,ss为下文中第s个单词,则根据步骤2.2.1中的词汇表字典构造文本矩阵如下:
其中p’p=vocab_dict[pp]、c’c=vocab_dict[cc]、s’s=vocab_dict[ss],若单词pp、cc、ss不在vocab_dict中,则p’p=1、c’c=1、s’s=1。
2.2.3)文本嵌入:根据步骤2.2.2输出的三元组转换为bow格式和one-hot格式即decode_pre_ids,encode_ids,decode_post_ids∈r1×20000(保留词频信息)和decode_pre_mask,encode_mask,decode_post_mask∈r1×20000(无词频信息),利用wordembedding模型将ids的每个单词分配一个固定长度为l=200的词向量表示即decode_pre_emb,encode_emb,decode_post_emb∈r20000×200,如下:
decode_pre=[2,5,1,2,5,3,0]
decode_pre_ids=[1,1,2,1,0,2,0,…,0]∈r1×20000
decode_pre_mask=[1,1,1,1,0,1,0,…,0]∈r1×20000
2.3)利用自注意力机制对文本进行编码,包括以下步骤:
2.3.1)创建q,k,v三个矢量:本实施例采用多头自注意力机制,经测试采用8头自注意力机制效果更好,首先初始化三个变量wq,wk,wv∈r200×200,将wq,wk,wv切分成h=8等分(8组初始化权重):
以此类推q,k,v三个矢量为:
本实施例通过记录步骤2.2.3输出的encode_mask=[101…0]进行扩充为
2.3.2)计算自注意力:计算文本中第一个词的自我关注(第一头注意力q1,k1,v1),第一个得分
2.3.3)keymasking:对k进行求和为key_mask,记录key_mask为0时的索引,根据步骤3.2输出的score在相同索引处替换为有区分度的小数字,本实施例为-2047,保持关注的词或字的值不变并淹没不相关的词或字;
2.3.4)输出编码向量:通过softmax将步骤2.3.3输出的分数标准化,softmax分数即此词在该位置表达的程度,由softmax分数乘以v1为z1(即第一个词的注意力向量),以此类推文本的注意力向量z1=[z1z2…z20000]∈r20000×25:将第二头注意力至第八头注意力(q2,k2,v2)-(q8,k8,v8)重复步骤2.3.2至步骤2.3.3,得到注意力z’=[z1z2…z8]∈r20000×200,初始化权重wo∈r200×200,即文本的编码向量:
encode_output=z'wo∈r20000×200(7)
2.3.5)本实施例通过单层前馈神经网络将文本编码向量作为输入,输出值通过输入值乘以权重值直接得到,输出值带着上一个编码器学习的信息传递给下一个编码器,作为下一个编码器的输入循环编码4次(经测试所得),得到最终的文本编码向量encode_output,提取的文本特征更加丰富全面。
所述步骤2.4中,利用注意力机制对上下文进行解码,包括以下步骤:
2.4.1)利用注意力机制对上文进行解码:根据步骤2.2.3输出的decode_pre_emb重复步骤2.3.1、步骤2.3.2、步骤2.3.3、步骤2.3.4得到上文编码向量decode_pre_output,同步骤2.3.1初始化三个变量wq’,wk’,wv’∈r200×200,切分成h=8等分,根据步骤2.3.4输出的文本编码向量encode_output创建q',k',v'三个矢量如下:
同公式
2.4.2)利用注意力机制对下文进行解码:同步骤2.4.1将步骤2。2.3输出的decode_post_emb重复步骤2.3.1、步骤2.3.2、步骤2.3.3、步骤2.3.4得到下文编码向量decode_post_output,根据步骤2.3.4输出的文本编码向量encode_output进行解码,计算下文中的每个单词与文本中的每个单词之间的关联度,更新下文解码向量decode_post_output,本实施例通过前馈神经网络将下文解码向量传递下一个解码器循环解码4次(经测试所得),得到最终的下文解码向量decode_post_output,学习更全面的上下文信息。
所述步骤2.5)中,利用目标函数学习上下文语义,包括以下步骤:
2.5.1)解码后的上文对齐:将步骤2.4.1更新的上文解码向量decode_pre_output∈r20000×200重构为decode_pre_output∈r1×4000000,利用全连接将decode_pre_output转为decode_pre_output∈r1×20000,利用softmax将decode_pre_output与步骤2.2.3输出的decode_pre_ids对齐,通过交叉熵函数得到上文损失
losspre=lossespre×decode_pre_mask(9)
2.5.2)解码后的下文对齐:同步骤2.5.1将步骤2.4.2更新的下文解码向量decode_post_output与步骤2.2.3输出的decode_post_ids对齐,并屏蔽干扰信息得到下文损失losspost。
2.5.3)损失更新优化:根据步骤2.5.1与步骤2.5.2输出的上文损失与下文损失,得到总损失loss=losspre+losspost,根据总损失更新编码器与解码器中的变量(wq,wk,wv,wq’,wk’,wv’)反复迭代训练网络至总损失值不再减小为止,保存网络模型为m。
所述步骤iii)中,利用自编码神经网络模型进行文档相似度计算,过程如下:
3.1)文档预处理:将文档同步骤2.1.1、步骤2.1.2、步骤2.1.3进行分句、去停用句、分词预处理得到文档doc=[a1,a2,…,an],其中
3.2)文档向量化:根据步骤2.2.1输出的词汇表字典构造文本矩阵
3.3)文档编码处理:加载步骤2.5.3输出的模型m,初始化编码层权重,将步骤3.2输出的doc_encode_emb,doc_encode_mask喂入到模型中,得到文档编码向量doc_encode_output∈rn×20000×200,重构文档编码向量为doc_encode_output∈rn×(20000×200),对文档编码向量求平均值并更新doc_encode_output∈r4000000。
3.4)文档相似度计算:将数据库中的文档与查询文档重复步骤3.1、步骤3.2、步骤3.3输出文档编码向量,由于文档编码向量维度高、数据规模大,直接应用最近邻方法并不可行,因此,最佳实践是使用逼近最近邻ann算法计算文档的相似度,本实施例采用开源hnswlib库计算文档的相似度,占用更少的内存。
- 还没有人留言评论。精彩留言会获得点赞!