用户智能设备及其情绪图符处理方法与流程
本申请涉及信息处理技术领域,具体涉及一种情绪图符处理方法,以及应用所述情绪图符处理方法的用户智能设备。
背景技术:
随着个人移动终端技术的高速发展,个人的移动沟通功能也越来越完善,相应地,沟通时所需要使用到的图文并茂的表情图符(图片或各种字符串的组合)也逐渐走向个性化。
比如,当用户在即时通信软件或社交平台等输入消息时,如果想要插入表情符,会从已有的表情符中选取某个希望插入的表情符,或者输入与预设表情符相对应的文字,然后在表情符推荐结果中选择某个。其中,“已有的表情符”一般来自于应用软件中预设或网络下载,且“表情符”一般仅指emoji和静止或动态的图形。当然,用户也可以通过拍摄图像或视频,并添加文字,以生成静止或动态的表情图。
但是,用户仅能使用已设计好的表情符,且仅能够通过手动点击选取或文字输入获得对应的表情符推荐结果,但用户输入的消息多种多样,不仅有文字还有语音、图片、视频等,因此这种方案不能满足其他的信息输入场景。而且,有时候输入的文字也仅能通过与已有表情符的名字相比较,从而获得输入文字相关的表情符推荐结果,当输入文字具有情绪含义但是不完全等于已有表情符的名字时,无法获得表情符推荐结果。比如,输入“我好开心呀”,无法获得“开心”相关的表情符推荐,必须输入“开心”才能获得,并不符合用户的真实使用习惯。进一步来说,已设计好的表情符,不够个性化,无法满足当下用户的个性化需求。
同样,用户通过拍摄图像或视频来生成静止或动态的表情符,还需通过添加文字等编辑来表明情绪状态,虽然满足了个性化需求,但是不够智能轻便,增加用户负担,用户体验较差。
针对现有技术的多方面不足,本申请的发明人经过深入研究,提出一种用户智能设备及其情绪图符处理方法。
技术实现要素:
本申请的目的在于,提供一种用户智能设备及其情绪图符处理方法,能够根据用户输入信息进行情绪识别,将情绪图片、文字或语言等生成对应的情绪图符,实现了多种输入途径的快捷输入效果,还可以实现对较长输入信息的情绪识别,满足了个性化需求,而且在一定程度上实现了人工智能。
为解决上述技术问题,本申请提供一种情绪图符处理方法,作为其中一种实施方式,所述情绪图符处理方法包括步骤:
用户智能设备获取用户的输入信息;
根据所述输入信息对用户进行情绪识别;
根据情绪识别的结果得到对应的关键信息;
根据所述关键信息生成得到对应的情绪图符。
作为其中一种实施方式,所述用户智能设备获取用户的输入信息的步骤,具体包括:
用户智能设备通过摄像装置拍摄用户的肢体语言内容;
对所述肢体语言内容进行预处理以作为所述输入信息。
作为其中一种实施方式,所述对所述肢体语言内容进行预处理以作为所述输入信息的步骤,具体包括:
对所述肢体语言内容进行动作识别;
根据动作识别的结果获取动作幅度变化值大于预设阈值的目标部位;
将所述目标部位的动作作为所述输入信息。
作为其中一种实施方式,所述肢体语言内容为眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合的动作。
作为其中一种实施方式,所述用户智能设备获取用户的输入信息的步骤,具体包括:
用户智能设备通过麦克风获取用户的语音内容;
对所述语言内容进行预处理以作为所述输入信息。
作为其中一种实施方式,所述根据所述输入信息对用户进行情绪识别的步骤,具体包括:
采用基于语音情感分析技术对所述语音内容的数据进行情绪识别。
作为其中一种实施方式,所述用户智能设备获取用户的输入信息的步骤,具体包括:
用户智能设备通过文本消息输入框获取用户的文本文字;
对所述文本文字进行预处理以作为所述输入信息。
作为其中一种实施方式,所述根据所述输入信息对用户进行情绪识别的步骤,具体包括:
采用基于文本情感分析技术对所述文本文字的数据进行情绪识别。
作为其中一种实施方式,所述根据所述关键信息生成得到对应的情绪图符的步骤之后,还包括:
将所述情绪图符提示给用户进行预览;
判断是否获取到用户的确认操作;
若获取到用户的确认操作,发送和/或存储所述情绪图符。
作为其中一种实施方式,所述根据所述关键信息生成得到对应的情绪图符的步骤,具体包括:
根据所述关键信息获取对应的情绪表达载体;
根据所述情绪表达载体生成得到对应的情绪图符。
作为其中一种实施方式,所述情绪表达载体为情绪图片、情绪文字、情绪语音或三者的任意组合。
作为其中一种实施方式:
当所述输入信息为肢体语言内容时,所述关键信息为眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合所构成的情绪动作信息;
当所述输入信息为语言内容时,所述关键信息为语句、语气、用词、场景或任意两种或以上组合所构成的情绪语音信息;
当所述输入信息为文本文字时,所述关键信息为语句、用词、场景、上下文或任意两种或以上组合所构成的情绪文本信息;
其中,所述情绪图符由所述眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合所构成的情绪动作信息,语句、语气、用词、场景或任意两种或以上组合所构成的情绪语音信息,和/或,语句、用词、场景、上下文或任意两种或以上组合所构成的情绪文本信息模拟所得到。
作为其中一种实施方式,所述情绪图符为用于沟通交流的包括图片、文字和/或语音的表情静态图、表情小视频、表情动态图。
作为其中一种实施方式,所述情绪图符在发送给接收方时,还用于根据接收方的点播动作产生互动效果。
为解决上述技术问题,本申请还提供一种用户智能设备,作为其中一种实施方式,所述用户智能设备包括处理器,所述处理器用于执行计算机程序,以实现如上所述的情绪图符处理方法。
本申请提供的用户智能设备及其情绪图符处理方法,用户智能设备获取用户的输入信息,根据所述输入信息对用户进行情绪识别,根据情绪识别的结果得到对应的关键信息,根据所述关键信息生成得到对应的情绪图符。本申请能够根据用户输入信息进行情绪识别,将情绪图片、文字或语言等生成对应的情绪图符,实现了多种输入途径的快捷输入效果,还可以实现对较长输入信息的情绪识别,满足了个性化需求,而且在一定程度上实现了人工智能。
上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1为本申请的情绪图符处理方法一实施方式的流程示意图。
图2为本申请用户智能设备一实施方式的模块示意图。
具体实施方式
为更进一步阐述本申请为达成预定申请目的所采取的技术手段及功效,以下结合附图及较佳实施例,对本申请详细说明如下。
通过具体实施方式的说明,当可对本申请为达成预定目的所采取的技术手段及效果得以更加深入且具体的了解,然而所附图式仅是提供参考与说明之用,并非用来对本申请加以限制。
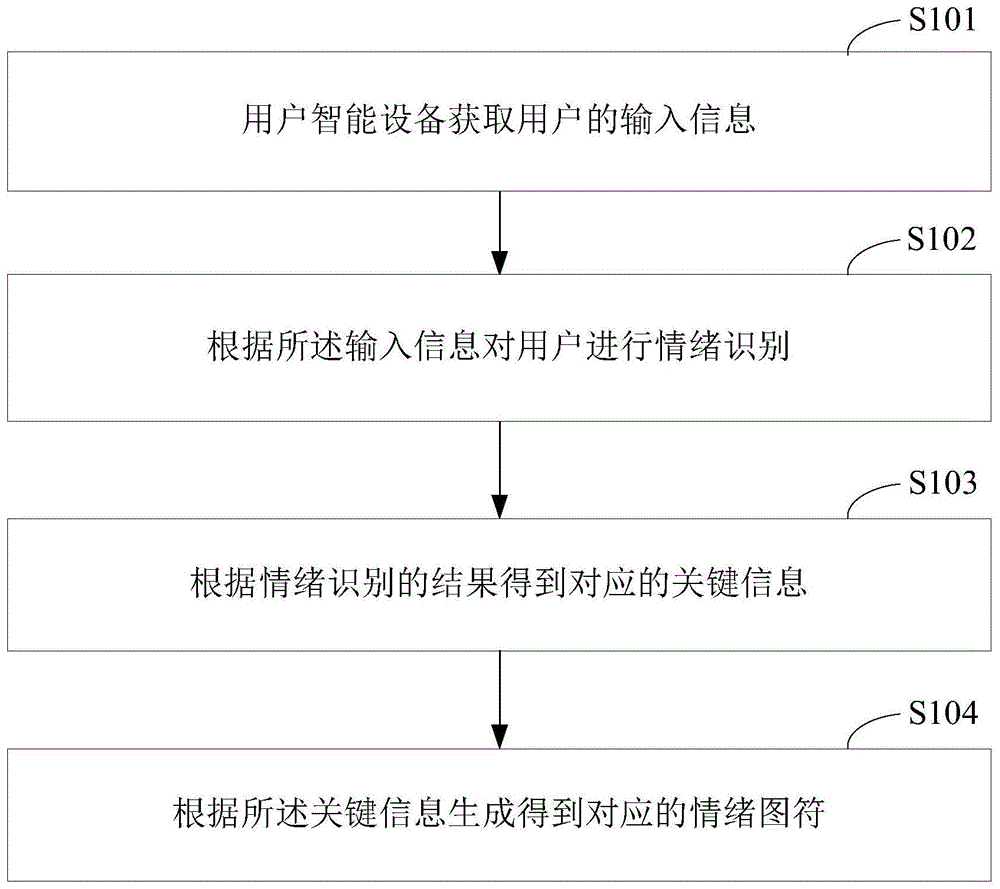
请参阅图1,图1为本申请的情绪图符处理方法一实施方式的流程示意图,本实施方式情绪图符处理方法可以应用到手机、笔记本电脑、平板电脑或者可穿戴设备等用户智能设备上。
需要说明的是,如图1所示,本实施方式所述的情绪图符处理方法可以包括但不限于如下几个步骤。
步骤s101,用户智能设备获取用户的输入信息。
步骤s102,根据所述输入信息对用户进行情绪识别。
步骤s103,根据情绪识别的结果得到对应的关键信息。
步骤s104,根据所述关键信息生成得到对应的情绪图符。
在本实施方式中,所述根据所述关键信息生成得到对应的情绪图符的步骤,具体包括:根据所述关键信息获取对应的情绪表达载体;根据所述情绪表达载体生成得到对应的情绪图符。
需要首先说明的是,本实施方式所述情绪表达载体可以为情绪图片、情绪文字、情绪语音或三者的任意组合。
在本实施方式中,当所述输入信息为肢体语言内容时,所述关键信息为眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合所构成的情绪动作信息;当所述输入信息为语言内容时,所述关键信息为语句、语气、用词、场景或任意两种或以上组合所构成的情绪语音信息;当所述输入信息为文本文字时,所述关键信息为语句、用词、场景、上下文或任意两种或以上组合所构成的情绪文本信息。其中,在一实施方式中,所述情绪图符由所述眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合所构成的情绪动作信息,语句、语气、用词、场景或任意两种或以上组合所构成的情绪语音信息,和/或,语句、用词、场景、上下文或任意两种或以上组合所构成的情绪文本信息模拟所得到。
需要说明的是,本实施方式所述情绪图符为用于沟通交流的包括图片、文字和/或语音的表情静态图、表情小视频、表情动态图。
此外,本实施方式所述情绪图符在发送给接收方时,还用于根据接收方的点播动作产生互动或应激反应效果。
其中,本实施方式所述的应激反应效果,指的是,比如情绪图符发给接收方后,显示为“生气”,而接收方对该情绪图符的不同位置点播时,能够产生不同的效果,比如如果是表示道歉的双击,则可以显示出“原谅你了”的应激反应;或者如果检测到接收方不作任何点播动作,则可以显示出“我很生气”、“我非常非常非常生气”的情绪加深、加强效果。
需要说明的是,本实施方式所述s101中用户智能设备获取用户的输入信息的步骤,具体可以包括:用户智能设备通过摄像装置拍摄用户的肢体语言内容;对所述肢体语言内容进行预处理以作为所述输入信息。
举例而言,用户智能设备可以通过前置、后置等多个摄像头拍摄用户的肢体语言内容,其还可以进行连续拍摄、三维拍摄而进行对比筛选。
进一步而言,本实施方式所述对所述肢体语言内容进行预处理以作为所述输入信息的步骤,具体可以包括:对所述肢体语言内容进行动作识别;根据动作识别的结果获取动作幅度变化值大于预设阈值的目标部位;将所述目标部位的动作作为所述输入信息。
举例而言,比如用户想表达惊讶,则动作幅度变化值最大的一般是眼睛或嘴巴,比如眼睛睁得非常大,或者嘴巴张得非常大,但是脸部等可能没有明显变化,因此,最能表达情绪的会是眼睛或者嘴巴的动作幅度。
当然,考虑到用户可以通过多种动作配合而表达不同的情绪,本实施方式所述肢体语言内容为眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合的动作。
本实施方式根据所述输入信息对用户进行情绪识别,具体可以包括:首先是对于人体的关节点进行建模,把人体看作是一个有着内在联系的刚性系统,它包含骨骼以及关节点,骨骼和关节点的相对运动构成了人体姿态的变化,即平时所说的描述动作,在人体众多关节点中,根据对情绪影响的轻重,忽略手指与脚趾,将人体的脊柱抽象为颈、胸和腹部三个关节,总结出一个人体模型,其中上半身包括头、颈、胸部、腹部、两个大臂和两个小臂,而下半身包括两个大腿、两个小腿;对于选择的多种情绪状态,分别选取了人体正常情况下进行每种情绪状态的表达,并对肢体反应进行详细分析;由于人体被抽象成为了刚体模型,首先是人体重心的移动,分为向前、向后和自然态;除了重心的移动之外,其次是关节点的转动,人体发生动作变化,并且和情绪相关的关节点包括头、胸腔、肩膀和肘部,对应的动作为头部的弯曲、胸腔的转动、上臂的摆动和伸展方向,以及肘部的弯曲,这些参数结合上重心的移动,总共包括了七个自由度的移动,表达出一个人上半身的动作。通过这种方式,可以根据用户的肢体语言内容进行情绪识别。
比如,用户通过前置或后置摄像头拍摄的包含面部的照片或视频,当用户完成拍摄时,采集用户的面部图像数据;其中,采集动作可以发生于面部动作最大最明显时,其可以通过动作识别进行自动判断。
接着,本实施方式采用基于图像情感分析技术对面部图像进行情绪识别并输出情绪结果。本实施方式所述情绪结果可以包含两层判定:第一层判定为是否包含情绪信息,如果不包含,则情绪结果为无情绪信息;如果第一层判定为包含情绪信息,则进入第二层判定,即判定为某一种情绪类型,其中,情绪类型包括且不限于开心、悲伤、郁闷、愤怒、害怕、紧张等。
本实施方式可以根据情绪结果而判断是否获取对应的情绪表达载体,当情绪结果为无情绪时,不进行情绪图符的生成;当情绪结果为某一种情绪类型时,将同时与已有情绪图符、预设的文字文本库进行比对,给用户提供此种情绪类型相关的情绪图符。
进一步而言,在筛选出与某种情绪类型相关的情绪图符的基础上,用户选择想要使用的情绪图符添加至面部照片或包含面部的视频中,即可生成新的情绪图符预览,此时,用户可以选择保存此新的情绪图符至已有的情绪图符集合中,也可以通过发送消息立即使用。
需要说明的是,本实施方式所述s101中用户智能设备获取用户的输入信息的步骤,具体还可以包括:用户智能设备通过麦克风获取用户的语音内容;对所述语言内容进行预处理以作为所述输入信息。
举例而言,用户在使用设备时,可以直接进行语音输入“很烦哦”,此时,本实施方式可以通过麦克风获取“很烦哦”作为输入信息。
对应地,本实施方式所述s102中根据所述输入信息对用户进行情绪识别的步骤,具体可以包括:采用基于语音情感分析技术对所述语音内容的数据进行情绪识别。
比如,用户通过麦克风在语音消息输入框中输入的语音信息,当用户完成输入时,采集用户输入的语音数据;接着,采用基于语音情感分析技术对语音数据进行情绪识别并输出情绪结果。其中,本实施方式所述情绪结果可以包含两层判定:第一层判定为是否包含情绪信息,如果不包含,则情绪结果为无情绪信息;如果第一层判定为包含情绪信息,则进入第二层判定,即判定为某一种情绪类型,其中,情绪类型包括且不限于开心、悲伤、郁闷、愤怒、害怕、紧张等。
接着,本实施方式可以根据情绪结果而判断是否获取对应的情绪表达载体,当情绪结果为无情绪时,不进行情绪图符的生成;当情绪结果为某一种情绪类型时,通过与已有情绪图符进行比对,给用户提供此种情绪类型相关的情绪图符;最后,可以在已有情绪图符的基础上生成情绪图符,提供给用户预览并进行选择后使用。
需要说明的是,本实施方式所述s101中用户智能设备获取用户的输入信息的步骤,具体可以包括:用户智能设备通过文本消息输入框获取用户的文本文字;对所述文本文字进行预处理以作为所述输入信息。
对应地,本实施方式所述s102中根据所述输入信息对用户进行情绪识别的步骤,具体可以包括:采用基于文本情感分析技术对所述文本文字的数据进行情绪识别。
比如,用户在文本消息输入框中输入的文字文本信息,当用户完成输入时,采集用户输入的文字文本数据;接着,采用基于文本情感分析技术对文字文本进行情绪识别并输出情绪结果。
情绪结果可以包含两层判定:第一层判定为是否包含情绪信息,如果不包含,则情绪结果为无情绪信息;如果第一层判定为包含情绪信息,则进入第二层判定,即判定为某一种情绪类型,在本实施方式中,情绪类型可以包括且不限于开心、悲伤、郁闷、愤怒、害怕、紧张等。
进一步而言,本实施方式基于情绪结果判断是否获取对应的情绪表达载体。比如,当情绪结果为无情绪时,不进行情绪图符的生成;当情绪结果为某一种情绪类型时,通过与已有情绪图符进行比对,给用户提供此种情绪类型相关的情绪图符。例如,当情绪结果为“生气”,通过比对,将基于已有情绪图符生成“生气”情绪图符。最后,可以在已有情绪图符的基础上生成情绪图符结果,提供给用户预览并进行选择后使用。
值得一提的是,本实施方式所述根据所述关键信息生成得到对应的情绪图符的步骤之后,还可以包括:将所述情绪图符提示给用户进行预览;判断是否获取到用户的确认操作;若获取到用户的确认操作,发送和/或存储所述情绪图符。
例如,当情绪结果为“生气”,通过比对,将筛选出已有情绪图符中所有的“生气”表情,且筛选出预设的文字/文本库中所有的“生气”有关的内容如“本宝宝怒了”。用户可以直接通过触摸点击或鼠标点击来选择情绪图符或者文字/文本内容,选择后即可添加至原面部照片或包含面部的视频中,从而生成富有表情的情绪图符。
需要说明的是,本实施方式情绪图符处理方法处理得到的情绪图符,可以通过app第三方应用发送给第三方进行沟通交互,也可以存储在本地、云端。
请接着参阅图2,本申请还提供一种用户智能设备,作为其中一种实施方式,所述用户智能设备包括处理器21,所述处理器21用于执行计算机程序,以实现如上所述的情绪图符处理方法。
具体而言,所述处理器21用于获取用户的输入信息;所述处理器21用于根据所述输入信息对用户进行情绪识别;所述处理器21用于根据情绪识别的结果得到对应的关键信息;所述处理器21用于根据所述关键信息生成得到对应的情绪图符。
需要说明的是,本实施方式所述处理器21用于获取用户的输入信息,具体可以包括:所述处理器21用于通过摄像装置拍摄用户的肢体语言内容;对所述肢体语言内容进行预处理以作为所述输入信息。
举例而言,所述处理器21用于可以通过前置、后置等多个摄像头拍摄用户的肢体语言内容,其还可以进行连续拍摄、三维拍摄而进行对比筛选。
进一步而言,本实施方式所述处理器21用于对所述肢体语言内容进行预处理以作为所述输入信息,具体可以包括:对所述肢体语言内容进行动作识别;根据动作识别的结果获取动作幅度变化值大于预设阈值的目标部位;将所述目标部位的动作作为所述输入信息。
举例而言,比如用户想表达惊讶,则动作幅度变化值最大的一般是眼睛或嘴巴,比如眼睛睁得非常大,或者嘴巴张得非常大,但是脸部等可能没有明显变化,因此,最能表达情绪的会是眼睛或者嘴巴的动作幅度。
当然,考虑到用户可以通过多种动作配合而表达不同的情绪,本实施方式所述肢体语言内容为眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合的动作。
本实施方式所述处理器21用于根据所述输入信息对用户进行情绪识别,具体可以包括:首先是对于人体的关节点进行建模,把人体看作是一个有着内在联系的刚性系统,它包含骨骼以及关节点,骨骼和关节点的相对运动构成了人体姿态的变化,即平时所说的描述动作,在人体众多关节点中,根据对情绪影响的轻重,忽略手指与脚趾,将人体的脊柱抽象为颈、胸和腹部三个关节,总结出一个人体模型,其中上半身包括头、颈、胸部、腹部、两个大臂和两个小臂,而下半身包括两个大腿、两个小腿;对于选择的多种情绪状态,分别选取了人体正常情况下进行每种情绪状态的表达,并对肢体反应进行详细分析;由于人体被抽象成为了刚体模型,首先是人体重心的移动,分为向前、向后和自然态;除了重心的移动之外,其次是关节点的转动,人体发生动作变化,并且和情绪相关的关节点包括头、胸腔、肩膀和肘部,对应的动作为头部的弯曲、胸腔的转动、上臂的摆动和伸展方向,以及肘部的弯曲,这些参数结合上重心的移动,总共包括了七个自由度的移动,表达出一个人上半身的动作。通过这种方式,可以根据用户的肢体语言内容进行情绪识别。
比如,用户通过前置或后置摄像头拍摄的包含面部的照片或视频,当用户完成拍摄时,采集用户的面部图像数据;其中,采集动作可以发生于面部动作最大最明显时,其可以通过动作识别进行自动判断。
接着,本实施方式可以采用基于图像情感分析技术对面部图像进行情绪识别并输出情绪结果。本实施方式所述情绪结果可以包含两层判定:第一层判定为是否包含情绪信息,如果不包含,则情绪结果为无情绪信息;如果第一层判定为包含情绪信息,则进入第二层判定,即判定为某一种情绪类型,其中,情绪类型包括且不限于开心、悲伤、郁闷、愤怒、害怕、紧张等。
本实施方式可以根据情绪结果而判断是否获取对应的情绪表达载体,当情绪结果为无情绪时,不进行情绪图符的生成;当情绪结果为某一种情绪类型时,将同时与已有情绪图符、预设的文字文本库进行比对,给用户提供此种情绪类型相关的情绪图符。
进一步而言,在筛选出与某种情绪类型相关的情绪图符的基础上,用户选择想要使用的情绪图符添加至面部照片或包含面部的视频中,即可生成新的情绪图符预览,此时,用户可以选择保存此新的情绪图符至已有的情绪图符集合中,也可以通过发送消息立即使用。
需要说明的是,本实施方式所述处理器21用于获取用户的输入信息,具体还可以包括:所述处理器21用于通过麦克风获取用户的语音内容;对所述语言内容进行预处理以作为所述输入信息。
举例而言,用户在使用设备时,可以直接进行语音输入“很烦哦”,此时,本实施方式可以通过麦克风获取“很烦哦”作为输入信息。
对应地,本实施方式所述处理器21用于根据所述输入信息对用户进行情绪识别,具体可以包括:所述处理器21用于采用基于语音情感分析技术对所述语音内容的数据进行情绪识别。
比如,用户通过麦克风在语音消息输入框中输入的语音信息,当用户完成输入时,采集用户输入的语音数据;接着,采用基于语音情感分析技术对语音数据进行情绪识别并输出情绪结果。其中,本实施方式所述情绪结果可以包含两层判定:第一层判定为是否包含情绪信息,如果不包含,则情绪结果为无情绪信息;如果第一层判定为包含情绪信息,则进入第二层判定,即判定为某一种情绪类型,其中,情绪类型包括且不限于开心、悲伤、郁闷、愤怒、害怕、紧张等。
接着,本实施方式可以根据情绪结果而判断是否获取对应的情绪表达载体,当情绪结果为无情绪时,不进行情绪图符的生成;当情绪结果为某一种情绪类型时,通过与已有情绪图符进行比对,给用户提供此种情绪类型相关的情绪图符;最后,可以在已有情绪图符的基础上生成情绪图符,提供给用户预览并进行选择后使用。
需要说明的是,本实施方式所述处理器21用于获取用户的输入信息,具体可以包括:所述处理器21用于通过文本消息输入框获取用户的文本文字;对所述文本文字进行预处理以作为所述输入信息。
对应地,本实施方式所述处理器21用于据所述输入信息对用户进行情绪识别,具体可以包括:所述处理器21用于采用基于文本情感分析技术对所述文本文字的数据进行情绪识别。
比如,用户在文本消息输入框中输入的文字文本信息,当用户完成输入时,采集用户输入的文字文本数据;接着,所述处理器21用于采用基于文本情感分析技术对文字文本进行情绪识别并输出情绪结果。
情绪结果可以包含两层判定:第一层判定为是否包含情绪信息,如果不包含,则情绪结果为无情绪信息;如果第一层判定为包含情绪信息,则进入第二层判定,即判定为某一种情绪类型,在本实施方式中,情绪类型可以包括且不限于开心、悲伤、郁闷、愤怒、害怕、紧张等。
进一步而言,本实施方式基于情绪结果判断是否获取对应的情绪表达载体。比如,当情绪结果为无情绪时,不进行情绪图符的生成;当情绪结果为某一种情绪类型时,通过与已有情绪图符进行比对,给用户提供此种情绪类型相关的情绪图符。例如,当情绪结果为“生气”,通过比对,将基于已有情绪图符生成“生气”情绪图符。最后,可以在已有情绪图符的基础上生成情绪图符结果,提供给用户预览并进行选择后使用。
在本实施方式中,当所述输入信息为肢体语言内容时,所述关键信息为眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合所构成的情绪动作信息;当所述输入信息为语言内容时,所述关键信息为语句、语气、用词、场景或任意两种或以上组合所构成的情绪语音信息;当所述输入信息为文本文字时,所述关键信息为语句、用词、场景、上下文或任意两种或以上组合所构成的情绪文本信息。优选地,所述情绪图符由所述眼睛、嘴巴、手部、头部、躯干、脚部或任意两种或以上组合所构成的情绪动作信息,语句、语气、用词、场景或任意两种或以上组合所构成的情绪语音信息,和/或,语句、用词、场景、上下文或任意两种或以上组合所构成的情绪文本信息模拟所得到
值得一提的是,本实施方式所述处理器21用于根据所述关键信息生成得到对应的情绪图符之后,还可用于将所述情绪图符提示给用户进行预览;判断是否获取到用户的确认操作;若获取到用户的确认操作,发送和/或存储所述情绪图符。
例如,当情绪结果为“生气”,通过比对,将筛选出已有情绪图符中所有的“生气”表情,且筛选出预设的文字/文本库中所有的“生气”有关的内容如“本宝宝怒了”。用户可以直接通过触摸点击或鼠标点击来选择情绪图符或者文字/文本内容,选择后即可添加至原面部照片或包含面部的视频中,从而生成富有表情的情绪图符。
需要说明的是,本实施方式情绪图符处理方法处理得到的情绪图符,可以通过app第三方应用发送给第三方进行沟通交互,也可以存储在本地、云端。
此外,本申请还提供一种存储介质,所述存储介质存储有计算机程序,所述计算机程序在被处理器执行时,用于实现如上实施方式所述的情绪图符处理方法。
以上所述,仅是本申请的较佳实施例而已,并非对本申请作任何形式上的限制,虽然本申请已以较佳实施例揭露如上,然而并非用以限定本申请,任何熟悉本专业的技术人员,在不脱离本申请技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本申请技术方案内容,依据本申请的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本申请技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!