一种基于自然语言处理和知识图谱的智能问答方法与流程
本发明涉及人工智能技术领域,特别是涉及一种基于自然语言处理和知识图谱的智能问答方法。
背景技术:
智能问答系统根据用途通常分为任务型和非任务型两种,非任务型主要包括闲聊、知识问答、推荐。
非任务型中的闲聊型对话中的对话管理(dialoguemanagement,dm)就是对上下文进行序列建模、对候选回复进行评分、排序和筛选等,以便于自然语言生成(naturallanguagegeneration,nlg)阶段生成更好的回复;自然语言生成是对话的最后一步,是系统对用户的回答。也可以基于深度学习进行注意力、强化学习建模。知识问答型对话中的dm就是在问句的类型识别与分类的基础上,进行文本的检索以及知识库的匹配,以便于nlg阶段生成用户想要的文本片段或知识库实体。推荐型对话系统中的dm就是进行用户兴趣的匹配以及推荐内容召回、排序等,以便于nlg阶段生成更好的给用户推荐的内容。
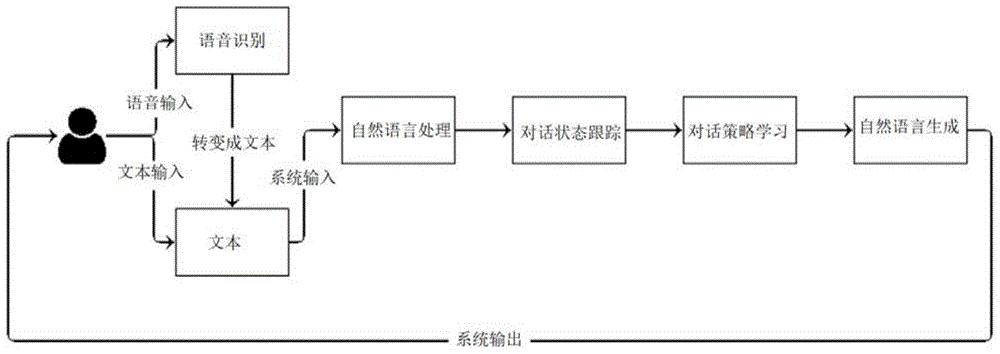
任务型对话中的dm就是在nlu(领域分类和意图识别、槽填充)的基础上,进行对话状态的追踪(dialoguestatetracking,dst)以及对话策略的学习(dialoguepolicylearning,dpl),以便于dpl阶段策略的学习以及nlg阶段澄清需求、引导用户、询问、确认、对话结束语等。dst是根据当前的意图(intention)、槽值对(slot-valuepairs)、以及之前的意图来追踪当前的状态,简而言之,就是当前处理的上下文。dpl就是根据当前的状态(state)决定下一步的动作。任务型对话可为短对话(shortconversation)也可为长对话(longconversation),短对话指的是一问一答式的单轮(singleturn),长对话指的是你来我往的多轮(multi-turn),对于任务型对话而言,长对话更为常见,传统任务型对话一般流程如图1所示。
现有聊天系统技术的缺点是任务型对话和非任务型对话缺乏统一的方案,对于无法预测的话轮,也就是不确定的、不必要的话轮及场景内调用其它场景上,缺乏处理的方法。
技术实现要素:
本发明的目的是针对现有聊天系统技术中存在的任务型对话和非任务型对话缺乏统一的方案,对于无法预测的话轮,也就是不确定的、不必要的话轮及场景内调用其它场景上,缺乏处理的方法,而提供一种基于自然语言处理和知识图谱的智能问答方法。
为实现本发明的目的所采用的技术方案是:
一种基于自然语言处理和知识图谱的智能问答方法,在对话策略学习阶段中,通过对设置的必要属性的学习,识别出不确定话轮,使该不确定话轮与知识图谱交互,由知识图谱进行处理反馈,输出反馈结果;
若当前场景下识别到用户有调用新场景意图,则通过对话嵌套从当前场景跳转到新场景进行对话。
优选的,若某个话轮在当前场景不存在,则在对话历史中查询是否存在某个话轮,若存在,则跳转到此话轮中并将此话轮执行的历史中的场景通过嵌套置为当前场景,然后进行此话轮的执行。
优选的,所述在对话历史中查询是否存在某个话轮,通过知识图谱来实现。
与现有技术相比,本发明的有益效果是:
本发明通过在智能问答系统中引入知识图谱的推理和对话的嵌套,解决了现有聊天系统技术的缺点,即对于无法预测的话轮及场景内调用其它场景无法处理的问题。
附图说明
图1所示为现有基于自然语言处理的智能问答方法的原理图
图2所示为基于自然语言处理和知识图谱的智能问答方法的原理图;
图3-5所示分别为用有限状态自动机进行智能问答规则设计的不同方案图;
图6所示为本发明的用有限状态自动机进行智能问答规则设计的原理图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图2所示,本发明基于自然语言处理和知识图谱的智能问答方法,具体是在在对话策略学习阶段中,通过对设置的必要属性的学习,识别出不确定话轮,使该不确定话轮与知识图谱交互,由知识图谱进行处理反馈,输出反馈结果;若当前场景下识别到用户有调用新场景意图,则通过对话嵌套从当前场景跳转到新场景进行对话。
本发明提出的对话中,对不必要部分的话轮(不确定话轮或称为无法预知的话轮)的处理,在充分考虑必要部分话轮中,系统与用户的交互之后,提出系统与知识图谱的交互,通过知识图谱的逻辑来模拟用户的逻辑来进行问询操作,解决了现有对话中对于无法预测的话轮无法处理的问题。
另外,通过对话嵌套实现的当前场景跳转到新场景进行对话,从而解决了现有对话中场景内调用其它场景无法实现的技术问题。
优选的,若某个话轮在当前场景不存在,则在对话历史中查询是否存在某个话轮,若存在,则跳转到此话轮中并将此话轮执行的历史中的场景通过嵌套置为当前场景,然后进行此话轮的执行。
下面根据智能问答的技术,对本发明的实现进行详细说明如下:
在智能问答系统中,数据是结构化存储的,结构化存储的数据按照意图或场景进行分类,包括场景名字、意图名字、参数列表、应答模板。其中参数列表包括参数名、是否必要、提示语三个组成部分。应答模板用于响应用户的问题;参数列表用于与从序列标注中抽取的槽位进行比较,确定对话话轮。如下例子,对于“运输货物”这个场景,“您的货物将从{{parameters["从"]}}运到{{parameters["到"]}}”。这里的“从”、“到”就是参数,提示语分别为“您的始发地是哪里?”、“您的目的地是哪里?”。意图名为“运输货物。将上述四个字段存入数据库中,备以后查询分析。
又如“预约转人工”的场景,应答模板为“您预留的电话号码是{{parameters["电话号码"]}},咨询的业务是{{parameters["业务"]}},稍后将有客服人员主动联系您,请保持电话的畅通。”这里的“电话号码”,“业务”就是参数,分别设置为必要,提示语分别为“请您留下电话号码?”,“请留下您要咨询的问题?”意图名为“预约转人工”。将上述字段存入数据库中,必备以后查询分析。
智能应答系统一般分为自然语言处理,对话状态跟踪,对话策略学习与自然语言生成四个处理阶段,自然语言生成是对话的最后一步,是系统对用户的回答。如图1所示。
其中,自然语言处理是将用户输入的自然语言映射为用户的意图和相应的槽位、槽值。因此自然语言处理的输入是用户对话语句,输出是解析后得到的用户动作,用户动作包括意图和槽位,涉及的技术是意图识别和槽位识别及填充。意图和槽位共同构成“用户动作”,因为机器无法直接理解自然语言,所以用户动作的作用便是将自然语言映射为机器能够理解的结构化语义表示。
意图识别可以由但不局限于分类算法完成。槽位也就是意图的参数,一个意图可以有若干个或着零个参数,槽位识别可以由但不局限于序列标注完成。
示例:
用户输入示例:“今天北京的天气怎么样”
用户意图定义:询问天气
槽位定义:
槽位一:时间
槽位二:地点
在上述示例中,针对“询问天气”意图定义了两个必要的槽位,它们分别是“时间”和“地点”。时间的值是“今天”,地点的值是“北京”。
对话状态跟踪(dst)的输入是用户动作和以前的对话状态,输出是对话状态跟踪判定的当前对话状态。对话状态的表示(dst-staterepresentation)通常包括以下三部分:当前槽位的填充情况,本轮对话过程中的用户动作,对话历史。
对话策略学习(dpl)的输入是dst的输出,通过预设的对话策略,选择某动作作为输出。比如用户输入今天北京天气怎么样?对应的策略就是一次性识别所有的槽位,即时间的槽位,其槽值是今天,地点的槽位,其槽值为北京。其次也可以采用话轮的策略,比如:用户的输入:查询天气。系统提问:请问查询那天的?用户回答:今天的,其槽位就是时间,槽值就是今天;系统再问:请问查询哪里的?用户回答:北京的,则其槽位是地点,槽值是北京。
通常在智能应答中,采用有限状态自动机来进行智能应答规则设计,有两种不同方案:第一种,以点表示数据,以边表示操作;第二种,以点表示操作,以边表示数据。方案一,如图3所示,这里点表示槽位状态,边表示系统动作。每一个对话状态s表示槽位的填充状态,槽位的状态转移由系统动作引起。槽位均为空时,状态为“空”,表示为(0,0);只有时间槽位被填充时状态为(1,0),全部被填充时表示为(1,1),只有地点被填充时表示为(0,1)。本例中共有槽位2个,22个不同的状态。当系统动作发出“询问地点”的动作后,状态将转向“s2”,如果成功填充,则转向状态“s2”,如果不成功,将发起“再次询问”的动作。直至识别到状态“(1,1)”。
方案一的弊端:随着槽位数量的增加,对话状态的数量也会急剧增加。具体来说,在上述方案中,对话状态的总数由槽位的个数决定,如果槽位有k个,那么对话状态的数量为2k个。
方案二,如图4,图4中以点表示系统动作,以边表示槽位状态。在这种情况下,有限状态自动机中每一个对话状态s,表示的是一种系统动作,本例中系统动作共有三种,分别是,询问时间、询问地点、回答。状态的变化是由槽位的状态变化引起的。
上述两种方案,第二种有限状态自动机以系统动作为核心,设计更简单,更易于工程实现。第一种有限状态自动机以槽位状态为核心,枚举所有槽位情况,更适合数据驱动的机器学习方式。这两种方案各有优缺点,在具体实现时可以根据实际情况进行选择。
在智能应答中,系统动作的定义通常包括问询、确认、回答等三种。问询是系统要解决槽位缺失的问题,确认是系统要解决容错性问题,回答是系统的最终回复。
对于不确定的话轮,即不必要话轮,系统无法预知的话轮,本发明将上述的不必要的话轮部分系统与用户的交互转变成系统与知识图谱的交互,一般而论,用户将不再参与。另外对于其它的情况,上述与用户交互和与知识图谱的交互的其它的共性的交互都可利用知识图谱分析,查询,推理等等。可以使用方案一来完成;也可将上述两种有限状态自动机结合起来,以方案二中的点表示操作,边表示数据的有限状态自动机为基础融入方案一中的点表示数据,边表示操作,以此为方案但不局限于此。这里使用结合方案来演示,如图5所示。
下面,举个买火车票的例子,如图6所示,假设有时间、始发站、终点站这些必要属性,其它的必要属性同理,这些必要属性都可以通过与用户的交互,来让用户一一回答。但是用户要是说“我要最快的火车票”,这个要求就是不必要的话轮了,既然用户提了出来,我们就用知识图谱来解决这个问题,具体就是利用知识图谱来分析推理查询出是否火车票有这个属性。也就是说发明在不必要话轮部分来用知识图谱来代替人与系统交互。
如果用户在本场景中对话时想调用新的场景,可以通过嵌套完成的。比如在进行人工咨询对话时,用户要查询天气,是通过“查询天气场景”完成的。用户需要发送“查询天气”消息,系统会通过调用意图识别模型识别,进入“查询天气场景”,在查询天气场景内完成相应的对话后返回人工咨询场景,人工咨询场景会做进一步处理。另外多层的嵌套也是这个道理。
对话中,场景内的某个话轮不存在,允许系统在以前的对话历史中查询是否存在当前的话轮(可以通过知识图谱实现),若存在,则跳转到这个话轮中并将这个话轮执行的场景置为当前场景,在这个话轮执行完后,再回到先前的话轮。对于多个的嵌套以此类推。
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!