一种陆战兵棋智能引擎及其运行方法与流程
本发明涉及一种陆战兵棋智能引擎及其运行方法,针对兵棋平台,综合数据挖掘、多属性综合评价软优选的方法,设计一种智能引擎。
背景技术:
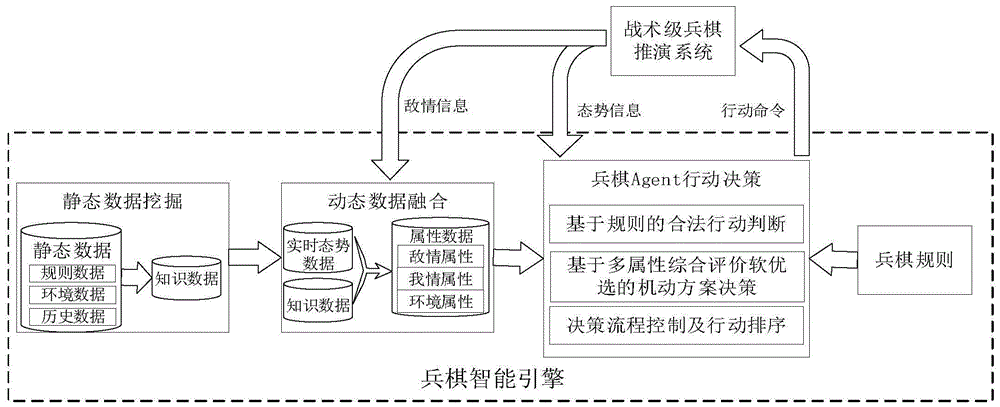
:借助于计算机技术的发展,传统的严格式兵棋开始数字化。我国计算机兵棋技术起步较晚,近年来成为各高校和公司企业的研究热点,研究内容主要集中在阐述兵棋的本质和特点、研究兵棋地图技术、棋子机动算法、推演规则体系等,一些公司或研究机构设计研发了战术级、战役级等不同规模、不同合成兵种的兵棋推演系统。传统的兵棋自动推演多是人工操作,人人对抗模式,随着物联网、大数据、人工智能技术的发展,智能化兵棋开始成为研究的热点。兵棋智能引擎,是指针对兵棋推演平台开发的能够接收推演平台的态势信息,经过分析处理后输出推演动作的一个智能软件模块,它起到了模拟人类进行兵棋推演的作用。兵棋智能引擎实现的技术途径主要有,规则推理、搜索算法和数据挖掘三种途径。基于规则推理的智能引擎根据兵棋规则进行推理运行,一般输出的动作比较固定,缺乏变化性,其运行规律很容易被对手掌握;基于搜索算法的智能引擎因兵棋状态空间巨大,需要消耗大量计算资源,计算时间较长,实时性不强;基于数据挖掘的智能引擎需要挖掘以往历史推演数据中的经验知识,对数据的数量和质量要求较高。近年来,在军队内部和地方高校举办了系列兵棋推演比赛,赛后计算机系统积累了大量的比赛数据,这些数据为基于数据知识挖掘的智能兵棋引擎提供了数据资源。目前,在兵棋数据的挖掘、特征提取等问题上,提出了一些方法,但以理论研究和探讨为主,提取的特征主要是供人类指挥员分析判断情况使用,一套完整的可成熟运行的基于数据知识挖掘的兵棋智能引擎实现还未取得实质性进展。技术实现要素:发明目的:针对现有基于规则的兵棋智能引擎走子固定,基于搜索算法的兵棋智能引擎计算时间长的缺点,设计实现了陆战兵棋智能引擎,降低了所需的计算资源,提升了运行的实时性和走子的灵活性,具备了较高的自主智能水平。技术方案:本发明首先设计了兵棋实体作战行动智能决策模型框架,如图1所示。静态数据挖掘对兵棋数据中的规则数据、环境数据和历史数据进行挖掘,提取与决策相关的静态的知识数据。动态数据融合对知识数据和推演系统的实时态势进行数据融合,形成决策相关的属性数据。多agent行动序列决策综合兵棋基本规则、态势数据和属性数据,完成兵棋作战实体的行动命令生成。行动命令发送到战术级兵棋推演系统后被执行,推演系统会将新的态势数据传递出来。如此循环,实现兵棋推演系统的智能决策。一种陆战兵棋智能引擎,在兵棋实体作战行动智能决策模型框架的指导下,进行细化设计并编程实现。该引擎分为总体技术框架和运行框架,技术框架包括兵棋数据挖掘融合模块、以多属性综合评价软优选算法为核心的决策模块;运行框架包括敌情处理模块、多个动作模块和运行流程框架。所述兵棋数据的挖掘融合模块将兵棋数据中的静态数据经数据挖掘算法提取关键信息数据元素,形成基础知识数据,与兵棋推演系统实时产生的动态数据进行数据融合,生成符合人类直观理解的三类属性数据:敌情属性,我情属性和环境属性;根据推演进程和敌我兵力情况,再以多属性综合评价软优选算法为核心的决策模块对敌情属性、我情属性和环境属性进行综合运算,最后给出棋子的动作命令,并将命令传输到兵棋推演系统,驱动推演系统运行。兵棋数据按产生的方式可以分为环境数据、规则数据、历史数据和态势数据。环境数据、规则数据、历史数据为静态数据;态势数据为动态数据;环境数据是指兵棋推演系统对战场环境的量化表示而产生的数据;规则数据是指兵棋推演系统对作战实体、作战规则的描述而产生的数据;历史数据是指兵棋推演系统在多次推演过程中记录下来的推演数据的总和;态势数据是指在兵棋推演过程中产生的描述战场动态情况的数据,包括时间数据、敌方状态数据、我方状态数据和夺控点数据。图2描述了兵棋数据挖掘融合过程框架,分为5个步骤:(1)数据选择;(2)数据预处理;(3)数据转换;(4)数据挖掘;(5)数据融合。数据选择即根据用途选择需要处理的数据;数据预处理即滤除不完整的比赛数据;数据转换即将数据转换为处理的格式;数据挖掘即根据工程需要挖掘有价值信息,本发明挖掘的信息有:从实时兵棋推演系统的态势数据中挖掘实时敌情信息,从规则数据和环境数据中挖掘通视信息和夺控热度,对历史数据中每个阶段每个棋子的位置进行统计分析,提取历史位置和上下车位置信息。数据融合即将实时态势信息中的敌情数据融合到历史概率数据中,从而生成更能反映战场敌方情况的属性数据。最后,兵棋数据挖掘融合模块生成的数据归类为3类属性数据:(1)敌情属性。对可观察敌方棋子进行确定性分析,对不可观察敌方棋子通过比赛历史数据进行概率分析,综合之后形成实时敌方位置预测。综合通视情况后,计算出对敌观察度和被敌观察度这两个评价属性。(2)我情属性。通过对比赛数据中我方棋子位置进行概率分析,形成我方棋子预到达位置概率值,作为我方下步移动位置的一个评价属性。我方棋子上下车位置信息,用于我方棋子上下车位置的选择。(3)环境属性。针对下步可机动到的所有位置,按地形和当前位置与夺控点距离对我有利程度进行评价,形成夺控热度值,作为我方下步移动位置的一个评价属性。所述以多属性综合评价软优选算法为核心的决策模块,是根据分析挖掘模块输出的“敌情属性”、“我情属性”和“环境属性”三类属性信息和比赛的态势数据,综合运用多属性综合评价软优选算法和兵棋基本规则进行判断后,输出棋子行动命令,并将行动命令传输到兵棋推演系统。所述多属性综合评价软优选算法,是融合多属性综合评价算法和软优选算法后提出的适用于兵棋决策的一种算法。兵棋实体动作类型有步兵棋子上下车动作、机动、射击、夺控,这些动作中,机动动作最难决策,因为它与地图位置的选择密切相关,如坦克棋子一个机动阶段最多能机动六格,则机动终点的选择可能有96个,一个终点至少能生成一个机动方案。某个位置对作战实体的重要程度可以通过三种属性进行评价,敌情属性:棋子移动的终点被敌人观察到的可能性越小越好,我方越不容易被攻击;我情属性:统计以往的走子经验,我方停留次数越多的位置越好;环境属性:消耗体力少且越接近夺控点的位置越好。机动终点的选择是典型的多属性综合评价选择问题,可以用相关理论加以解决。多属性综合评价(multi-attributecomprehensiveevaluation,mce)根据评价对象和评价目的,从不同的侧面选取刻画系统某种特征的评价指标,建立指标体系,并通过一定的数学模型(或算法),实现系统性综合评价。加权平均法是使用最常用的将多个评价指标值合成一个整体性的综合评价值。针对兵棋实体机动终点的多属性综合评价,令其中,ui为第i个终点位置(或称第i个方案)的加权综合评价值,xij为第i个终点的第j个属性值,vj(xij)为xij的标准化评价值,ωj为第j个属性值的权系数。传统方案优选的标准是选择综合评价值最高的方案max(ui),但是这种优选方法不适宜军事问题选择。为了避免传统多属性综合评价优选算法在策略优选上固定的缺陷,本文引入机器学习学科中软概率的优选方法,提出多属性综合评价软优选算法,即将综合评价值转换为能够调控热度的概率值,并依据概率的大小来选择方案。将优选准则改为:k=random_choice(p)(3)其中,pi表示由评价值ui转换的概率值,τ>0,称为“温度因子”,具有调控概率的作用,p为由pi组成的离散概率分布数组,random_choice()为依概率选择坐标函数,k为最后优选出的方案序号。当τ→0时,不同方案的概率值差别大,最终选出的方案趋向于综合评价值最大的方案;当τ→+∞时,不同方案的概率值差距小,最终选出的方案趋向于随机选择;当1≤τ≤e时,可以较好兼顾质量与变化,τ越大,则变化性越强。可以看出,只要对兵棋上每个位置属性进行科学评价,利用多属性综合评价软优选算法,就能算出兵棋实体机动的终点位置,然后调用已有的路径生成算法(如限制距离后的泛洪法),就可以输出完整的机动命令。所述兵棋数据的挖掘融合模块,以历史数据和地图数据作为数据源,经数据挖掘融合后,生成多个数据表格,下面详细介绍各类表格的生成方法。每场比赛的历史数据为8张数据表格,记录比赛初始兵力状态和比赛过程中的态势数据。地图数据包含地图每个六角格的编号、高层、地貌等信息,本专利中“六角格”和“点”指代的对象相同。数据分析挖掘过程有以下数据表格产生:棋子历史位置概率表格s[c,n,l,i]、上车位置列表lup、下车位置列表ldown、夺控热度表(分为车辆主夺控热度表车辆次夺控热度表车辆主次夺控热度表士兵主夺控热度表士兵次夺控热度表士兵主次夺控热度表)、观察能力表(分为敌对我观察表ce2o[n,i,j]、我对敌观察表co2e[n,i,j])和实时敌情信息列表e。进数据融合后,形成以下3类数据:(1)敌情属性。融合棋子历史位置概率表格s[c,n,l,i]、实时敌情信息列表e和观察能力表后生成对敌观察度矩阵m和被敌观察度矩阵(2)我情属性。从棋子历史位置概率表格s[c,n,l,i]中抽取我方某个棋子在当前阶段的位置概率形成我方历史位置概率表直接引用数据分析挖掘过程中产生的上车位置列表lup、下车位置列表ldown;(3)环境属性。直接引用数据分析挖掘过程中产生的夺控热度表。棋子历史位置概率表格s[c,n,l,i]生成方法。原始历史数据信息比较零散,必须要经过筛选、整合、提取的过程。筛选就是考虑比赛完整性、比赛得分等因素,滤除不完整的比赛数据。整合就是将所有比赛数据的多张信息表整合为1张,主要记录数据类别有想定id、比赛id、棋子id、棋子名称、棋子颜色、棋子阶段初始位置、棋子阶段终止位置、阶段得分、阶段失分、比赛最终得分、死亡标志共11个要素。提取就是将整合后的数据进行统计分析,提取每个棋子在每个阶段终点位置的概率分布,最终形成表格s[c,n,l,i],c为棋子颜色索引,n为棋子名称索引,l为阶段索引,i为棋子位置索引,表格内容表示c颜色的n棋子在l阶段结束后停留在地图上i位置的概率为多少。上车位置列表lup和下车位置列表ldown生成方法。与棋子历史位置概率表格生成方法类似,经过筛选、整合、提取的过程。筛选就是考虑比赛完整性、比赛得分等因素,滤除不完整的比赛数据。整合就是将所有比赛数据的关于士兵上车和下车的信息整合为1张表格,主要记录数据类别有想定id、比赛id、棋子id、棋子颜色、棋子上车位置、棋子下车位置共6个要素。提取就是将整合后的数据中上车位置和下车位置进行次数统计,次数大于x次的位置编号分别存入上车位置列表lup和下车位置列表ldown内。上车位置列表lup记录士兵上车时的地图六角格编号,下车位置列表ldown记录士兵下车时的地图六角格编号。夺控热度表生成方法。夺控热度表根据某点与夺控点距离和地形因素综合形成的与地图表格等大的数据表,表征了地图上各点的位置重要程度。因地形对车辆(包含坦克和战车两类棋子)和士兵的体力消耗影响不同,在生成夺控热度表时区分车辆夺控热度表和士兵夺控热度表。一般地图上有两个夺控点:主要夺控点和次要夺控点。根据优先夺占哪个夺控点,可以计算出主夺控热度表、次夺控热度表和主次夺控热度表。主夺控热度表表示优先夺占主要夺控点,次夺控热度表表示优先夺占次夺控点,主次夺控热度表表示优先夺控主次夺控点中的任意一个。车辆主夺控热度表的生成方法。针对地图上的某点p(x,y),主夺控点为ofirst(xfirst,yfirst),则该点的车辆主控热度可表示为:其中τcommon为车辆通过一格普通地形需要消耗的体力值,τ(x,y)为车辆通过p(x,y)点消耗的体力值,l(p,ofirst)为p点到主要夺控点的格数量距离,为主要夺控点与边界最大格数量距离。求出地图上所有六角格的车辆主控热度即形成车辆主夺控热度表车辆次夺控热度表的生成方法。针对地图上的某点p(x,y),次夺控点为osecond(xsecond,ysecond),则该点的车辆次控热度可表示为:其中τcommon为车辆通过一格普通地形需要消耗的体力值,τ(x,y)为车辆通过p(x,y)点消耗的体力值,l(p,osecond)为p点到次要夺控点的格数量距离,为次要夺控点与边界最大格数量距离。求出地图上所有六角格的车辆次控热度即形成车辆次夺控热度表车辆次夺控热度表的生成方法。针对地图上的某点p(x,y),求出该点的主夺控热度和次夺控热度后,主次夺控热度可表示为:求出地图上所有六角格的车辆主次控热度即形成车辆主次夺控热度表士兵主夺控热度表的生成方法。士兵行进时对地形适应性较好,在求夺控热度时不考虑地形因素。针对地图上的某点p(x,y),主夺控点为ofirst(xfirst,yfirst),则该点的士兵主控热度可表示为:其中,l(p,ofirst)为p点到主要夺控点的格数量距离,为主要夺控点与边界最大格数量距离。求出地图上所有六角格的士兵主控热度即形成士兵主夺控热度表士兵次夺控热度表的生成方法。针对地图上的某点p(x,y),次夺控点为osecond(xsecond,ysecond),则该点的士兵次控热度可表示为:其中l(p,osecond)为p点到次要夺控点的格数量距离,为次要夺控点与边界最大格数量距离。求出地图上所有六角格的士兵次控热度即形成士兵次夺控热度表士兵次夺控热度表的生成方法。针对地图上的某点p(x,y),求出该点的主夺控热度和次夺控热度后,主次夺控热度可表示为:求出地图上所有六角格的士兵主次控热度即形成士兵主次夺控热度表观察能力表生成方法。观察能力表分为敌对我观察表ce2o[n,i,j]、我对敌观察表co2e[n,i,j])。若棋子位于隐蔽地形内,其观察距离不变,但被观察距离减半。当隐蔽地形内的棋子可以观察到敌方棋子时,存在敌方棋子观察不到位于隐蔽地形内的棋子的情况,因此需要分别考虑敌对我观察和我对敌观察。以我方棋子类型n和位置编号i为行索引,敌方棋子位置编号j为列索引,若满足敌对我观察条件,则表格中相应交叉点内容为1,否则为0。遍历所有地图六角格,计算出敌对我观察表ce2o[n,i,j]。以敌方棋子类型n和我方棋子的位置编号i为行索引,敌方棋子位置编号j为列索引,若满足我对敌观察条件,则表格相应交叉点内容为1,否则为0。遍历所有地图六角格,计算出我对敌观察表co2e[n,i,j]。实时敌情信息列表e生成方法。兵棋推演系统在推演过程中,能够实时输出反应战场情况的态势数据。态势信息中包含能被我方观察到的敌方棋子信息,不可观察棋子信息在态势数据中不显示。将敌方棋子类型和位置信息提取出来,形成实时敌情信息列表e。敌情属性数据生成方法。包含对敌观察度矩阵m和被敌观察度矩阵首先调用敌情和敌方位置更新模块函数将棋子历史位置概率表格s[c,n,l,i]中敌方棋子信息和实时敌情信息列表e进行融合,生成实时敌方位置概率表车辆在点p(x,y)的对敌观察度和被敌观察度可以表示为:其中i为p点的六角格编号,为l阶段c颜色6个棋子经实时态势数据融合后形成的实时敌方位置概率矩阵,为我方在i位置对敌车辆观察矩阵,为我方在i位置对敌士兵观察矩阵,为敌方对我方车辆的观察矩阵,t为矩阵转置。对地图上我方一个机动阶段内所有可到达的六角格求对敌观察度,不可到达的六角格对敌观察度设为0,形成与地图大小等大的矩阵为对敌观察度矩阵m。对地图上我方一个机动阶段内所有可到达的六角格求被敌观察度,不可到达的六角格对敌观察度设为1,最后形成的矩阵为被敌观察度矩阵我情属性数据生成方法。包含我方历史位置概率表上车位置列表lup和下车位置列表ldown。我方历史位置概率表按棋子颜色c、棋子名称n和推演阶段l直接从棋子历史位置概率表格s[c,n,l,i]中抽取,上车位置列表lup和下车位置列表ldown已经在数据分析挖掘阶段生成。环境属性数据生成。包含夺控热度表(分为车辆主夺控热度表车辆次夺控热度表车辆主次夺控热度表士兵主夺控热度表士兵次夺控热度表士兵主次夺控热度表),已经在数据分析挖掘阶段生成。所述兵棋智能引擎的运行框架,是以技术框架为指导,结合具体推演系统的态势数据和兵棋规则,编程设计的以态势数据为输入,多个动作命令为输出的软件模块,包括敌情处理模块、多个动作模块和运行流程框架。所述敌情处理模块,对兵棋推演系统输入的态势信息做分析处理,主要完成2个功能:(1)敌我力量更新:主要是根据态势信息,统计更新敌方活着的棋子类型和数量,敌方死亡的棋子和数量,敌方可见棋子的类型和数量,敌方不可见的棋子和数量,我方活着的棋子和数量,我方死亡的棋子和数量,敌我双方兵力对比等信息,作为程序决策依据;(2)敌方位置更新:将棋子历史位置概率表格s[c,n,l,i]中敌方棋子信息和实时敌情信息列表e进行融合,即将我方可观察位置的敌方位置概率设为0,可观察到的敌方位置概率设为1,而后进行规范化处理,形成敌方位置概率矩阵所述多个动作模块,是将兵棋推演系统中每个棋子能够执行的动作进行分解,每个动作的决策执行作为一个子程序,供主程序调用。每个动作的决策依据主要是根据兵棋推演系统的基本规则进行判断,或是依据多属性综合评价软优选算法给出具体目标位置。共有射击动作、夺控动作、上车动作、下车动作、士兵移动、战车移动、坦克移动共7类动作。射击、夺控动作的产生规则。射击和夺控动作产生的规则相对简单,根据兵棋推演规则,当棋子满足射击或夺控条件后,就执行这个动作。上车下车动作的产生规则。上车和下车动作的难点在于选择上下车的位置。上车的规则是在满足上车条件后,人和战车的位置位于上车列表lup内,则执行上车动作。下车动作的规则是在满足下车条件后,载人战车的位置位于下车列表ldown内,或者载人战车距离夺控点小于等于一定数值(本发明设为3),则执行下车动作。士兵移动算法。士兵移动,综合评价我情属性中的我方历史位置概率和环境属性中夺控热度共2个因素,生成棋子移动路径。因士兵目标较小,不易被敌方攻击,且需要士兵到前沿探查敌情,所以不考虑敌情属性。依据多属性综合评价软优选算法,考虑地图上所有点,士兵移动综合评价矩阵可表示为:其中,f为士兵可机动范围矩阵(可到达为1,不可到达为0),为士兵历史位置概率矩阵(从历史位置概率表s[c,n,l,i]中抽取),为士兵主次夺控热度矩阵,·为矩阵点乘,是加权因子,根据情况人为设定。而后进行软概率优选:(x,y)=random_choice(p)(14)其中,sum()为矩阵所有元素求和,p为与地图范围等大的离散概率分布,random_chioce()为依概率选择序号函数,(x,y)为最后优选出的移动终点。最后,调用路径生成函数(根据已有的限制距离后的泛洪法(广度优先搜索)编写的子程序),生成棋子移动路径。战车移动算法。战车移动,参考敌情属性中被敌观察度矩阵我情属性中的我方历史位置概率和环境属性中夺控热度共3个因素,生成棋子移动路径。依据多属性综合评价软优选算法,考虑地图上所有点的评价,战车移动综合评价矩阵可表示为:其中,f为战车可机动范围矩阵,为车辆主次夺控热度矩阵,为战车历史位置概率矩阵(从历史位置概率表s[c,n,l,i]中抽取),为被敌观察度矩阵,·为矩阵点乘,是加权因子,根据情况人为设定。而后软概率优选:(x,y)=random_choice(p)(17)其中,sum()为矩阵所有元素求和,p为与地图范围等大的离散概率分布,random_chioce()为依概率选择序号函数,(x,y)为最后优选出的移动终点。最后,调用路径生成函数(根据已有的限制距离后的泛洪法(广度优先搜索)编写的子程序),生成棋子移动路径。坦克移动算法。坦克在机动的过程中可以进行机动射击,控制过程相对复杂,需分别计算观察射击点和终点,在观察射击点的选择上还要区分有目标移动射击和无目标移动射击。当态势信息中没有敌情信息时,坦克执行无目标移动射击,策略分为以下步骤:步骤一:按多因素综合评价软优选算法,考虑夺控热度、我方历史位置概率和被敌观察度3个因素,参照战车路径生成过程,计算坦克移动终点步骤二:计算坦克从起始点到终点中间所有可能经过的点。按对敌观察度计算方法,计算这些点的对敌观察度(不能经过的点其对敌观察度为0),形成观察度矩阵m,只考虑这一个因素,按多因素综合软优选算法,求取观察射击点步骤三:调用路径生成函数,生成坦克从起始点到观察射击点的路径,并执行机动动作;步骤四:更新态势信息,发现敌人棋子则调用射击函数进行射击,否则执行步骤五;步骤五:调用路径生成函数,生成坦克从观察射击点到终点的路径,并执行机动动作。当态势信息中有敌情时,坦克执行有目标移动射击,策略分为以下步骤:步骤一:按威胁程度对敌人棋子进行排序,形成敌情列表;步骤二:选择射击目标。按顺序选择敌情列表中一个棋子作为目标,计算坦克可移动范围内是否存在可射击点,如不存在,则从敌情列表中选择下一个棋子作为目标,并判断是否存在可射击点。如此循环直到找到可以射击的目标,执行步骤三,若敌情列表目标都不可射击,则停止执行有目标射击,开始执行无目标观察射击。步骤三:计算观察射击点。对选择的射击目标,计算距离坦克和目标距离之和最小的点集合,从中选择离坦克距离最近的点作为观察射击点。步骤四:调用路径生成函数,生成到观察射击点的路径,执行机动动作。到达观察射击点后,更新态势信息后,执行射击动作。步骤五:按多因素综合评价软优选算法,考虑夺控热度、我方历史位置概率和被敌观察度3个因素,参照战车路径生成过程,计算坦克移动终点调用路径生成函数,生成到终点的路径,执行机动动作。坦克移动算法将以上无目标移动射击过程和有目标移动射击过程进行综合,形成整体判断决策和输出控制命令的子模块。所述运行流程框架是整个兵棋智能引擎的主程序流程,涵盖兵棋智能引擎从启动兵棋推演到结束推演的整个过程。包含以下步骤:步骤一:初始化对战环境。与兵棋推演系统进行通信,明确推演开始,并初始化智能兵棋引擎中的变量;步骤二:更新态势、修正敌情。读取兵棋推演系统推送的态势信息,更新引擎中推演阶段变量、我方棋子列表、敌方棋子列表、夺控点状态信息等用于条件判断的变量。调用敌情处理模块对态势数据进行分析,完成敌我力量更新和敌方实时位置概率更新,生成敌方位置概率矩阵并保存到数据库中;步骤三:判断推演是否结束。判断的依据是推演已经到结束阶段或者我方棋子全部死亡或者敌方已经结束比赛,如果结束,则跳转到步骤十八销毁对战环境;如果没有结束,则跳转到下一步骤;步骤四:判断是否能够夺控。根据推演规则,依次查询每个棋子,判断我方棋子是否到达夺控点并且能否执行夺控动作(调用夺控动作模块),如果可以夺控,则跳转到步骤五执行夺控动作;如果不满足夺控条件,则跳转到步骤六;步骤五:执行夺控。向兵棋推演系统发送夺控动作的命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤六:判断是否上车。依次查询每个士兵棋子,判断我方士兵是否满足进入战车的条件(调用上车动作模块),如果可以上车,则跳转步骤七,否则,跳转到步骤八;步骤七:执行上车。向兵棋推演系统发送士兵上车的命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤八:判断是否下车。依次查询每个士兵棋子,判断我方士兵是否满足下车的条件(调用下车动作模块),如果可以下车,则跳转到步骤九,否则,跳转到步骤十;步骤九:执行下车。向兵棋推演系统发送士兵下车的命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤十:判断是否射击。依次查询每个棋子,判断棋子是否满足射击条件(调用射击动作模块),如果可以射击,则跳转到步骤十一,否则跳转到步骤十二;步骤十一:执行射击。向兵棋推演系统发送棋子射击命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤十二:判断士兵是否能机动。依次查询士兵是否可以机动,如果可以机动,则跳转到步骤十三,否则跳转到步骤十四;步骤十三:士兵移动。调用士兵移动模块,生成士兵移动路径命令后传送到兵棋推演系统,推演系统反馈执行命令成功后,跳转到步骤二;步骤十四:判断战车能否机动。依次查询战车是否可以机动,如果可以机动,则跳转到步骤十五,否则跳转到步骤十六;步骤十五:战车机动。调用战车移动模块,生成战车移动路径命令后传送到兵棋推演系统,推演系统反馈执行命令成功后,跳转到步骤二;步骤十六:判断坦克能否机动。依次查询坦克是否可以机动,如果可以机动,则跳转到步骤十七,否则跳转到步骤二;步骤十七:坦克移动。调用坦克移动模块,完成坦克无目标射击或是坦克有目标射击,并将机动或射击命令传送到兵棋推演系统,坦克移动模块执行完毕后跳转到步骤二;步骤十八:销毁对战环境。与兵棋推演系统通信明确推演结束,并释放引擎占用的内存资源。兵棋智能引擎基于python语言实现,除敌方位置概率矩阵在态势信息处理阶段生成外,其它数据表都在数据预处理阶段提前生成。主程序流程可简单描述为:首先初始化对战环境,然后更新态势信息并更新敌情,而后判断推演是否结束,未结束则进入主要动作判断环节;依次查询我方所有棋子是否可以执行夺控、射击、上车、下车、机动等动作,可以执行,则调用相应算法模块,生成棋子动作,最后程序返回态势更新模块,执行下一个循环。不同动作之间有优先级的区别,夺控动作优先级最高,在一个循环中首先查询,坦克移动优先级最低,在一个循环中最后查询。有益效果:与现有技术相比,本发明提供的陆战兵棋智能引擎及其运行方法,具有如下优点:1)通过挖掘比赛历史数据和地图数据,挖掘出的知识能够生成为数据表格,兵棋智能引擎在运行时能够矩阵运算,运算速度快,实时性强;2)全程不设任何固定走子点,只对特定地图和想定的推演数据进行数据挖掘,整个方法适用于不同的兵棋系统,或是同一兵棋系统的不同地图和想定,可移植性好;3)基于多属性综合评价软优选决策算法给出棋子移动位置,人为设定适当的探索因子后,棋子移动位置兼顾质量与变化,突破了一般智能引擎走子固定的缺点。附图说明图1为本发明的兵棋实体作战行动智能决策模型框架图;图2为本发明的兵棋数据挖掘融合过程框架图;图3为本发明实施例的兵棋智能引擎运行场景图;图4为本发明实施例的坦克移动射击动作流程图;图5为本发明实施例的兵棋智能引擎主程序流程图。具体实施方式下面结合具体实施例,进一步阐明本发明,但本发明的保护范围并不仅限于此:实施例:以“2017首届全国兵棋推演大赛”使用的“铁架突击群兵棋推演系统”为兵棋推演平台(不包含在本发明内)、以“2017首届全国兵棋推演大赛”比赛过程中收集的推演数据为数据源(不包含在本发明内),使用地图为“城镇居民地”,使用python编程语言进行编程,介绍本兵棋智能引擎的一个应用实例。系统运行场景。本发明不能单独运行,需针对特定兵棋推演系统进行设计,再组合起来一起运行,实现智能推演功能。图3为本发明实施例的兵棋智能引擎运行场景图。包含远程兵棋推演系统、接口平台和兵棋智能引擎三个部分,三者结合使用才能完成整个兵棋智能推演。远程兵棋推演系统和接口平台为兵棋智能引擎运行的支撑环境,是其它公司或研究所设计的软件系统,不受本发明专利保护。远程兵棋推演系统是传统的人工兵棋推演平台,运行在服务器端,通过浏览器访问观看。接口平台是为智能引擎设计的接口软件,起到与远程兵棋推演系统通信和数据传输的作用,它在兵棋推演系统和智能引擎之间架起了一座桥梁。兵棋智能引擎起到“大脑”的作用,通过接口平台读取兵棋态势数据,经过智能兵棋引擎计算后,输出棋子动作,经接口平台传输到兵棋推演系统,从而驱动整个系统有效运行。智能兵棋设计以兵棋实体作战行动智能决策模型框架为指导,如图1所示。静态数据挖掘对兵棋数据中的规则数据、环境数据和历史数据进行挖掘,提取与决策相关的静态的知识数据。动态数据融合对知识数据和推演系统的实时态势进行数据融合,形成决策相关的属性数据。多agent行动序列决策综合兵棋基本规则、态势数据和属性数据,完成兵棋作战实体的行动命令生成。行动命令发送到战术级兵棋推演系统后被执行,推演系统会将新的态势数据传递出来。如此循环,实现兵棋推演系统的智能决策。在具体设计过程中按以下3个部分逐步实施:(1)静态数据挖掘,生成静态数据表格。实现了图1中的静态数据挖掘功能;(2)编写功能处理子模块,包括敌情处理模块、夺控动作模块、射击动作模块、上车动作模块、下车动作模块、士兵移动模块、战车移动模块、坦克移动模块。实现了图1中的动态数据融合和兵棋agent行动决策部分的基于规则的合法行动判断及基于多属性综合评价软优选的机动方案决策2个子功能;(3)编写主程序模块,引用功能处理子模块,实现系统功能。实现了图1中兵棋agent行动决策部分的决策流程控制及行动排序子功能。(1)静态数据挖掘,生成静态数据表格,供功能处理子模块调用。针对多属性综合评价软优选算法需要用到的数据,利用数据挖掘技术对收集的推演数据进行挖掘,有以下数据表格产生:棋子历史位置概率表格s[c,n,l,i]、上车位置列表lup、下车位置列表ldown、夺控热度表(分为车辆主夺控热度表车辆次夺控热度表车辆主次夺控热度表士兵主夺控热度表士兵次夺控热度表士兵主次夺控热度表)、观察能力表(分为敌对我观察表ce2o[n,i,j]、我对敌观察表co2e[n,i,j])。其处理的基本过程按图2中前4个步骤:(1)数据选择;(2)数据预处理;(3)数据转换;(4)数据挖掘。第5个数据融合步骤是兵棋推演过程中不断进行的动态数据处理过程,在编写功能处理子模块中实现。生成棋子历史位置概率表格s[c,n,l,i]。按筛选、整合、提取的过程对原始历史比赛数据进行处理。筛选就是考虑比赛完整性、比赛得分等因素,选出质量高的比赛数据。整合就是将所有比赛数据的多张信息表整合为1张,主要记录数据类别有想定id、比赛id、棋子id、棋子颜色、棋子阶段初始位置、棋子阶段终止位置、比赛最终得分等共11个要素。提取就是将整合后的数据进行统计分析,提取每个棋子在每个阶段终点位置的概率分布,最终形成表格s[c,n,l,i],c为棋子颜色索引,n为棋子名称索引,l为阶段索引,i为棋子位置索引,表格内容表示c颜色的n棋子在l阶段结束后停留在地图上i位置的概率为多少。表1展示了表格s[c,n,l,i]局部情况,第1列为棋子颜色索引,第2列为棋子名称索引,第3列为阶段索引,第一行的数字为棋子位置索引。表1colournamestage…500325003450036…0101…00.043100…1102…000…0103…0.017240.008620.02586…生成上车位置列表lup和下车位置列表ldown。与棋子历史位置概率表格生成方法类似,经过筛选、整合、提取的过程。筛选就是考虑比赛完整性、比赛得分等因素,选出质量高的比赛数据。整合就是将所有比赛数据的关于士兵上车和下车的信息整合为1张表格,主要记录数据类别有想定id、比赛id、棋子id、棋子颜色、棋子上车位置、棋子下车位置共6个要素。提取就是将整合后的数据中上车位置和下车位置进行次数统计,次数大于3次的位置编号分别存入上车位置列表lup和下车位置列表ldown内。生成车辆主夺控热度表针对地图上的某点p(x,y),主夺控点为ofirst(xfirst,yfirst),则该点的车辆主控热度可表示为:其中τcommon为车辆通过一格普通地形需要消耗的体力值,τ(x,y)为车辆通过p(x,y)点消耗的体力值,l(p,ofirst)为p点到主要夺控点的格数量距离,为主要夺控点与边界最大格数量距离。求出地图上所有六角格的车辆主控热度即形成车辆主夺控热度表表2显示了局部的车辆主夺控热度表主夺控点为1,远离夺控点后热度开始变小,如0.95、0.9的点,存在村庄地形(消耗车辆的体力值大),如热度为0.5的点。表2…………………0.950.950.950.9……0.9510.50.9……0.50.950.90.9…………………生成车辆次夺控热度表针对地图上的某点(或六角格)p(x,y),次夺控点为osecond(xsecond,ysecond),则该点的车辆次控热度可表示为:其中τcommon为车辆通过一格普通地形需要消耗的体力值,τ(x,y)为车辆通过p(x,y)点消耗的体力值,l(p,osecond)为p点到次要夺控点的格数量距离,为次要夺控点与边界最大格数量距离。求出地图上所有六角格的车辆次控热度即形成车辆次夺控热度表生成车辆次夺控热度表针对地图上的某点(或六角格)p(x,y),求出该点的主夺控热度和次夺控热度后,主次夺控热度可表示为:求出地图上所有六角格的车辆主次控热度即形成车辆主次夺控热度表生成士兵主夺控热度表士兵行进时对地形适应性较好,在求夺控热度时不考虑地形因素。针对地图上的某点(或六角格)p(x,y),主夺控点为ofirst(xfirst,yfirst),则该点的士兵主控热度可表示为:其中,l(p,ofirst)为p点到主要夺控点的格数量距离,为主要夺控点与边界最大格数量距离。求出地图上所有六角格的士兵主控热度即形成士兵主夺控热度表生成士兵次夺控热度表针对地图上的某点(或六角格)p(x,y),次夺控点为osecond(xsecond,ysecond),则该点的士兵次控热度可表示为:其中l(p,osecond)为p点到次要夺控点的格数量距离,为次要夺控点与边界最大格数量距离。求出地图上所有六角格的士兵次控热度即形成士兵次夺控热度表生成士兵次夺控热度表针对地图上的某点(或六角格)p(x,y),求出该点的主夺控热度和次夺控热度后,主次夺控热度可表示为:求出地图上所有六角格的士兵主次控热度即形成士兵主次夺控热度表生成敌对我观察表ce2o[n,i,j]和我对敌观察表co2e[n,i,j])。以我方棋子类型n和位置编号i为行索引,敌方棋子位置编号i为列索引,若满足敌对我观察条件,则表格中相应交叉点内容为1,否则为0。遍历所有地图六角格,计算出敌对我观察表ce2o[n,i,j]。表3为敌对我观察表的局部,第一列为棋子类型,1代表车辆,敌人棋子(车辆或者士兵)在编号10025六角格内不能观察到我方车辆,敌人棋子在编号10037六角格可以观察到我方车辆。表3bop_typegrid_pos10025100271002910031100331003510037140022000000114002400000111400260011111以敌方棋子类型n和我方棋子的位置编号i为行索引,敌方棋子位置编号j为列索引,若满足我对敌观察条件,则表格相应交叉点内容为1,否则为0。遍历所有地图六角格,计算出我对敌观察表co2e[n,i,j]。(2)编写功能处理子模块,包括敌情处理模块、夺控动作模块、射击动作模块、上车动作模块、下车动作模块、士兵移动模块、战车移动模块、坦克移动模块。技术方案中所提技术框架:数据挖掘融合模块中的数据融合步骤和多属性综合评价软优选算法为技术原理,相应方法将在各功能处理子模块中应用。敌情处理模块。对兵棋推演系统输入的态势信息做分析处理,主要完成2个功能:(1)敌我力量更新:主要是根据态势信息,统计更新敌方活着的棋子类型和数量,敌方死亡的棋子和数量,敌方可见棋子的类型和数量,敌方不可见的棋子和数量,我方活着的棋子和数量,我方死亡的棋子和数量,敌我双方兵力对比等信息,作为程序决策依据;(2)敌方位置更新:使用数据融合的技术,将棋子历史位置概率表格s[c,n,l,i]中敌方棋子信息和实时敌情信息列表e进行融合,即将我方可观察且无敌方棋子的敌方位置概率设为0,可观察到的敌方位置概率设为1,而后进行规范化处理(将地图上所有点的位置概率等比例变换,使位置概率总和等于1),形成敌方位置概率矩阵夺控动作模块。完成2个功能:(1)依次查询我方棋子,依据兵棋基本规则进行判断,看是否满足夺控条件;(2)若存在满足夺控条件的我方棋子,生成并发送夺控的命令。射击动作模块。完成2个功能:(1)依次查询我方棋子,依据兵棋基本规则和态势数据中敌情信息进行判断,看是否满足射击条件;(2)若满足射击条件,生成并发送射击的命令。上车动作模块。完成2个功能:(1)查询我方是否存在可以上车的士兵棋子。上车的条件是棋子在满足上车基本规则后,人和战车的位置位于上车列表lup内;(2)存在可以上车的士兵棋子时,生成并发送上车命令。下车动作模块。完成2个功能:(1)查询我方是否存在可以下车的士兵棋子。下车动作的条件是在满足下车基本规则后,载人战车的位置位于下车列表ldown内,或者载人战车距离夺控点小于等于3;(2)存在可以下车的士兵棋子时,生成并发送下车命令。士兵移动模块。根据兵棋基本规则查询我方士兵棋子是否满足机动条件,满足机动条件后,生成棋子移动路径并发送该命令。士兵移动终点按多属性综合评价软优选算法生成。综合评价我情属性中的我方历史位置概率和环境属性中士兵主次夺控热度表共2个因素。依据多属性综合评价软优选算法,考虑地图上所有点,士兵移动综合评价矩阵可表示为:其中,f为士兵可机动范围矩阵,为士兵历史位置概率矩阵(从历史位置概率表s[c,n,l,i]中按c,n,l三个索引抽取),为士兵主次夺控热度矩阵,·为矩阵点乘,是加权因子,根据情况人为设定。而后软概率优选:(x,y)=random_choice(p)(14)其中,sum()为矩阵所有元素求和,p为与地图范围等大的离散概率分布,random_chioce()为依概率选择序号函数,(x,y)为最后优选出的移动终点。最后,调用路径生成函数(根据已有的限制距离后的泛洪法(广度优先搜索)编写的子程序),生成棋子移动路径。战车移动模块。根据兵棋基本规则查询我方战车棋子是否满足机动条件,满足机动条件后,生成战车移动路径并发送该命令。按多属性综合评价软优选算法生成战车移动终点,考虑的属性为敌情属性中被敌观察度矩阵我情属性中的我方历史位置概率和环境属性中车辆主次夺控热度表共3个因素。生成被敌观察度矩阵车辆在点p(x,y)的对敌观察度和被敌观察度可以表示为:其中i为p点的六角格编号,敌情更新模块中生成实时敌方位置概率表,c、n和l分别为颜色、棋子名称、推演阶段索引,为我方在i位置对敌车辆观察矩阵,为我方在i位置对敌士兵观察矩阵,为敌方对我方车辆的观察矩阵,t为矩阵转置。对地图上我方一个机动阶段内所有可到达的六角格求被敌观察度,不可到达的六角格对敌观察度设为1,最后形成的矩阵为被敌观察度矩阵依据多属性综合评价软优选算法,考虑地图上所有点的评价,战车移动综合评价矩阵可表示为:其中,f为战车可机动范围矩阵,为车辆主次夺控热度矩阵,为战车历史位置概率矩阵(从历史位置概率表s[c,n,l,i]中抽取),为被敌观察度矩阵,·为矩阵点乘,是加权因子,根据情况人为设定。而后软概率优选:(x,y)=random_choice(p)(17)其中,sum()为矩阵所有元素求和,p为与地图范围等大的离散概率分布,random_chioce()为依概率选择序号函数,(x,y)为最后优选出的移动终点。最后,调用路径生成函数(根据已有的限制距离后的泛洪法(广度优先搜索)编写的子程序),生成棋子移动路径。坦克移动模块。坦克具有机动中射击的能力,坦克移动模块生成的命令含机动命令和射击命令,此模块分不同情况有多个命令输出,具体步骤可参考图4实施例的坦克移动射击动作流程图。其中坦克移动终点、观察射击点的计算方法和战车移动终点算法一样,这里不详细介绍。坦克移动射击根据态势信息中有无可以观察到的敌情信息分为两种情况:坦克无目标移动射击和有目标移动射击。当态势信息中没有敌情信息时,坦克执行无目标移动射击,策略分为以下步骤:步骤一:按多因素综合评价软优选算法,考虑夺控热度我方历史位置概率和被敌观察度共3个因素,参照战车路径生成过程,计算坦克移动终点步骤二:搜索坦克从起始点到终点中间所有可能经过的点。按对敌观察度计算方法,计算这些点的对敌观察度,不能经过的点对敌观察度为0,形成与地图等大的观察度矩阵m,只考虑这一个因素,按多因素综合评价软优选算法,求取观察射击点步骤三:调用路径生成函数,生成坦克从起始点到观察射击点的路径,向兵棋推演系统发送机动命令;步骤四:兵棋推演系统反馈坦克到达观察射击点后,更新态势信息,如果态势信息中出现可射击的敌人棋子,则调用射击函数进行射击,否则执行步骤五;步骤五:调用路径生成函数,生成坦克从观察射击点到终点的路径,并执行机动动作。当态势信息中有敌情时,坦克执行有目标移动射击,策略分为以下步骤:步骤一:按专家经验评定的威胁程度对敌人棋子进行排序,形成敌情列表;步骤二:选择射击目标。按顺序选择敌情列表中一个棋子作为目标,计算坦克可移动范围内是否存在可射击点,如不存在,则从敌情列表中选择下一个棋子作为目标,并判断是否存在可射击点。如此循环直到找到可以射击的目标,执行步骤三,若敌情列表目标都不可射击,则停止执行有目标射击,开始执行无目标观察射击。步骤三:计算观察射击点。对选择的射击目标,计算距离坦克和目标距离之和最小的点集合,从中选择离坦克距离最近的点作为观察射击点步骤四:调用路径生成函数,生成到观察射击点的路径,执行机动动作。到达观察射击点后,向兵棋推演系统发送射击命令。步骤五:按多因素综合评价软优选算法,考虑夺控热度我方历史位置概率和被敌观察度共3个因素,参照战车移动终点生成过程,计算坦克移动终点调用路径生成函数,生成到终点的路径,向兵棋推演系统发送机动命令。坦克移动是综合有目标坦克移动射击和无目标坦克移动射击之后形成的一个完整功能模块,整个坦克移动流程参考图4实施例的坦克移动射击动作流程图。(3)编写主程序模块,引用功能处理子模块,实现系统功能。主程序模块是本兵棋智能引擎的主程序,它通过调用各功能处理子模块,控制整体运行流程,实现兵棋智能推演的功能。包含以下步骤:步骤一:初始化对战环境。与兵棋推演系统进行通信,明确推演开始,并初始化智能兵棋引擎中的变量;步骤二:更新态势、修正敌情。读取兵棋推演系统推送的态势信息,更新引擎中推演阶段变量、我方棋子列表、敌方棋子列表、夺控点状态信息等用于条件判断的变量。调用敌情处理模块对态势数据进行分析,完成敌我力量更新和敌方实时位置概率更新,生成敌方位置概率矩阵并保存到数据库中(数据库中上车位置表、下车位置表、棋子历史位置概率表、士兵夺控热度表、车辆夺控热度表、敌对我观察表、我对敌观察表已经在数据挖掘阶段提前生成,为静态数据);步骤三:判断游戏是否结束。判断的依据是推演已经到结束阶段或者我方棋子全部死亡或者敌方已经结束比赛,如果结束,则跳转到步骤十八销毁对战环境;如果没有结束,则跳转到下一步骤;步骤四:判断是否能够夺控。根据推演规则,依次查询每个棋子,判断我方棋子是否到达夺控点并且能否执行夺控动作(调用夺控动作模块),如果可以夺控,则跳转到步骤五执行夺控动作;如果不满足夺控条件,则跳转到步骤六;步骤五:执行夺控。向兵棋推演系统发送夺控动作的命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤六:判断是否上车。依次查询每个士兵棋子,判断我方士兵是否满足进入战车的条件(调用上车动作模块),如果可以上车,则跳转步骤七,否则,跳转到步骤八;步骤七:执行上车。向兵棋推演系统发送士兵上车的命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤八:判断是否下车。依次查询每个士兵棋子,判断我方士兵是否满足下车的条件(调用下车动作模块),如果可以下车,则跳转到步骤九,否则,跳转到步骤十;步骤九:执行下车。向兵棋推演系统发送士兵下车的命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤十:判断是否射击。依次查询每个棋子,判断棋子是否满足射击条件(调用射击动作模块),如果可以射击,则跳转到步骤十一,否则跳转到步骤十二;步骤十一:执行射击。向兵棋推演系统发送棋子射击命令。兵棋推演系统反馈命令执行成功后,跳转到步骤二;步骤十二:判断士兵是否能机动。依次查询士兵是否可以机动,如果可以机动,则跳转到步骤十三,否则跳转到步骤十四;步骤十三:士兵移动。调用士兵移动模块,生成士兵移动路径命令后传送到兵棋推演系统,推演系统反馈执行命令成功后,跳转到步骤二;步骤十四:判断战车能否机动。依次查询战车是否可以机动,如果可以机动,则跳转到步骤十五,否则跳转到步骤十六;步骤十五:战车机动。调用战车移动模块,生成战车移动路径命令后传送到兵棋推演系统,推演系统反馈执行命令成功后,跳转到步骤二;步骤十六:判断坦克能否机动。依次查询坦克是否可以机动,如果可以机动,则跳转到步骤十七,否则跳转到步骤二;步骤十七:坦克移动。调用坦克移动模块,完成坦克无目标移动射击或是坦克有目标移动射击,并将机动或射击命令传送到兵棋推演系统,坦克移动模块执行完毕后跳转到步骤二;步骤十八:销毁对战环境。与兵棋推演系统通信明确推演结束,并释放引擎占用的内存资源。图5展示了本发明实施例的兵棋智能引擎主程序流程图,虚线方框内为各功能子模块。简要的运行流程可描述为:首先初始化对战环境,然后更新态势信息并更新敌情,而后判断游戏是否结束,未结束则进入主要动作判断环节。依次调用各功能子模块,查询我方所有棋子是否可以执行夺控、射击、上车、下车、机动等动作,可以执行,则生成棋子动作并向兵棋推演系统发送执行命令,最后程序返回态势更新模块,执行下一个循环。不同动作之间有优先级的区别,夺控动作优先级最高,在循环中首先查询,坦克移动优先级最低,在循环中最后查询。本发明支持多幅地图,参数可以根据人为设定灵活调节。本实例使用地图为“城镇居民地”,概率热度τ=1,这样既保证了生成策略的质量,同时又兼顾了策略的多样性。另外,在3类夺控热度表的选择上,选择主次夺控热度表。主要参数的设定如表4所示。表4当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1