一种在排序支持下的交互车辆数据分类方法与流程
本发明涉及交互分类领域,具体涉及一种车辆类别之间存在顺序关系的车辆分类交互任务。
背景技术:
在大数据时代,分类是最基础的数据分析技术和数据任务之一。虽然人们已经提出很多自动车辆数据分类方法,但没有哪种车辆分类方法能适用所有应用场景,而且以“黑盒系统”形式存在的自动车辆分类方法也影响其可解释性和可信性,对诸如图像、视频等高维复杂数据更是如此。影响可解释性和可信度的原因之一是:用户倾向于根据高层特征解读信息、度量相识度,而自动分类算法则依赖底层特征进行分类,从而形成语义鸿沟。多位学者认为允许用户参与分类过程,可以将用户的领域知识融入分类算法,进而有助于提高分类的可解释性和可信度。
基于机器学习的车辆分类算法,尤其是基于深度学习的车辆分类算法近年来在很多领域表现优异,已经成为主流车辆分类算法。基于机器学习的车辆分类算法从训练样本中学习构建车辆分类规则,因为车辆训练样本一般是用户依据自己的领域知识进行制作,所以可以认为车辆训练样本蕴含了用于分类的领域知识,这样领域知识就通过训练算法间接地融入了车辆分类算法,进而能部分克服语义鸿沟问题。但基于机器学习的车辆分类算法需要足够的高质量车辆训练样本,而大量高质量车辆训练样本并不易得,而且对于现有很多探索式车辆数据分析没有车辆训练样本,无法帮助用户获取高质量车辆训练样本,从而导致车辆分类效果不佳。另外,对于车辆分类类别间的边界点难以区分,对其分类比较困难。
技术实现要素:
本发明为了解决现有技术存在的问题,提出一种在排序支持下的交互车辆数据分类方法,以期能解决车辆类别分类无高质量训练样本和车辆分类类别间的边界点难以区分的问题,从而优化车辆分类模型,实现对待分类车辆数据集的准确分类。
为实现上述目的,本发明采用以下技术方案:
本发明一种在排序支持下的交互车辆数据分类方法的特点包含以下步骤:
步骤1、获取车辆数据训练模型:
步骤1.1、从待分类的车辆数据集s中获取n个车辆数据,并设置第i个车辆数据的车辆安全类别为pi,且pi∈{l1,l2,…,lh,…,lh},其中,{l1,l2,…,lh,…,lh}表示车辆安全类别集合,lh表示第h种车辆安全类别,且令第h种车辆安全类别lh的优先级大于第h+1种车辆安全类别lh+1;从而得到带有车辆安全类别的n个车辆数据,记为{g1,g2,…,gi,…,gn},gi表示第i个带有车辆安全类别的车辆数据,h表车辆安全类别的总数;h≤i≤n;
步骤1.2、将所述带有车辆安全类别的n个车辆数据输入支持向量机中进行训练,得到svm车辆分类模型mc,将待分类的车辆数据集s输入所述svm车辆分类模型mc中,得到车辆数据集s的分类结果记为c={c1,c2,…,cj…,cn},其中,cj表示车辆数据集s中第j个车辆数据gj的分类结果;n为车辆数据集s中车辆数据的总数;从而得到带有分类结果的车辆数据集s′,1≤j≤n;
步骤1.3、从所述带有分类结果的车辆数据集s′中获取m对车辆数据,并对任意第m对车辆数据的车辆安全类别的优先级进行比较,得到的比较结果记为qm,从而得到由m个比较结果构成的m对车辆数据的优先级集合;1≤m≤m;
步骤1.4、将所述m对车辆数据的优先级集合输入ranking-svm中进行训练,得到ranking-svm车辆排序模型mr,将所述带有分类结果的车辆数据集s′输入所述ranking-svm车辆排序模型mr中,得到车辆数据集s′的排序结果记为d={d1,d2,…,dj,…,dn},dj表示车辆数据集s′中第j个车辆数据gj的排序结果;
对所述排序结果d进行降序排序,得到降序后的排序结果d′={d′1,d′2,…,d′j,…,d′n},其中,d′j表示降序后的排序结果d′中第j个车辆数据g′j降序后的排序结果;
步骤2、获取车辆推荐数据:
步骤2.1、判断降序后的排序结果d′中相邻两个排序结果d′j和d′j+1所对应的车辆数据在分类结果c中的优先级顺序,若前者大于后者,则表示相应两个车辆数据的分类结果正常,否则,表示相应两个车辆数据的分类结果冲突;从而将所有分类结果冲突的车辆数据对组成车辆推荐数据集合;
步骤2.2、选取所述车辆推荐数据集合的每对车辆数据中排名靠前的车辆数据所对应的排名作为相应车辆数据对的排名,从而得到车辆推荐数据排名集合,记为t={t1,t2,…,tx,…,tx};tx表示第x个车辆数据对的排名,1≤x≤x;x表示车辆推荐数据对的总数;
步骤2.3、基于边界点聚集效应假设,利用式(3)得到第x个车辆数据对排名的优先级priority(tx):
式(3)中,ty表示第y个车辆数据对的排名,1≤y≤x且y≠x;
步骤3、车辆分类模型和车辆排序模型的优化:
步骤3.1、定义迭代次数为b;并初始化b=1;
步骤3.2、获取所述车辆推荐数据集合中除所述n个车辆数据以外的zb个车辆数据,且设置第z个车辆数据的车辆安全类别为pz,pz∈{l1,l2,…,lh,…,lh},1≤z≤zb;并与所述带有车辆安全类别的n个车辆数据合并成第b次迭代的数据类别集合
步骤3.3、将所述第b次迭代的数据类别集合sb输入支持向量机中进行训练,得到第b次迭代的svm车辆分类模型
步骤3.4、所述车辆推荐数据集合中获取第b次迭代的yb对车辆数据,并对任意第y对车辆数据的车辆安全类别的优先级进行比较,得到比较结果记为qy,从而得到yb个比较结果构成的第b次迭代的优先级集合;1≤y≤yb;并与所述m对车辆数据的优先级集合并成第b次迭代的总优先级集合;
步骤3.5、将所述第b次迭代的总优先级集合输入ranking-svm中进行训练,得到第b次迭代的ranking-svm车辆排序模型
步骤3.6、对所述第b次迭代的排序结果db进行降序排序,得到降序后的排序结果
步骤4、评估车辆分类模型的质量:
步骤4.1、判断第b次迭代的降序后的排序结果d′b中相邻两个排序结果
步骤4.2、选取所述第b次迭代的车辆推荐数据集合的每对车辆数据中排名靠前的车辆数据所对应的排名作为第b次迭代的相应车辆数据对的排名,从而得到第b次迭代的车辆推荐数据排名集合,记为
步骤4.3、利用式(2)得到第b次迭代的一致度pb来评价第b次迭代的svm车辆分类模型
式(2)中,pb∈[0,1];
步骤5、若pb<δ时,则将b+1赋值给b,将n+zb赋值给n,将m+yb赋值给m后,返回步骤3.2顺序执行,否则,表示完成对svm车辆分类模型的优化,并实现对待分类的车辆数据集s的最优分类。
与已有技术相比,本发明的有益效果体现在:
1、在某些车辆分类应用中,车辆类别之间存在顺序关系,且容易感知车辆数据之间的相对顺序关系。针对这种车辆分类应用场景,本发明方法借助用户对车辆数据间相对顺序关系的认知改进了交互车辆分类方法,从而提出了排序支持的交互车辆分类方法;利用该方法,用户可以尽可能少的标记车辆数据的类别,利用排序模型所提供的数据之间的顺序信息,从而减少了无效的车辆数据标记,极大的提升了车辆数据的标记效率。
2、本发明还进一步对车辆候选标注数据的推荐提出了一种基于车辆数据对的推荐方法。采用该方法,保证了那些出现问题的车辆数据一定会被推荐出来,且保证了车辆推荐数据的规模可控。
3、本发明还对车辆推荐数据的顺序有了进一步的优化;在推荐方法的初期,车辆推荐数据对会相对较多,每个车辆推荐数据都做出判断会对用户产生极大的负担;所以本发明采用基于候选点聚集度的方法,对每条车辆数据对进行评估,提升了那些聚集度较低的候选点的优先级,从而辅助用户作出相应的决策。
4、本发明还为车辆分类结果质量的评估提出了一套新的方案。为了降低用户的负担,辅助用户决定是否需要继续优化模型;本发明采用模型一致度的评估策略,使得用户对于当前车辆分类结果的好坏的判断有了相应的依据,这让用户可以更加方便的理解模型的结果,极大地提高了模型的可解释性和可信度,让训练出来的模型更容易被用户所接受。
附图说明
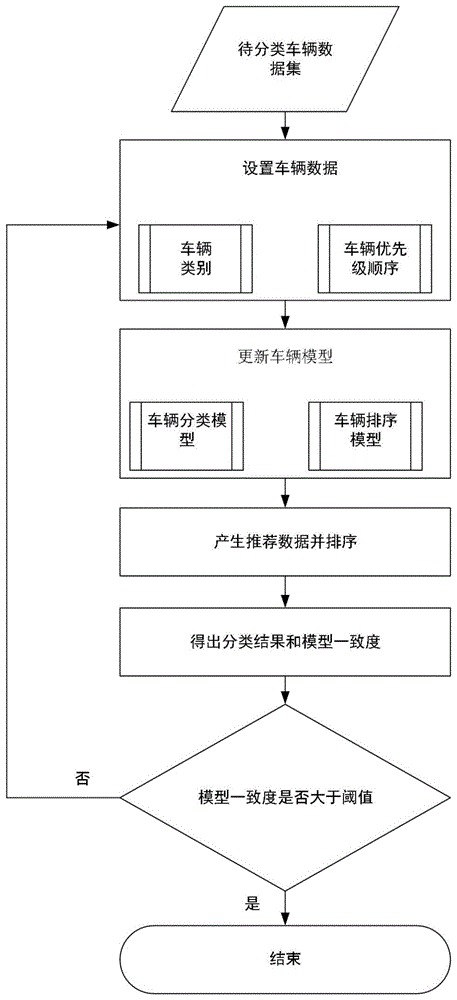
图1为发明方法流程图;
图2为本发明的车辆分类结果质量度量视图布局策略示意图。
具体实施方式
本实施例中,一种排序支持下的交互车辆数据分类方法适用于存在优先级顺序关系的车辆分类问题,着重强调支持用户输入车辆数据之间的顺序关系并将其用于优化交互分类过程,基于这一过程,既可以设置车辆数据的类别信息,还可以设置车辆数据的相对顺序关系大小,将车辆数据分类模型和车辆数据排序模型进行比较,从而利用对数据顺序关系的调整来提升交互分类的效果,并得到车辆分类模型的展示和评估。具体的说,如图1所示,是按如下步骤进行:
步骤1、获取车辆数据训练模型:
步骤1.1、从待分类的车辆数据集s中获取n个车辆数据,并设置第i个车辆数据的车辆安全类别为pi,且pi∈{l1,l2,…,lh,…,lh},其中,{l1,l2,…,lh,…,lh}表示车辆安全类别集合,lh表示第h种车辆安全类别,且令第h种车辆安全类别lh的优先级大于第h+1种车辆安全类别lh+1;从而得到带有车辆安全类别的n个车辆数据,记为{g1,g2,…,gi,…,gn},gi表示第i个带有车辆安全类别的车辆数据,h表车辆安全类别的总数;h≤i≤n;
步骤1.2、对于分类模型,因为支持向量机svm是一种小样本学习方法,且训练和预测的速度都较快,所以常被交互式分类方法所采用:一方面是因为交互式分类中难以要求用户标注大量样本用于训练;另一方面是交互式系统对速度要求较高。本发明也采用基于svm的分类模型,将带有车辆安全类别的n个车辆数据输入支持向量机中进行训练,得到svm车辆分类模型mc,将待分类的车辆数据集s输入svm车辆分类模型mc中,得到车辆数据集s的分类结果记为c={c1,c2,…,cj…,cn},其中,cj表示车辆数据集s中第j个车辆数据gj的分类结果;n为车辆数据集s中车辆数据的总数;从而得到带有分类结果的车辆数据集s′,1≤j≤n;
步骤1.3、从带有分类结果的车辆数据集s′中获取m对车辆数据,并对任意第m对车辆数据的车辆安全类别的优先级进行比较,得到的比较结果记为qm,从而得到由m个比较结果构成的m对车辆数据的优先级集合;1≤m≤m;
步骤1.4、对于排序模型,ranking-svm直观地将经典二分类svm模型应用于排序问题。将m对车辆数据的优先级集合输入ranking-svm中进行训练,得到ranking-svm车辆排序模型mr,将带有分类结果的车辆数据集s′输入ranking-svm车辆排序模型mr中,得到车辆数据集s′的排序结果记为d={d1,d2,…,dj,…,dn},dj表示车辆数据集s′中第j个车辆数据gj的排序结果;
对排序结果d进行降序排序,得到降序后的排序结果d′={d′1,d′2,…,d′j,…,d′n},其中,d′j表示降序后的排序结果d′中第j个车辆数据g′j降序后的排序结果;
步骤2、获取车辆推荐数据:
步骤2.1、本方法认为,经过分类模型得出的数据类别间的顺序关系和排序模型得出的相邻数据的顺序关系如果不一致,那么就可以认为当前的模型没有很好的处理数据,这些可以被认为是车辆推荐数据。判断降序后的排序结果d′中相邻两个排序结果d′j和d′j+1所对应的车辆数据在分类结果c中的优先级顺序,若前者大于后者,则表示相应两个车辆数据的分类结果正常,否则,表示相应两个车辆数据的分类结果冲突;从而将所有分类结果冲突的车辆数据对组成车辆推荐数据集合;
步骤2.2、选取车辆推荐数据集合的每对车辆数据中排名靠前的车辆数据所对应的排名作为相应车辆数据对的排名,从而得到车辆推荐数据排名集合,记为t={t1,t2,…,tx,…,tx};tx表示第x个车辆数据对的排名,1≤x≤x;x表示车辆推荐数据对的总数;
步骤2.3、基于“边界点聚集效应假设”,希望能优先处理远离边界的数据,这样能快速处理数据,进而迭代模型。但并不知道真实的分类边界,那么如何衡量数据点到边界的距离呢?根据“边界点聚集效应假设”,如果某个候选标注数据在边界周围,那么附近应该有很多其他候选标注数据。基于这个认识,该发明采用候选标注数据的聚集度度量它到边界的距离,,利用式(3)得到第x个车辆数据对排名的优先级priority(tx):
式(3)中,ty表示第y个车辆数据对的排名,1≤y≤x且y≠x。priority(tx)表示数据对中任何一个数据越远离分类边界时,这个数据点对的排名优先级越高。候选数据集合按优先级从高到低显示所有候选数据点对。比如对于进行“高危车辆、中危车辆、低危车辆”三分类的问题。根据式(4),“低危车辆-中危车辆”和“低危车辆-高危车辆”不一致对p的影响一样,而实际上它们的影响也的确存在差别。因此用如图2所示(m-1)×(m-1)的三角阵展示不同类别之间出现混淆的候选数据点,三角阵的横坐标从左到右为(c1,c2,...cm-1),纵坐标从上到下为(c2,c3,...cm),第(i,j)区域中展示ci和cj之间出现混淆的候选点。
步骤3、分类模型和排序模型的优化:
步骤3.1、通过对推荐数据集合中的推荐数据进一步处理后,来优化模型。定义迭代次数为b;并初始化b=1;
步骤3.2、获取车辆推荐数据集合中除n个车辆数据以外的zb个车辆数据,且设置第z个车辆数据的车辆安全类别为pz,pz∈{l1,l2,…,lh,…,lh},1≤z≤zb;并与带有车辆安全类别的n个车辆数据合并成第b次迭代的数据类别集合
步骤3.3、将第b次迭代的数据类别集合sb输入支持向量机中进行训练,得到第b次迭代的svm车辆分类模型
步骤3.4、车辆推荐数据集合中获取第b次迭代的yb对车辆数据,并对任意第y对车辆数据的车辆安全类别的优先级进行比较,得到比较结果记为qy,从而得到yb个比较结果构成的第b次迭代的优先级集合;1≤y≤yb;并与m对车辆数据的优先级集合并成第b次迭代的总优先级集合;
步骤3.5、将第b次迭代的总优先级集合输入ranking-svm中进行训练,得到第b次迭代的ranking-svm车辆排序模型
步骤3.6、对第b次迭代的排序结果db进行降序排序,得到降序后的排序结果
步骤4、评估分类模型的质量:
交互数据分类方法是由交互驱动迭代过程,所以要通过观察到的信息对当前分类结果进行评估,进而决定是否需要继续迭代。虽然可以观察分类结果,但难以对分类结果的质量形成直观认识。
步骤4.1、判断第b次迭代的降序后的排序结果d′b中相邻两个排序结果
步骤4.2、选取第b次迭代的车辆推荐数据集合的每对车辆数据中排名靠前的车辆数据所对应的排名作为第b次迭代的相应车辆数据对的排名,从而得到第b次迭代的车辆推荐数据排名集合,记为
步骤4.3、利用式(2)得到第b次迭代的一致度pb来评价第b次迭代的svm车辆分类模型
式(2)中,pb∈[0,1],模型一致度pb表示分类结果和排序结果一致程度,pb越大表示分类结果的质量越高,分类模型越好。
步骤5、若pb<δ时,则将b+1赋值给b,将n+zb赋值给n,将m+yb赋值给m后,返回步骤3.2顺序执行,否则,表示完成对svm车辆分类模型的优化,并实现对待分类的车辆数据集s的最优分类。
- 还没有人留言评论。精彩留言会获得点赞!