一种词汇表的筛选方法与流程
本发明涉及词汇筛选技术领域,特别涉及一种词汇表的筛选方法。
背景技术:
众所周知,词汇表的选取,对深度学习性能的影响巨大,词汇表如果过大,一方面会影响线上系统的性能;另一方面也不太现实,因为各种语言中都会有层出不穷的新词、合成词出现,即词汇表规模是没有上限的;词汇表如果太小,也会造成很多未登录词在实际应用中频繁出现的问题,因此选择合适的词汇就显得非常重要。
而且,根据zipf’slaw可知,大部分的词汇是处于词频长尾的部分。并根据筛选词汇的现有技术而言,但是一般对词汇的筛选,仅仅是按照语料库中词频等通用的统计信息给出词的权重,排序后取topn的词放入词汇表。在采用其方法对词汇筛选的过程中存在以下几个问题:第一、topn的选取在通用词频的统计下没有意义:通常是通过工程上的需要,来决定n的大小。但是查看全部词汇表发现,不论n取何值(n取所有词大小的情况不考虑),被舍去的词中总会存在一些出现次数少的关键词;第二、高频词汇,从句子层面的统计意义上来讲,不一定比低频的词汇更有用,如从语料库中统计出来的高频词the,对比pyrid这样的专有名词来说,就显得不是那么重要。通过以上表述,仅仅只用词频作为筛选词表的依据,是不够的。
技术实现要素:
本发明提供一种词汇表的筛选方法,用以提高筛选词汇的准确性和可靠性。
本发明实施例提供一种词汇表的筛选方法,包括:
确定预设词汇在预先存储的语料库中出现的频率;
确定预设词汇在预先存储的语料库中的预设语段中的位置信息,并根据所述位置信息获得所述预设词汇对应的位置熵;
根据所确定的预设词汇在预先存储的语料库中出现的频率和获得的所述预设词汇对应的位置熵,计算出所述预设词汇的权重;
根据所计算出的所述预设词汇的权重结果,从预先存储的语料库中筛选出相关的预设词汇,构成筛选词汇表。
在一种可能实现的方式中,所述确定预设词汇w在预先存储的语料库中出现的频率,包括:
设定预设词汇w在预先存储的语料库中出现的频率,对应的预设词汇w的词频,用q(w)表示,计算方法为:
其中,nw表示预设词汇w在语料库中出现的次数,n表示语料库中所有词汇的总数目;
所述确定预设词汇在预先存储的语料库中的预设语段中的位置信息,并根据所述位置信息获得所述预设词汇对应的位置熵,包括:
设定所述预设词汇w在预先存储的语料库中的预设语段中的位置熵,用h(w)表示,如下:
其中,l表示预设词汇w在预先存储的语料库中的预设语段中的位置,l的取值范围为:l={s,b,i,e},s表示在预先存储的语料库中的预设语段中只有一个预设词汇w的位置,b表示预设词汇w处在预先存储的语料库中的预设语段中的开头位置,i表示预设词汇w处在预先存储的语料库中的预设语段中的中间位置,e表示预设词汇w处在预先存储的语料库中的预设语段中的结尾位置;
上述p(l)表示某一个位置l的概率,如下:
其中,n表示预先存储的语料库中所有词汇的总数,nl表示处在在预先存储的语料库中的预设语段中位置为l处的预设词汇w的个数;
上述p(w|l)表示预设词汇w被标为位置标签l的概率:
其中,nlw表示在预先存储的语料库中预设词汇w被标为位置标签l的次数;
所述根据所确定的预设词汇在预先存储的语料库中出现的频率和获得的所述预设词汇对应的位置熵,计算出所述预设词汇的权重,包括:
根据预设词汇w的位置熵用h(w)和词频q(w),获取预设词汇w的权重weight(w)表示如下:
weight(w)=αq(w)-(1-α)h(w)
其中α是平衡词频和位置熵的平滑参数;
所述根据所计算出的所述预设词汇的权重结果,从预先存储的语料库中筛选出相关的预设词汇,构成筛选词汇表,包括:
步骤(1):根据获取的预设词汇w的权重,计算所述在预先存储的语料库中每个词汇wi的权重weight(wi),其中,wi代表标点任务对应的语料库中第i个不同的预设词汇,且i=1,2,3...n,n≦n;
步骤(2):将每个词汇wi对应的权重从高到低进行排列;
步骤(3):根据排列结果筛选出前m个词汇组成筛选词汇表,其中m≦n。
在一种可能实现的方式中,所述方法还包括:
根据所述位置熵判断所述预设词汇在所述预先存储的的语料库中的预设语段中的位置是否固定;
当所获取的预设词汇对应的位置熵小于预设熵值时,判定所述预设词汇在所述预先存储的语料库中的预设语段中所出现的位置不固定,输出与所述预设词汇位置不固定相关的第一提示信息,用于提示用户所述预设词汇的位置不固定,所述用户根据所述第一提示信息执行相应的第一提示操作;
否则,判定所述预设词汇在所述预先存储的语料库中的预设语段中所出现的位置固定。
在一种可能是实现的方式中,所述方法还包括:
根据所述预设词汇在预先存储的语料库中出现的频率,判断所述预设词汇在所述预先存储的语料库中出现的频率是否小于预设频率;
若是,判定所述预设词汇在所述预先存储的语料库中出现的词频低,输出与所述预设词汇词频低相关的第二提示信息,用于提示用户所述预设词汇在所述预先存储的语料库中出现的词频低,所述用户根据所述第二提示信息执行相应的第二提示操作;
否则,判定所述预设词汇在所述预先存储的语料库中出现的词频高。
在一种可能是实现的方式中,
所述第一提示信息或第二提示信息是采用语音提示方式、文字提示方式中任一种或多种的提示方式的组合。
在一种可能是实现的方式中,所述方法还包括:
在根据所计算出的所述预设词汇的权重结果,从预先存储的语料库中筛选出相关的预设词汇,构成筛选词汇表之前,需要对词汇筛选表的存储容量进行预估,其步骤包括:
获取所述预先存储的语料库中词汇的总数目;
判断语料库中每个所述词汇所占用的字节大小;
根据语料库中每个所述词汇所占用的字节大小的判断结果获取所述语料库中所有词汇所占用的总字节;
根据预设占比并基于所述语料库中所有词汇所占用的总字节,获取词汇表的预估存储容量;
其中,所述预设占比是基于对所述语料库中对应的所述预设词汇所出现的频率,并且当预设词汇出现的频率大于或等于预设频率时,对应的所有大于或等于预设频率的预设词汇在所述语料库中的占比。
在一种可能实现的方式中,所述方法还包括:
获取基于深度学习的标点任务的任务属性,所述任务属性包括:与标点任务相关的任务类别、与标点任务相关的任务库;
根据所述任务属性,从预先存储的标点模型库中调取相关的自动标点模型;
基于获取的所述筛选词汇表,并根据所调取的自动标点模型,对所述标点任务进行标点;
其中,自动标点模型是通过获取与至少一个标点任务对应的任务主题相关的若干个标点样本,并使用所述若干个标点样本,对至少一个设定深度学习模型进行训练,获得与所述标点任务对应的任务主题相关的至少一个所述自动标点模型;
且所述标点模型库中包括至少一种自动标点模型。
在一种可能实现的方式中,
获取基于深度学习的标点任务的任务属性的步骤包括:
对所述标点任务中的关键词进行标记,并将所述标点任务中的所标记的关键词进行提取,获取与所述标点任务相关的关键信息;
根据所述关键信息,获取所述标点任务的任务类别、及获取与标点任务相关的任务库。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种词汇表的筛选方法的结构示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
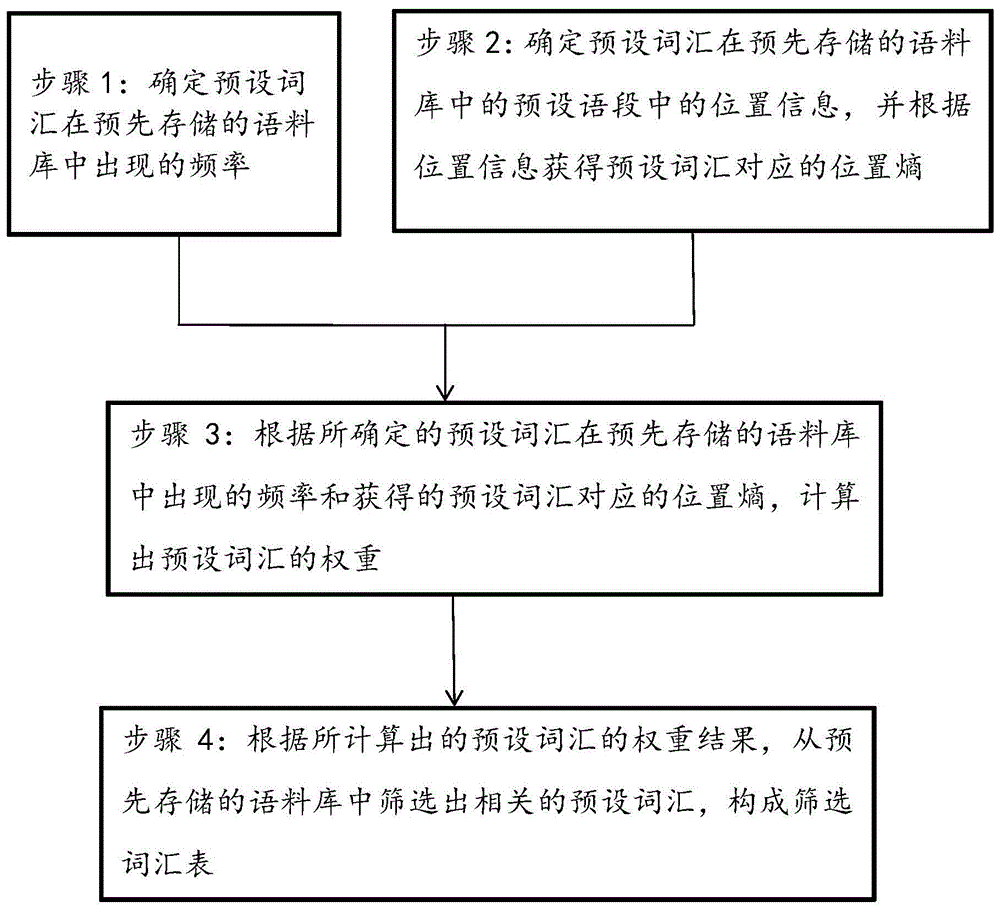
本发明实施例提供一种词汇表的筛选方法,如图1所示,包括:
步骤1:确定预设词汇在预先存储的语料库中出现的频率;
步骤2:确定预设词汇在预先存储的语料库中的预设语段中的位置信息,并根据位置信息获得预设词汇对应的位置熵;
步骤3:根据所确定的预设词汇在预先存储的语料库中出现的频率和获得的预设词汇对应的位置熵,计算出预设词汇的权重;
步骤4:根据所计算出的预设词汇的权重结果,从预先存储的语料库中筛选出相关的预设词汇,构成筛选词汇表。
预先存储的语料库中每个不同的词汇,都可称为预设词汇;且预先存储的语料库中包括至少一条预设语段,每个预设语段包含若干个词汇。
上述确定预设词汇在预先存储的语料库中的预设语段中的位置信息,是为了判断预设词汇所处的位置是预设语段的开头位置、中间位置、结尾位置或者该预设语段中只有一个预设词汇的位置,可有效提高位置熵的准确性。
从预先存储的语料库中筛选出相关的预设词汇,是对语料库中的每个不同的预设词汇都进行了权重计算,方便根据权重筛选词汇。
上述预先存储的语料库包括但不限于数字、字母、文字等一种或多中的组合词汇。
上述技术方案的有益效果是:用以提高筛选词汇的准确性和可靠性。
本发明实施例提供一种词汇表的筛选方法,
对于步骤1,确定预设词汇w在预先存储的语料库中出现的频率,包括:
设定预设词汇w在预先存储的语料库中出现的频率,对应的预设词汇w的词频,用q(w)表示,计算方法为:
其中,nw表示预设词汇w在语料库中出现的次数,n表示语料库中所有词汇的总数目;
对于步骤2,确定预设词汇在预先存储的语料库中的预设语段中的位置信息,并根据位置信息获得预设词汇对应的位置熵,包括:
设定预设词汇w在预先存储的语料库中的预设语段中的位置熵,用h(w)表示,如下:
其中,l表示预设词汇w在预先存储的语料库中的预设语段中的位置,l的取值范围为:l={s,b,i,e},s表示在预先存储的语料库中的预设语段中只有一个预设词汇w的位置,b表示预设词汇w处在预先存储的语料库中的预设语段中的开头位置,i表示预设词汇w处在预先存储的语料库中的预设语段中的中间位置,e表示预设词汇w处在预先存储的语料库中的预设语段中的结尾位置;
上述p(l)表示某一个位置l的概率,如下:
其中,n表示预先存储的语料库中所有词汇的总数,nl表示处在在预先存储的语料库中的预设语段中位置为l处的预设词汇w的个数;
上述p(w|l)表示预设词汇w被标为位置标签l的概率:
其中,nlw表示在预先存储的语料库中预设词汇w被标为位置标签l的次数;
对于步骤3,根据所确定的预设词汇在预先存储的语料库中出现的频率和获得的预设词汇对应的位置熵,计算出预设词汇的权重,包括:
根据预设词汇w的位置熵用h(w)和词频q(w),获取预设词汇w的权重weight(w)表示如下:
weight(w)=αq(w)-(1-α)h(w)
其中α是平衡词频和位置熵的平滑参数;
对于步骤4,根据所计算出的预设词汇的权重结果,从预先存储的语料库中筛选出相关的预设词汇,构成筛选词汇表,包括:
步骤(1):根据获取的预设词汇w的权重,计算在预先存储的语料库中每个词汇wi的权重weight(wi),其中,wi代表标点任务对应的语料库中第i个不同的预设词汇,且i=1,2,3...n,n≦n;
步骤(2):将每个词汇wi对应的权重从高到低进行排列;
步骤(3):根据排列结果筛选出前m个词汇组成筛选词汇表,其中m≦n。
根据获取的位置熵,判断对应的预设词汇所处的位置是否固定,即位置熵值越小,其预设词汇在预设语段中的位置越固定;
同时,结合预设词汇对应的词频信息,则可获得“位置固定、词频高”的预设词汇的权重较大,而“位置不固定、词频小”的预设词汇的权重较小。
上述技术方案就是为了保留“在预设语段中的位置固定且词频大”的预设词汇。
上述技术方案的有益效果是:通过设计参数算法,可以将词频大、位置固定的词汇筛选出来,提高此类词汇在筛选词汇表中的占比,进一获取具有代表性的词汇。
本发明实施例提供一种词汇表的筛选方法,该方法还包括:
根据位置熵判断预设词汇在预先存储的的语料库中的预设语段中的位置是否固定;
当所获取的预设词汇对应的位置熵小于预设熵值时,判定预设词汇在预先存储的语料库中的预设语段中所出现的位置不固定,输出与预设词汇位置不固定相关的第一提示信息,用于提示用户预设词汇的位置不固定,用户根据第一提示信息执行相应的第一提示操作;
否则,判定预设词汇在预先存储的语料库中的预设语段中所出现的位置固定。
上述第一提示信息可以是通过采用语音提示方式、文字提示方式中任一种或多种的提示方式的组合,对用户进行第一提示信息的提示;且第一提示操作可以是用户将其第一提示信息中的相关预设词汇进行删除或保留,其好处是,用户可根据自己的需求来选择是否将这类位置不固定的词汇添加到词汇表中,更加满足用户的需求。
本发明实施例提供一种词汇表的筛选方法,方法还包括:
根据预设词汇在预先存储的语料库中出现的频率,判断预设词汇在预先存储的语料库中出现的频率是否小于预设频率;
若是,判定预设词汇在预先存储的语料库中出现的词频低,输出与预设词汇词频低相关的第二提示信息,用于提示用户预设词汇在预先存储的语料库中出现的词频低,用户根据第二提示信息执行相应的第二提示操作;
否则,判定预设词汇在预先存储的语料库中出现的词频高。
上述第二提示信息可以是采用语音提示方式、文字提示方式中任一种或多种的提示方式的组合,对用户进行第二提示信息的提示;且第二提示操作可以是用户将其第二提示信息中的相关预设词汇进行删除或保留,其好处是,用户可根据自己的需求来选择是否将这类小于预设频率的词汇添加到词汇表中,可更加满足用户的需求。
本发明实施例提供一种词汇表的筛选方法,方法还包括:
在根据所计算出的预设词汇的权重结果,从预先存储的语料库中筛选出相关的预设词汇,构成筛选词汇表之前,需要对词汇筛选表的存储容量进行预估,其步骤包括:
获取预先存储的语料库中词汇的总数目;
判断语料库中每个词汇所占用的字节大小;
根据语料库中每个词汇所占用的字节大小的判断结果获取语料库中所有词汇所占用的总字节;
根据预设占比并基于语料库中所有词汇所占用的总字节,获取词汇表的预估存储容量;
其中,预设占比是基于对语料库中对应的预设词汇所出现的频率,并且当预设词汇出现的频率大于或等于预设频率时,对应的所有大于或等于预设频率的预设词汇在语料库中的占比。
例如,语料库中有100个词汇,且这100个词汇中有60种不同的词汇,其中有35种不同的词汇在该语料库中出现的频率是在2%以上,则将该35种不同的词汇中每个词汇所占用的字节大小及对应的同词汇的数量进行统计,获得这35种所有词汇的总字节的存储空间大小,并作为预估存储容量。
上述技术方案的有益效果是:对筛选词汇表的词汇容量进行预估,避免因筛选的词汇过多,导致不能将筛选出的词汇全部放置到存储空间,使得不能完整的获得筛选的词汇,或者避免因筛选的词汇过少,不能对存储空间进行完全占用,导致对存储空间的浪费。
本发明实施例提供一种词汇表的筛选方法,该方法还包括:
获取基于深度学习的标点任务的任务属性,任务属性包括:与标点任务相关的任务类别、与标点任务相关的任务库;
根据任务属性,从预先存储的标点模型库中调取相关的自动标点模型;
基于获取的筛选词汇表,并根据所调取的自动标点模型,对标点任务进行标点;
其中,自动标点模型是通过获取与至少一个标点任务对应的任务主题相关的若干个标点样本,并使用若干个标点样本,对至少一个设定深度学习模型进行训练,获得与标点任务对应的任务主题相关的至少一个自动标点模型;
且标点模型库中包括至少一种自动标点模型。
上述的任务类别,例如可以是财经标点任务类别、广告标点任务类别、运动标点任务类别等;与标点任务相关的任务库,例如可以是财经语料库、广告语料库、运动语料库等。
需要说明的是,上述筛选词汇表是基于任务属性获取的,例如,任务属性是关于运动的,则可以筛选“篮球”、“足球”、“跳水”、“长跑”等与运动相关的词汇。
上述技术方案的有益效果是:通过将筛选词汇表与自动标点模型结合,通过充分发挥筛选词汇表的作用,完成对标点任务的标点,可以提高自动标点的准确性。
本发明实施例提供一种词汇表的筛选方法,
获取基于深度学习的标点任务的任务属性的步骤包括:
对标点任务中的关键词进行标记,并将标点任务中的所标记的关键词进行提取,获取与标点任务相关的关键信息;
根据关键信息,获取标点任务的任务类别、及获取与标点任务相关的任务库。
例如,标点任务是“高中举办的篮球比赛”,对“高中举办的篮球比赛”中的关键词“篮球”进行标记,并将“篮球”进行提取,获得与篮球相关的运动信息,并根据运动信息获取到相关的“运动标点任务类别”、及“运动语料库”。
上述技术方案的有益效果是:通过对关键词进行标记和提取,可以有效的获取到标点任务的任务属性。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!